AdaGossip: Adaptive Consensus Step-size for Decentralized Deep Learning with Communication Compression
2404.05919
0
0

Abstract
Decentralized learning is crucial in supporting on-device learning over large distributed datasets, eliminating the need for a central server. However, the communication overhead remains a major bottleneck for the practical realization of such decentralized setups. To tackle this issue, several algorithms for decentralized training with compressed communication have been proposed in the literature. Most of these algorithms introduce an additional hyper-parameter referred to as consensus step-size which is tuned based on the compression ratio at the beginning of the training. In this work, we propose AdaGossip, a novel technique that adaptively adjusts the consensus step-size based on the compressed model differences between neighboring agents. We demonstrate the effectiveness of the proposed method through an exhaustive set of experiments on various Computer Vision datasets (CIFAR-10, CIFAR-100, Fashion MNIST, Imagenette, and ImageNet), model architectures, and network topologies. Our experiments show that the proposed method achieves superior performance ($0-2%$ improvement in test accuracy) compared to the current state-of-the-art method for decentralized learning with communication compression.
Create account to get full access
Overview
- This paper introduces AdaGossip, an algorithm for decentralized deep learning that adaptively adjusts the consensus step-size to improve communication efficiency and training performance.
- AdaGossip leverages compression techniques to reduce the amount of data transmitted between nodes in a decentralized network, while dynamically tuning the consensus step-size to mitigate the "vanishing variance" problem associated with fully decentralized optimization.
- The authors demonstrate that AdaGossip outperforms existing decentralized learning approaches in terms of training speed and model accuracy, while requiring significantly less communication.
Plain English Explanation
AdaGossip: Adaptive Consensus Step-size for Decentralized Deep Learning with Communication Compression is a new algorithm designed to improve the efficiency of decentralized deep learning. In traditional centralized deep learning, a single powerful server coordinates the training of a model across multiple devices or nodes. However, this approach can be impractical for large-scale applications due to issues like limited bandwidth, privacy concerns, and single points of failure.
Decentralized learning, on the other hand, allows each node to train the model independently and share updates with its neighbors in a distributed network. This can be more scalable and robust, but it also introduces challenges like the "vanishing variance problem" where the model updates become less effective over time.
AdaGossip addresses these challenges by using communication compression techniques to reduce the amount of data transmitted between nodes, while also dynamically adjusting the "consensus step-size" - a parameter that controls how much each node's update influences its neighbors. This helps mitigate the vanishing variance problem and improves the overall training speed and model accuracy compared to existing decentralized approaches.
The authors demonstrate the effectiveness of AdaGossip through experiments on various deep learning tasks, showing that it can achieve better performance with significantly less communication overhead than other decentralized learning strategies.
Technical Explanation
AdaGossip: Adaptive Consensus Step-size for Decentralized Deep Learning with Communication Compression proposes a novel algorithm for decentralized deep learning that adaptively adjusts the consensus step-size to improve communication efficiency and training performance.
In a decentralized setup, each node in the network trains a local model and exchanges updates with its neighbors. The consensus step-size controls how much each node's update influences its neighbors' models during this exchange. The authors identify the "vanishing variance problem" in fully decentralized optimization, where the model updates become less effective over time due to the diminishing influence of each node's local update.
To address this issue, AdaGossip leverages communication compression techniques to reduce the amount of data transmitted between nodes, while dynamically adjusting the consensus step-size. This adaptive step-size mechanism helps mitigate the vanishing variance problem and leads to faster convergence and better model performance compared to existing decentralized learning strategies.
The authors evaluate AdaGossip on various deep learning tasks and demonstrate its superiority over state-of-the-art decentralized optimization methods in terms of training speed, model accuracy, and communication efficiency.
Critical Analysis
The paper provides a thorough analysis of the "vanishing variance problem" in fully decentralized optimization and proposes a compelling solution in the form of AdaGossip. The adaptive consensus step-size mechanism is a key innovation that helps address this important challenge.
However, the authors acknowledge several limitations and areas for further research. For example, they note that AdaGossip's performance may degrade in scenarios with highly heterogeneous data or node capabilities, and suggest exploring more sophisticated compression techniques to further reduce communication overhead.
Additionally, while the experiments demonstrate the effectiveness of AdaGossip on various deep learning tasks, it would be valuable to see how the algorithm performs on a broader range of applications and real-world scenarios. Investigating the robustness of AdaGossip to different network topologies, node failure modes, and asynchronous updates could also provide valuable insights.
Overall, the AdaGossip algorithm represents a significant advancement in decentralized deep learning, and the authors' thoughtful discussion of the method's limitations and future research directions is commendable. Readers are encouraged to critically evaluate the claims and consider the implications of this work for their own research and applications.
Conclusion
AdaGossip: Adaptive Consensus Step-size for Decentralized Deep Learning with Communication Compression introduces a novel algorithm that addresses key challenges in decentralized deep learning. By dynamically adjusting the consensus step-size and leveraging communication compression, AdaGossip is able to achieve superior training performance and efficiency compared to existing decentralized approaches.
The authors' insights into the "vanishing variance problem" and their innovative solution in the form of AdaGossip represent an important contribution to the field of decentralized optimization and distributed deep learning. As the demand for scalable, privacy-preserving, and fault-tolerant machine learning systems continues to grow, AdaGossip and similar techniques may play a vital role in enabling the next generation of large-scale, distributed AI applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
SASG: Sparse Communication with Adaptive Aggregated Stochastic Gradients for Distributed Learning
Xiaoge Deng, Dongsheng Li, Tao Sun, Xicheng Lu
0
0
Gradient-based optimization methods implemented on distributed computing architectures are increasingly used to tackle large-scale machine learning applications. A key bottleneck in such distributed systems is the high communication overhead for exchanging information, such as stochastic gradients, between workers. The inherent causes of this bottleneck are the frequent communication rounds and the full model gradient transmission in every round. In this study, we present SASG, a communication-efficient distributed algorithm that enjoys the advantages of sparse communication and adaptive aggregated stochastic gradients. By dynamically determining the workers who need to communicate through an adaptive aggregation rule and sparsifying the transmitted information, the SASG algorithm reduces both the overhead of communication rounds and the number of communication bits in the distributed system. For the theoretical analysis, we introduce an important auxiliary variable and define a new Lyapunov function to prove that the communication-efficient algorithm is convergent. The convergence result is identical to the sublinear rate of stochastic gradient descent, and our result also reveals that SASG scales well with the number of distributed workers. Finally, experiments on training deep neural networks demonstrate that the proposed algorithm can significantly reduce communication overhead compared to previous methods.
6/11/2024

Communication-Efficient Large-Scale Distributed Deep Learning: A Comprehensive Survey
Feng Liang, Zhen Zhang, Haifeng Lu, Victor C. M. Leung, Yanyi Guo, Xiping Hu
0
0
With the rapid growth in the volume of data sets, models, and devices in the domain of deep learning, there is increasing attention on large-scale distributed deep learning. In contrast to traditional distributed deep learning, the large-scale scenario poses new challenges that include fault tolerance, scalability of algorithms and infrastructures, and heterogeneity in data sets, models, and resources. Due to intensive synchronization of models and sharing of data across GPUs and computing nodes during distributed training and inference processes, communication efficiency becomes the bottleneck for achieving high performance at a large scale. This article surveys the literature over the period of 2018-2023 on algorithms and technologies aimed at achieving efficient communication in large-scale distributed deep learning at various levels, including algorithms, frameworks, and infrastructures. Specifically, we first introduce efficient algorithms for model synchronization and communication data compression in the context of large-scale distributed training. Next, we introduce efficient strategies related to resource allocation and task scheduling for use in distributed training and inference. After that, we present the latest technologies pertaining to modern communication infrastructures used in distributed deep learning with a focus on examining the impact of the communication overhead in a large-scale and heterogeneous setting. Finally, we conduct a case study on the distributed training of large language models at a large scale to illustrate how to apply these technologies in real cases. This article aims to offer researchers a comprehensive understanding of the current landscape of large-scale distributed deep learning and to reveal promising future research directions toward communication-efficient solutions in this scope.
4/10/2024
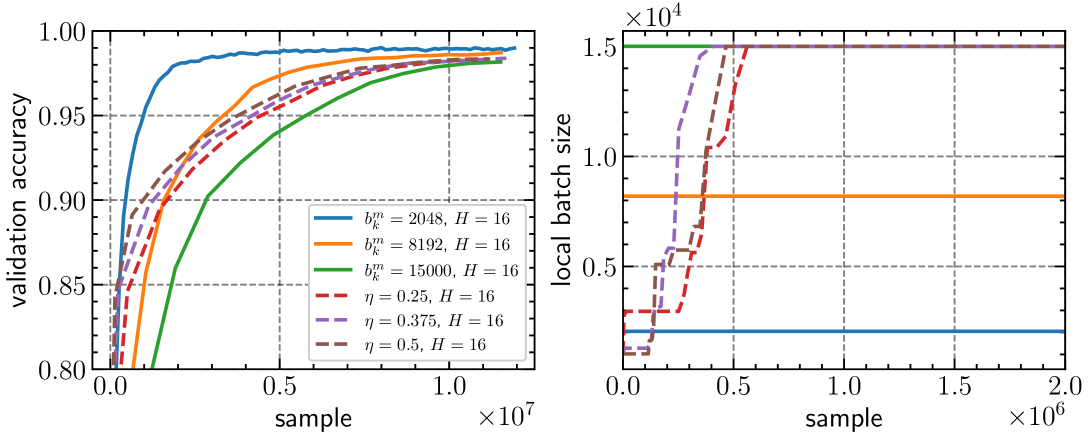
Communication-Efficient Adaptive Batch Size Strategies for Distributed Local Gradient Methods
Tim Tsz-Kit Lau, Weijian Li, Chenwei Xu, Han Liu, Mladen Kolar
0
0
Modern deep neural networks often require distributed training with many workers due to their large size. As worker numbers increase, communication overheads become the main bottleneck in data-parallel minibatch stochastic gradient methods with per-iteration gradient synchronization. Local gradient methods like Local SGD reduce communication by only syncing after several local steps. Despite understanding their convergence in i.i.d. and heterogeneous settings and knowing the importance of batch sizes for efficiency and generalization, optimal local batch sizes are difficult to determine. We introduce adaptive batch size strategies for local gradient methods that increase batch sizes adaptively to reduce minibatch gradient variance. We provide convergence guarantees under homogeneous data conditions and support our claims with image classification experiments, demonstrating the effectiveness of our strategies in training and generalization.
6/21/2024
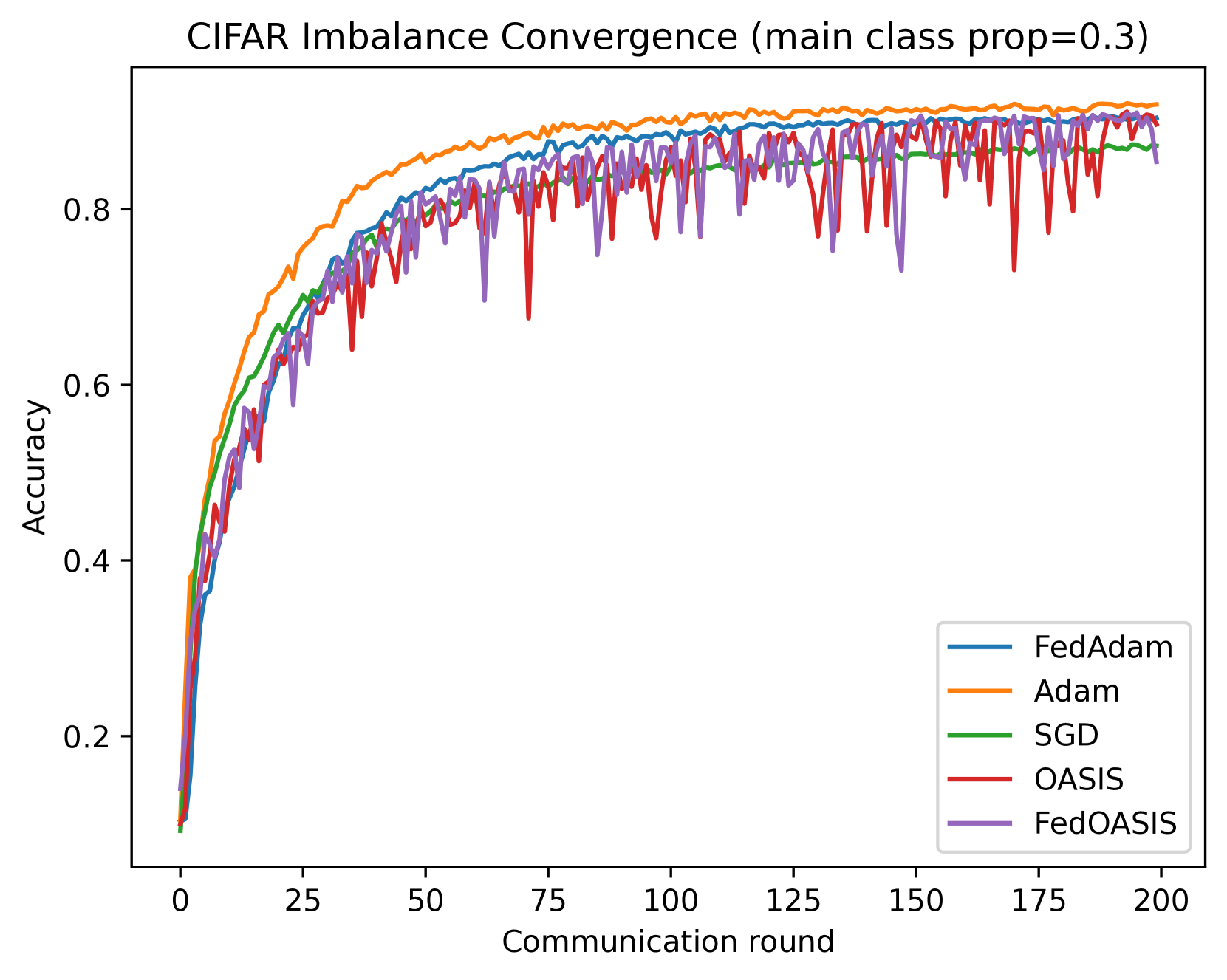
Local Methods with Adaptivity via Scaling
Savelii Chezhegov, Sergey Skorik, Nikolas Khachaturov, Danil Shalagin, Aram Avetisyan, Aleksandr Beznosikov, Martin Tak'av{c}, Yaroslav Kholodov, Alexander Gasnikov
0
0
The rapid development of machine learning and deep learning has introduced increasingly complex optimization challenges that must be addressed. Indeed, training modern, advanced models has become difficult to implement without leveraging multiple computing nodes in a distributed environment. Distributed optimization is also fundamental to emerging fields such as federated learning. Specifically, there is a need to organize the training process to minimize the time lost due to communication. A widely used and extensively researched technique to mitigate the communication bottleneck involves performing local training before communication. This approach is the focus of our paper. Concurrently, adaptive methods that incorporate scaling, notably led by Adam, have gained significant popularity in recent years. Therefore, this paper aims to merge the local training technique with the adaptive approach to develop efficient distributed learning methods. We consider the classical Local SGD method and enhance it with a scaling feature. A crucial aspect is that the scaling is described generically, allowing us to analyze various approaches, including Adam, RMSProp, and OASIS, in a unified manner. In addition to theoretical analysis, we validate the performance of our methods in practice by training a neural network.
6/14/2024