AdaCLIP: Adapting CLIP with Hybrid Learnable Prompts for Zero-Shot Anomaly Detection

0

Sign in to get full access
Overview
- This paper provides guidelines for authors submitting papers to the European Conference on Computer Vision (ECCV).
- It covers the initial submission process, formatting and style requirements, and review and camera-ready submission guidelines.
- The guidelines aim to ensure a consistent and high-quality submission process for the conference.
Plain English Explanation
The paper outlines the instructions for researchers who want to submit their work to the ECCV conference. It explains the different steps they need to follow, such as how to format their paper, the deadlines they need to meet, and what information they need to include.
The guidelines are designed to make the submission process as straightforward as possible for authors, while also helping the conference organizers review the papers in a consistent way. For example, the paper specifies the font size, margin requirements, and other formatting details that authors must follow.
By providing clear instructions, the guidelines aim to ensure that all submissions to ECCV are presented in a similar manner, making it easier for the reviewers to evaluate the research. This helps maintain the high standards and quality of the conference.
Technical Explanation
The paper first introduces the ECCV conference and the purpose of the author guidelines. It then outlines the initial submission process, including details on the paper format, length, and content requirements. This includes specifications for the title, author list, abstract, body text, references, and supplementary material.
The guidelines also cover formatting and style rules, such as the font, margin sizes, and use of figures and tables. There are strict requirements around the layout and structure of the paper to ensure a consistent appearance across all submissions.
The paper then describes the review and camera-ready submission process. This includes information on the timeline, rebuttal period, and final revisions authors must make based on reviewer feedback.
Throughout the document, the authors provide clarification and examples to help authors understand and follow the guidelines correctly. The goal is to streamline the submission process and improve the overall quality and consistency of papers accepted to ECCV.
Critical Analysis
The guidelines provide a comprehensive set of instructions that aim to standardize the submission and review process for ECCV. This is important to ensure fairness and quality control, as the conference receives a large number of papers each year.
However, the strict formatting rules could pose a challenge for some authors, especially those new to academic publishing. The guidelines may need to strike a balance between maintaining high standards and being overly prescriptive.
Additionally, the guidelines do not address potential issues around originality, ethics, or reproducibility - aspects that are crucial for high-quality computer vision research. These could be areas for the conference organizers to consider expanding on in future iterations of the guidelines.
Overall, the guidelines seem well-designed to facilitate an efficient and organized submission and review process for ECCV. With clear instructions and examples, they provide authors with the necessary information to prepare their papers for consideration.
Conclusion
The ECCV author guidelines outline the requirements and procedures for submitting research papers to the prestigious computer vision conference. By standardizing the submission format and review process, the guidelines help ensure a consistent level of quality across all accepted papers.
The detailed instructions cover everything from initial paper formatting to the camera-ready submission stage. While the strict rules may pose some challenges for authors, the guidelines ultimately support the conference's goal of publishing cutting-edge computer vision research.
As the field of computer vision continues to rapidly evolve, these types of guidelines will remain important for maintaining the integrity and reputation of leading academic venues like ECCV.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AdaCLIP: Adapting CLIP with Hybrid Learnable Prompts for Zero-Shot Anomaly Detection
Yunkang Cao, Jiangning Zhang, Luca Frittoli, Yuqi Cheng, Weiming Shen, Giacomo Boracchi
Zero-shot anomaly detection (ZSAD) targets the identification of anomalies within images from arbitrary novel categories. This study introduces AdaCLIP for the ZSAD task, leveraging a pre-trained vision-language model (VLM), CLIP. AdaCLIP incorporates learnable prompts into CLIP and optimizes them through training on auxiliary annotated anomaly detection data. Two types of learnable prompts are proposed: static and dynamic. Static prompts are shared across all images, serving to preliminarily adapt CLIP for ZSAD. In contrast, dynamic prompts are generated for each test image, providing CLIP with dynamic adaptation capabilities. The combination of static and dynamic prompts is referred to as hybrid prompts, and yields enhanced ZSAD performance. Extensive experiments conducted across 14 real-world anomaly detection datasets from industrial and medical domains indicate that AdaCLIP outperforms other ZSAD methods and can generalize better to different categories and even domains. Finally, our analysis highlights the importance of diverse auxiliary data and optimized prompts for enhanced generalization capacity. Code is available at https://github.com/caoyunkang/AdaCLIP.
Read more7/23/2024
0
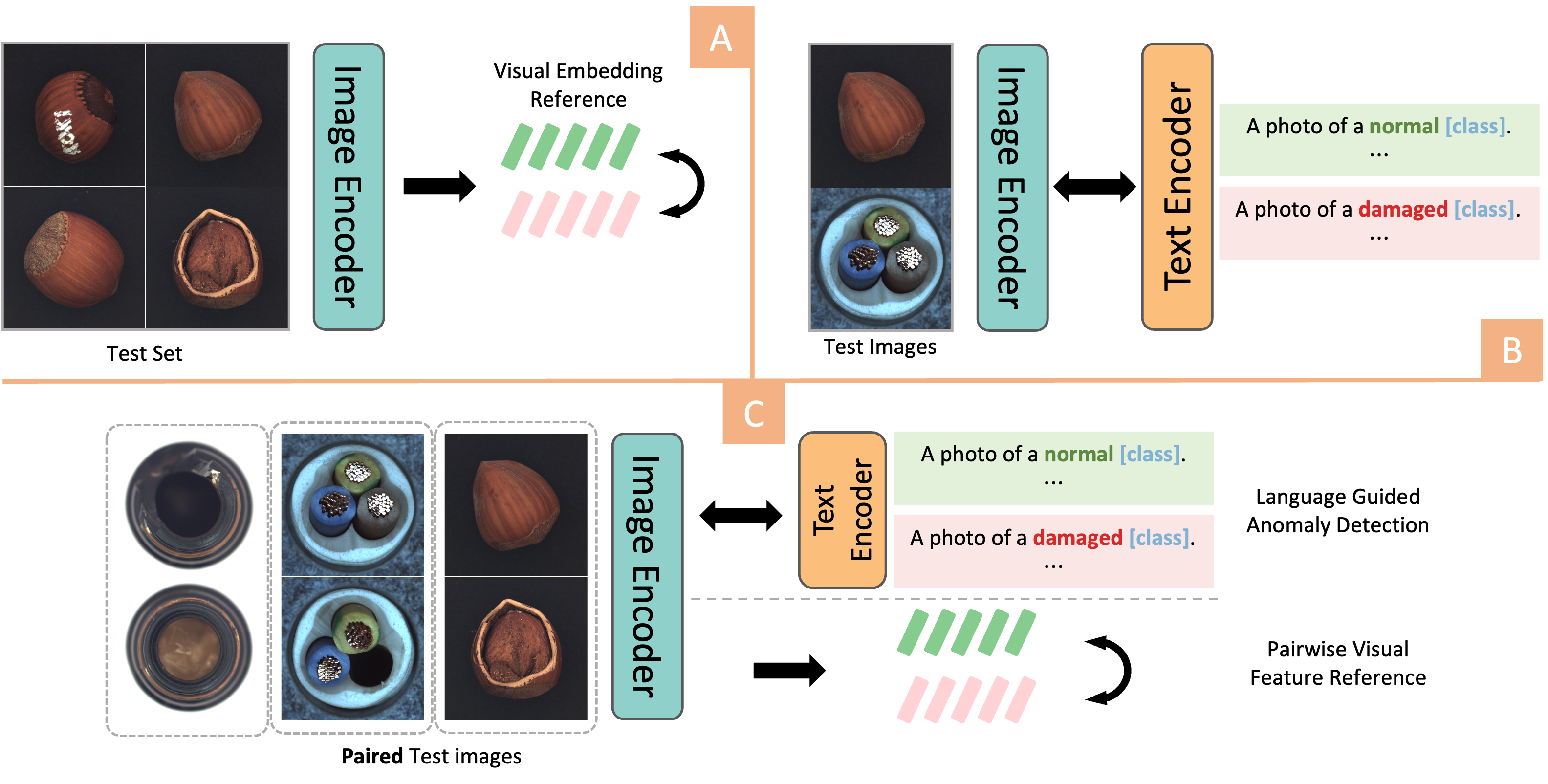
Dual-Image Enhanced CLIP for Zero-Shot Anomaly Detection
Zhaoxiang Zhang, Hanqiu Deng, Jinan Bao, Xingyu Li
Image Anomaly Detection has been a challenging task in Computer Vision field. The advent of Vision-Language models, particularly the rise of CLIP-based frameworks, has opened new avenues for zero-shot anomaly detection. Recent studies have explored the use of CLIP by aligning images with normal and prompt descriptions. However, the exclusive dependence on textual guidance often falls short, highlighting the critical importance of additional visual references. In this work, we introduce a Dual-Image Enhanced CLIP approach, leveraging a joint vision-language scoring system. Our methods process pairs of images, utilizing each as a visual reference for the other, thereby enriching the inference process with visual context. This dual-image strategy markedly enhanced both anomaly classification and localization performances. Furthermore, we have strengthened our model with a test-time adaptation module that incorporates synthesized anomalies to refine localization capabilities. Our approach significantly exploits the potential of vision-language joint anomaly detection and demonstrates comparable performance with current SOTA methods across various datasets.
Read more5/9/2024

0
VCP-CLIP: A visual context prompting model for zero-shot anomaly segmentation
Zhen Qu, Xian Tao, Mukesh Prasad, Fei Shen, Zhengtao Zhang, Xinyi Gong, Guiguang Ding
Recently, large-scale vision-language models such as CLIP have demonstrated immense potential in zero-shot anomaly segmentation (ZSAS) task, utilizing a unified model to directly detect anomalies on any unseen product with painstakingly crafted text prompts. However, existing methods often assume that the product category to be inspected is known, thus setting product-specific text prompts, which is difficult to achieve in the data privacy scenarios. Moreover, even the same type of product exhibits significant differences due to specific components and variations in the production process, posing significant challenges to the design of text prompts. In this end, we propose a visual context prompting model (VCP-CLIP) for ZSAS task based on CLIP. The insight behind VCP-CLIP is to employ visual context prompting to activate CLIP's anomalous semantic perception ability. In specific, we first design a Pre-VCP module to embed global visual information into the text prompt, thus eliminating the necessity for product-specific prompts. Then, we propose a novel Post-VCP module, that adjusts the text embeddings utilizing the fine-grained features of the images. In extensive experiments conducted on 10 real-world industrial anomaly segmentation datasets, VCP-CLIP achieved state-of-the-art performance in ZSAS task. The code is available at https://github.com/xiaozhen228/VCP-CLIP.
Read more7/18/2024
👁️
0
AD-CLIP: Adapting Domains in Prompt Space Using CLIP
Mainak Singha, Harsh Pal, Ankit Jha, Biplab Banerjee
Although deep learning models have shown impressive performance on supervised learning tasks, they often struggle to generalize well when the training (source) and test (target) domains differ. Unsupervised domain adaptation (DA) has emerged as a popular solution to this problem. However, current DA techniques rely on visual backbones, which may lack semantic richness. Despite the potential of large-scale vision-language foundation models like CLIP, their effectiveness for DA has yet to be fully explored. To address this gap, we introduce textsc{AD-CLIP}, a domain-agnostic prompt learning strategy for CLIP that aims to solve the DA problem in the prompt space. We leverage the frozen vision backbone of CLIP to extract both image style (domain) and content information, which we apply to learn prompt tokens. Our prompts are designed to be domain-invariant and class-generalizable, by conditioning prompt learning on image style and content features simultaneously. We use standard supervised contrastive learning in the source domain, while proposing an entropy minimization strategy to align domains in the embedding space given the target domain data. We also consider a scenario where only target domain samples are available during testing, without any source domain data, and propose a cross-domain style mapping network to hallucinate domain-agnostic tokens. Our extensive experiments on three benchmark DA datasets demonstrate the effectiveness of textsc{AD-CLIP} compared to existing literature. Code is available at url{https://github.com/mainaksingha01/AD-CLIP}
Read more9/17/2024