VCP-CLIP: A visual context prompting model for zero-shot anomaly segmentation

0

Sign in to get full access
Overview
- The paper proposes a visual context prompting (VCP) model based on CLIP, a language-image contrastive learning model, for zero-shot anomaly segmentation.
- VCP-CLIP leverages the semantic understanding of the CLIP model to identify anomalies in images without needing labeled training data for the specific anomaly classes.
- The model uses visual context prompts to guide the CLIP model to identify and segment anomalies in images, achieving strong performance on several benchmark datasets.
Plain English Explanation
VCP-CLIP is a machine learning model that can identify and segment unusual or abnormal objects in images, even if it has never seen examples of those specific types of anomalies before. It does this by building on the Cascade-CLIP and Dual-Image-Enhanced CLIP models, which use the power of CLIP to understand the relationship between images and language.
The key insight of VCP-CLIP is that by providing the model with visual "prompts" that describe the kind of anomaly it should look for, it can leverage CLIP's language understanding to identify those anomalies in new images, even if it has never seen examples of that specific type of anomaly before. This "zero-shot" capability is valuable because it avoids the need to collect and label large datasets of anomaly examples, which can be time-consuming and expensive.
VCP-CLIP demonstrated strong performance on several benchmark datasets for anomaly segmentation, showing that it can effectively identify and outline unusual objects or events in images in a generalizable way. This could have applications in fields like medical imaging, industrial inspection, and security monitoring, where being able to quickly detect novel anomalies is important.
Technical Explanation
The VCP-CLIP model builds on the CLIP vision-language model, which learns a joint embedding space that aligns images and their textual descriptions. VCP-CLIP extends CLIP by introducing visual context prompts that guide the model to identify and segment anomalies in images.
The key components of VCP-CLIP are:
- Visual Prompt Encoder: This module encodes visual prompts, such as sketches or segmentation maps, that describe the type of anomaly the model should look for.
- Prompt-Guided Anomaly Segmentation: The visual prompt is combined with the input image and fed into the CLIP model. The CLIP model then outputs a segmentation map highlighting the anomalous regions of the image.
- Training: VCP-CLIP is trained in a self-supervised manner using the Solution-Language Enhanced Image approach, which generates visual prompts from textual descriptions of anomalies.
The authors evaluate VCP-CLIP on several anomaly segmentation datasets, including MVTec AD, PatchCore, and CelebA-HQ, and show that it outperforms state-of-the-art zero-shot anomaly segmentation methods. The model's ability to generalize to new anomaly types without needing labeled training data is a key strength.
Critical Analysis
The paper presents a novel and promising approach to zero-shot anomaly segmentation, leveraging the power of CLIP to identify anomalies without needing labeled training data. However, there are a few potential limitations and areas for further research:
- Prompt Quality: The performance of VCP-CLIP is highly dependent on the quality and relevance of the visual prompts used. Generating effective prompts automatically could be challenging, and the model's performance may be sensitive to the choice of prompts.
- Computational Efficiency: The paper does not provide detailed information on the computational cost and inference time of VCP-CLIP, which could be an important consideration for real-world applications.
- Robustness to Anomaly Types: While VCP-CLIP demonstrates strong performance on the evaluated datasets, it would be valuable to assess its robustness to a wider range of anomaly types and scenarios, including more complex or subtle anomalies.
Overall, the VCP-CLIP model represents an interesting and promising approach to zero-shot anomaly segmentation that could have significant practical applications. Further research to address the potential limitations and explore the model's broader capabilities would be valuable.
Conclusion
The VCP-CLIP model presented in this paper offers a novel solution for zero-shot anomaly segmentation, leveraging the power of CLIP's vision-language understanding to identify and outline anomalous regions in images without needing labeled training data. By introducing visual context prompts, the model can effectively guide the CLIP model to detect a wide range of anomalies, as demonstrated by its strong performance on several benchmark datasets.
This research represents an important step forward in the field of anomaly detection, with potential applications in areas such as medical imaging, industrial inspection, and security monitoring. By reducing the need for extensive labeled data, VCP-CLIP could make anomaly detection more accessible and practical in real-world settings. Further research to address the model's limitations and explore its broader capabilities could lead to even more impactful advancements in this field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VCP-CLIP: A visual context prompting model for zero-shot anomaly segmentation
Zhen Qu, Xian Tao, Mukesh Prasad, Fei Shen, Zhengtao Zhang, Xinyi Gong, Guiguang Ding
Recently, large-scale vision-language models such as CLIP have demonstrated immense potential in zero-shot anomaly segmentation (ZSAS) task, utilizing a unified model to directly detect anomalies on any unseen product with painstakingly crafted text prompts. However, existing methods often assume that the product category to be inspected is known, thus setting product-specific text prompts, which is difficult to achieve in the data privacy scenarios. Moreover, even the same type of product exhibits significant differences due to specific components and variations in the production process, posing significant challenges to the design of text prompts. In this end, we propose a visual context prompting model (VCP-CLIP) for ZSAS task based on CLIP. The insight behind VCP-CLIP is to employ visual context prompting to activate CLIP's anomalous semantic perception ability. In specific, we first design a Pre-VCP module to embed global visual information into the text prompt, thus eliminating the necessity for product-specific prompts. Then, we propose a novel Post-VCP module, that adjusts the text embeddings utilizing the fine-grained features of the images. In extensive experiments conducted on 10 real-world industrial anomaly segmentation datasets, VCP-CLIP achieved state-of-the-art performance in ZSAS task. The code is available at https://github.com/xiaozhen228/VCP-CLIP.
Read more7/18/2024
🛸
0
Cascade-CLIP: Cascaded Vision-Language Embeddings Alignment for Zero-Shot Semantic Segmentation
Yunheng Li, ZhongYu Li, Quansheng Zeng, Qibin Hou, Ming-Ming Cheng
Pre-trained vision-language models, e.g., CLIP, have been successfully applied to zero-shot semantic segmentation. Existing CLIP-based approaches primarily utilize visual features from the last layer to align with text embeddings, while they neglect the crucial information in intermediate layers that contain rich object details. However, we find that directly aggregating the multi-level visual features weakens the zero-shot ability for novel classes. The large differences between the visual features from different layers make these features hard to align well with the text embeddings. We resolve this problem by introducing a series of independent decoders to align the multi-level visual features with the text embeddings in a cascaded way, forming a novel but simple framework named Cascade-CLIP. Our Cascade-CLIP is flexible and can be easily applied to existing zero-shot semantic segmentation methods. Experimental results show that our simple Cascade-CLIP achieves superior zero-shot performance on segmentation benchmarks, like COCO-Stuff, Pascal-VOC, and Pascal-Context. Our code is available at: https://github.com/HVision-NKU/Cascade-CLIP
Read more6/7/2024

0
AdaCLIP: Adapting CLIP with Hybrid Learnable Prompts for Zero-Shot Anomaly Detection
Yunkang Cao, Jiangning Zhang, Luca Frittoli, Yuqi Cheng, Weiming Shen, Giacomo Boracchi
Zero-shot anomaly detection (ZSAD) targets the identification of anomalies within images from arbitrary novel categories. This study introduces AdaCLIP for the ZSAD task, leveraging a pre-trained vision-language model (VLM), CLIP. AdaCLIP incorporates learnable prompts into CLIP and optimizes them through training on auxiliary annotated anomaly detection data. Two types of learnable prompts are proposed: static and dynamic. Static prompts are shared across all images, serving to preliminarily adapt CLIP for ZSAD. In contrast, dynamic prompts are generated for each test image, providing CLIP with dynamic adaptation capabilities. The combination of static and dynamic prompts is referred to as hybrid prompts, and yields enhanced ZSAD performance. Extensive experiments conducted across 14 real-world anomaly detection datasets from industrial and medical domains indicate that AdaCLIP outperforms other ZSAD methods and can generalize better to different categories and even domains. Finally, our analysis highlights the importance of diverse auxiliary data and optimized prompts for enhanced generalization capacity. Code is available at https://github.com/caoyunkang/AdaCLIP.
Read more7/23/2024
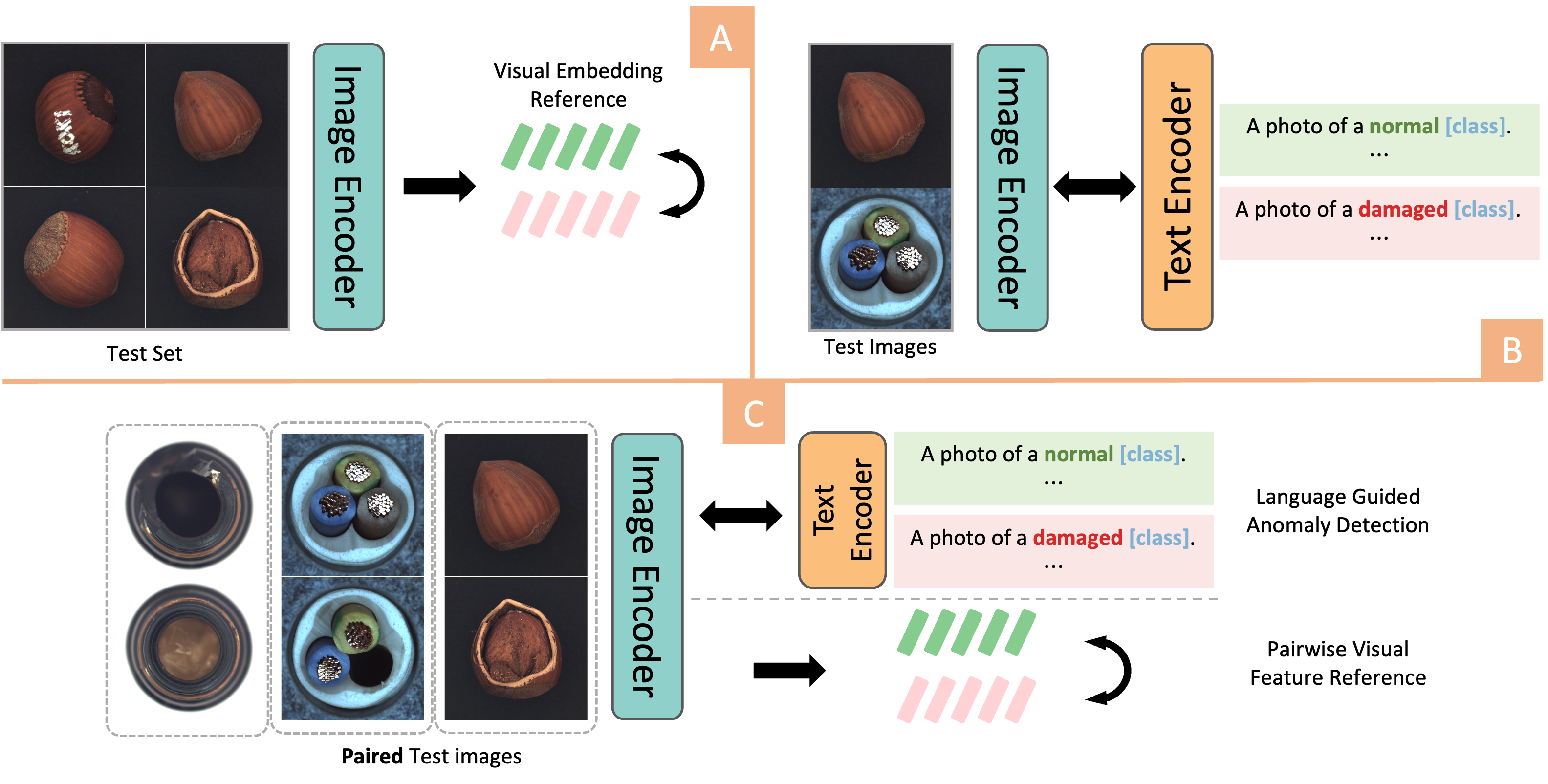
0
Dual-Image Enhanced CLIP for Zero-Shot Anomaly Detection
Zhaoxiang Zhang, Hanqiu Deng, Jinan Bao, Xingyu Li
Image Anomaly Detection has been a challenging task in Computer Vision field. The advent of Vision-Language models, particularly the rise of CLIP-based frameworks, has opened new avenues for zero-shot anomaly detection. Recent studies have explored the use of CLIP by aligning images with normal and prompt descriptions. However, the exclusive dependence on textual guidance often falls short, highlighting the critical importance of additional visual references. In this work, we introduce a Dual-Image Enhanced CLIP approach, leveraging a joint vision-language scoring system. Our methods process pairs of images, utilizing each as a visual reference for the other, thereby enriching the inference process with visual context. This dual-image strategy markedly enhanced both anomaly classification and localization performances. Furthermore, we have strengthened our model with a test-time adaptation module that incorporates synthesized anomalies to refine localization capabilities. Our approach significantly exploits the potential of vision-language joint anomaly detection and demonstrates comparable performance with current SOTA methods across various datasets.
Read more5/9/2024