Learning Fine-Grained Controllability on Speech Generation via Efficient Fine-Tuning

0

Sign in to get full access
Overview
- This paper explores methods for fine-tuning large language models to achieve fine-grained controllability over speech generation, enabling users to customize attributes like speaking style, emotion, and pronunciation.
- The researchers propose an efficient fine-tuning approach that outperforms prior techniques in terms of sample efficiency and preservation of the model's original capabilities.
- Key contributions include a novel fine-tuning strategy, comprehensive evaluations on multiple datasets, and insights into the tradeoffs between controllability and model performance.
Plain English Explanation
The paper focuses on improving the fine-tuning process for large language models to give users more granular control over generated speech. Instead of just being able to control broad attributes like speaking style or emotion, the proposed approach allows for customizing even subtle details like pronunciation.
The researchers developed a new fine-tuning method that is more efficient than previous techniques. This means the model can be adapted to new preferences with fewer training examples, while still preserving the original capabilities of the base model. This is an important advancement, as fine-tuning large models can be computationally expensive and time-consuming.
Through extensive testing on multiple datasets, the paper provides insights into the tradeoffs between achieving fine-grained control and maintaining overall speech generation quality. This information can help guide researchers and developers in selecting the right balance for their specific use cases.
Technical Explanation
The paper presents a fine-tuning strategy for improving the controllability of speech generation models. The approach focuses on efficiently adapting large pre-trained models to new target attributes, like speaking style or emotion, while minimizing the loss of the model's original capabilities.
The key innovation is a novel fine-tuning method that selectively updates different components of the model based on the type of control being learned. This allows the model to specialize in the target attributes without drastically modifying the entire parameter space.
Extensive evaluations are conducted on multiple speech datasets, assessing both the level of control achieved and the overall quality of the generated speech. The results demonstrate that this fine-tuning approach outperforms prior techniques in terms of sample efficiency and preservation of the model's original capabilities.
The paper also provides insights into the tradeoffs between fine-grained controllability and model performance. These insights can inform the design of personalized speech generation systems that balance user customization with overall speech quality.
Critical Analysis
The paper presents a compelling approach for improving the fine-grained controllability of speech generation models. The proposed fine-tuning strategy appears to be a significant advancement over prior techniques, offering better sample efficiency and preservation of the original model's capabilities.
However, the paper does not address some potential limitations. For instance, it is unclear how the fine-tuning approach would scale to a wide range of target attributes or how it would handle conflicting control signals (e.g., trying to simultaneously modify speaking style and emotion). Additionally, the evaluations focus on relatively narrow datasets, and it would be valuable to assess the method's performance on more diverse and realistic speech data.
Further research could also explore the combination of this fine-tuning approach with other techniques, such as adapter-based architectures or meta-learning, to achieve even greater flexibility and control over speech generation.
Conclusion
This paper presents an efficient fine-tuning method for endowing large language models with fine-grained controllability over speech generation. By selectively updating different components of the model, the approach can specialize in target attributes like speaking style and emotion while preserving the original model's capabilities.
The comprehensive evaluations demonstrate the effectiveness of this approach, and the insights into the tradeoffs between control and performance can guide the development of personalized speech generation systems. This work represents an important step forward in enabling users to customize synthetic speech to their preferences, with potential applications in assistive technology, voice acting, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Fine-Grained Controllability on Speech Generation via Efficient Fine-Tuning
Chung-Ming Chien, Andros Tjandra, Apoorv Vyas, Matt Le, Bowen Shi, Wei-Ning Hsu
As the scale of generative models continues to grow, efficient reuse and adaptation of pre-trained models have become crucial considerations. In this work, we propose Voicebox Adapter, a novel approach that integrates fine-grained conditions into a pre-trained Voicebox speech generation model using a cross-attention module. To ensure a smooth integration of newly added modules with pre-trained ones, we explore various efficient fine-tuning approaches. Our experiment shows that the LoRA with bias-tuning configuration yields the best performance, enhancing controllability without compromising speech quality. Across three fine-grained conditional generation tasks, we demonstrate the effectiveness and resource efficiency of Voicebox Adapter. Follow-up experiments further highlight the robustness of Voicebox Adapter across diverse data setups.
Read more6/11/2024

0
An Adapter-Based Unified Model for Multiple Spoken Language Processing Tasks
Varsha Suresh, Salah Ait-Mokhtar, Caroline Brun, Ioan Calapodescu
Self-supervised learning models have revolutionized the field of speech processing. However, the process of fine-tuning these models on downstream tasks requires substantial computational resources, particularly when dealing with multiple speech-processing tasks. In this paper, we explore the potential of adapter-based fine-tuning in developing a unified model capable of effectively handling multiple spoken language processing tasks. The tasks we investigate are Automatic Speech Recognition, Phoneme Recognition, Intent Classification, Slot Filling, and Spoken Emotion Recognition. We validate our approach through a series of experiments on the SUPERB benchmark, and our results indicate that adapter-based fine-tuning enables a single encoder-decoder model to perform multiple speech processing tasks with an average improvement of 18.4% across the five target tasks while staying efficient in terms of parameter updates.
Read more6/24/2024
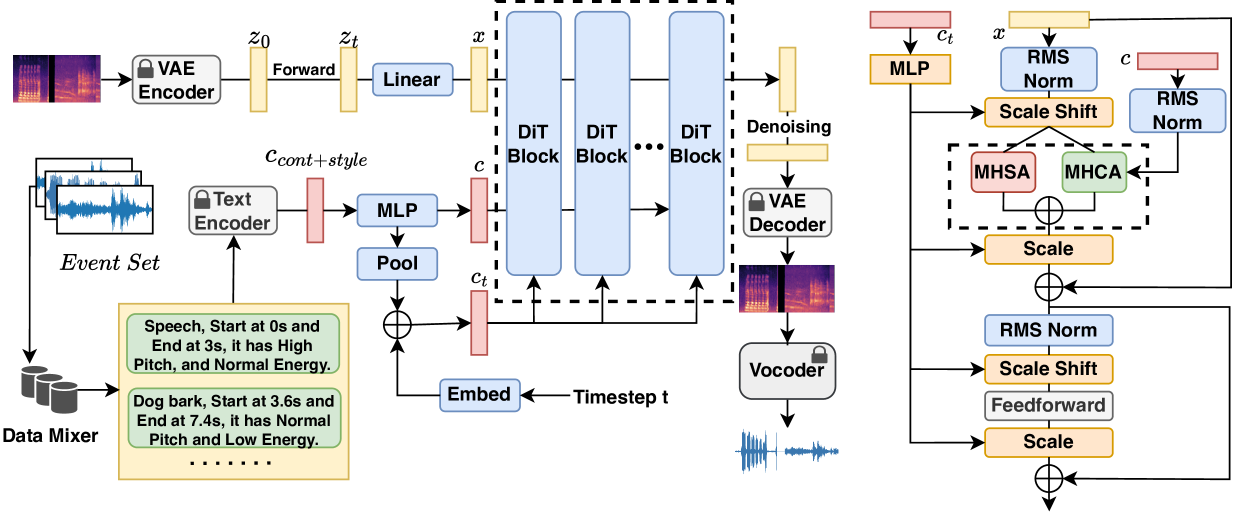
0
AudioComposer: Towards Fine-grained Audio Generation with Natural Language Descriptions
Yuanyuan Wang, Hangting Chen, Dongchao Yang, Zhiyong Wu, Helen Meng, Xixin Wu
Current Text-to-audio (TTA) models mainly use coarse text descriptions as inputs to generate audio, which hinders models from generating audio with fine-grained control of content and style. Some studies try to improve the granularity by incorporating additional frame-level conditions or control networks. However, this usually leads to complex system design and difficulties due to the requirement for reference frame-level conditions. To address these challenges, we propose AudioComposer, a novel TTA generation framework that relies solely on natural language descriptions (NLDs) to provide both content specification and style control information. To further enhance audio generative modeling, we employ flow-based diffusion transformers with the cross-attention mechanism to incorporate text descriptions effectively into audio generation processes, which can not only simultaneously consider the content and style information in the text inputs, but also accelerate generation compared to other architectures. Furthermore, we propose a novel and comprehensive automatic data simulation pipeline to construct data with fine-grained text descriptions, which significantly alleviates the problem of data scarcity in the area. Experiments demonstrate the effectiveness of our framework using solely NLDs as inputs for content specification and style control. The generation quality and controllability surpass state-of-the-art TTA models, even with a smaller model size.
Read more9/20/2024
🛸
0
Connecting the Dots: Collaborative Fine-tuning for Black-Box Vision-Language Models
Zhengbo Wang, Jian Liang, Ran He, Zilei Wang, Tieniu Tan
With the emergence of pretrained vision-language models (VLMs), considerable efforts have been devoted to fine-tuning them for downstream tasks. Despite the progress made in designing efficient fine-tuning methods, such methods require access to the model's parameters, which can be challenging as model owners often opt to provide their models as a black box to safeguard model ownership. This paper proposes a textbf{C}ollabotextbf{ra}tive textbf{F}ine-textbf{T}uning (textbf{CraFT}) approach for fine-tuning black-box VLMs to downstream tasks, where one only has access to the input prompts and the output predictions of the model. CraFT comprises two modules, a prompt generation module for learning text prompts and a prediction refinement module for enhancing output predictions in residual style. Additionally, we introduce an auxiliary prediction-consistent loss to promote consistent optimization across these modules. These modules are optimized by a novel collaborative training algorithm. Extensive experiments on few-shot classification over 15 datasets demonstrate the superiority of CraFT. The results show that CraFT achieves a decent gain of about 12% with 16-shot datasets and only 8,000 queries. Moreover, CraFT trains faster and uses only about 1/80 of the memory footprint for deployment, while sacrificing only 1.62% compared to the white-box method. Our code is publicly available at https://github.com/mrflogs/CraFT .
Read more6/4/2024