Publicly Shareable Clinical Large Language Model Built on Synthetic Clinical Notes

0
💬
Sign in to get full access
Overview
- Researchers developed a specialized clinical language model called Asclepius using synthetic clinical notes
- Asclepius was trained on publicly available case reports, then evaluated on real-world clinical notes
- Asclepius outperformed other large language models like GPT-3.5-turbo in clinical text tasks
- The researchers made all resources used in Asclepius publicly accessible for future research
Plain English Explanation
Artificial intelligence (AI) models trained on large volumes of text data, known as large language models, have shown great potential in various applications. However, adapting open-source large language models to clinical settings can be challenging due to the limited accessibility and strict privacy regulations surrounding real-world clinical notes.
To unlock the potential of large language models for clinical text, the researchers in this study utilized synthetic data to generate a specialized clinical language model. They created a large-scale dataset of synthetic clinical notes by extracting case reports from biomedical literature. This allowed them to train a new clinical language model, named Asclepius, without needing access to real patient data.
To validate the effectiveness of this approach, the researchers evaluated Asclepius on real clinical notes and compared its performance to other large language models, including GPT-3.5-turbo. The results showed that Asclepius outperformed these models, demonstrating the potential of using synthetic data to enhance clinical documentation and leverage generative AI models.
The researchers have made all the resources used in the development of Asclepius, including the model weights, code, and data, publicly available for future research. This will help advance the field of clinical language modeling and improve the accessibility of large language models in healthcare applications.
Technical Explanation
The researchers in this study recognized the challenge of adapting open-source large language models to clinical settings due to the limited accessibility and strict privacy regulations surrounding real-world clinical notes. To unlock the potential of large language models for clinical text, they developed a specialized clinical language model called Asclepius using synthetic data.
The researchers utilized large language models to generate synthetic clinical notes by extracting case reports from publicly available biomedical literature. These synthetic notes were then used to train Asclepius, a custom-built clinical language model.
To validate the effectiveness of this approach, the researchers evaluated Asclepius on real clinical notes and benchmarked its performance against several other large language models, including GPT-3.5-turbo and open-source alternatives. They also compared Asclepius with variants trained on real clinical notes to further validate the use of synthetic data.
The findings of the study convincingly demonstrated that synthetic clinical notes can serve as viable substitutes for real ones when constructing high-performing clinical language models. This conclusion was supported by detailed evaluations conducted by both GPT-4 and medical professionals.
Critical Analysis
While the researchers have shown the potential of using synthetic clinical notes to train specialized language models, there may be some limitations to this approach. The synthetic notes, although generated from real-world case reports, may not fully capture the nuances and complexities of actual clinical documentation. Additionally, the performance of the Asclepius model on real-world clinical tasks may still be influenced by the quality and representativeness of the synthetic data used in its training.
It would be valuable for future research to further investigate the limitations and potential biases introduced by the use of synthetic data, as well as explore ways to enhance the clinical documentation and leverage generative AI models in a more robust and reliable manner.
Conclusion
The researchers in this study have demonstrated a novel approach to utilizing large language models to generate synthetic clinical notes and training a specialized clinical language model called Asclepius. By comparing Asclepius to other open-source language models, they have shown that synthetic clinical notes can serve as viable substitutes for real ones in constructing high-performing clinical language models.
This research has significant implications for adapting open-source large language models to clinical settings and enhancing clinical documentation through the use of synthetic data and generative AI. The publicly accessible resources provided by the researchers will further advance the field of clinical language modeling and improve the accessibility of large language models in healthcare applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Publicly Shareable Clinical Large Language Model Built on Synthetic Clinical Notes
Sunjun Kweon, Junu Kim, Jiyoun Kim, Sujeong Im, Eunbyeol Cho, Seongsu Bae, Jungwoo Oh, Gyubok Lee, Jong Hak Moon, Seng Chan You, Seungjin Baek, Chang Hoon Han, Yoon Bin Jung, Yohan Jo, Edward Choi
The development of large language models tailored for handling patients' clinical notes is often hindered by the limited accessibility and usability of these notes due to strict privacy regulations. To address these challenges, we first create synthetic large-scale clinical notes using publicly available case reports extracted from biomedical literature. We then use these synthetic notes to train our specialized clinical large language model, Asclepius. While Asclepius is trained on synthetic data, we assess its potential performance in real-world applications by evaluating it using real clinical notes. We benchmark Asclepius against several other large language models, including GPT-3.5-turbo and other open-source alternatives. To further validate our approach using synthetic notes, we also compare Asclepius with its variants trained on real clinical notes. Our findings convincingly demonstrate that synthetic clinical notes can serve as viable substitutes for real ones when constructing high-performing clinical language models. This conclusion is supported by detailed evaluations conducted by both GPT-4 and medical professionals. All resources including weights, codes, and data used in the development of Asclepius are made publicly accessible for future research. (https://github.com/starmpcc/Asclepius)
Read more7/30/2024
0
Towards Adapting Open-Source Large Language Models for Expert-Level Clinical Note Generation
Hanyin Wang, Chufan Gao, Bolun Liu, Qiping Xu, Guleid Hussein, Mohamad El Labban, Kingsley Iheasirim, Hariprasad Korsapati, Chuck Outcalt, Jimeng Sun
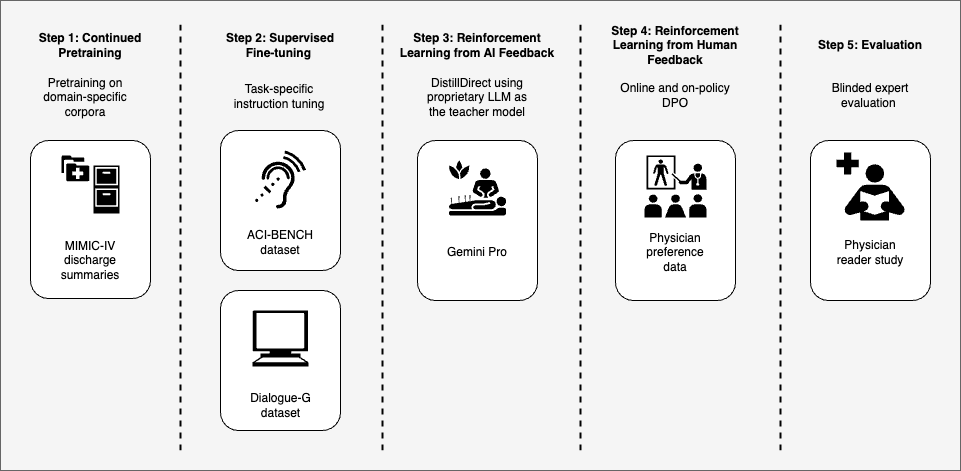
Proprietary Large Language Models (LLMs) such as GPT-4 and Gemini have demonstrated promising capabilities in clinical text summarization tasks. However, due to patient data privacy concerns and computational costs, many healthcare providers prefer using small, locally-hosted models over external generic LLMs. This study presents a comprehensive domain- and task-specific adaptation process for the open-source LLaMA-2 13 billion parameter model, enabling it to generate high-quality clinical notes from outpatient patient-doctor dialogues. Our process incorporates continued pre-training, supervised fine-tuning, and reinforcement learning from both AI and human feedback. We introduced a new approach, DistillDirect, for performing on-policy reinforcement learning with Gemini 1.0 Pro as the teacher model. Our resulting model, LLaMA-Clinic, can generate clinical notes comparable in quality to those authored by physicians. In a blinded physician reader study, the majority (90.4%) of individual evaluations rated the notes generated by LLaMA-Clinic as acceptable or higher across all three criteria: real-world readiness, completeness, and accuracy. In the more challenging Assessment and Plan section, LLaMA-Clinic scored higher (4.2/5) in real-world readiness than physician-authored notes (4.1/5). Our cost analysis for inference shows that our LLaMA-Clinic model achieves a 3.75-fold cost reduction compared to an external generic LLM service. Additionally, we highlight key considerations for future clinical note-generation tasks, emphasizing the importance of pre-defining a best-practice note format, rather than relying on LLMs to determine this for clinical practice. We have made our newly created synthetic clinic dialogue-note dataset and the physician feedback dataset publicly available to foster future research.
Read more6/11/2024
💬
0
Answering real-world clinical questions using large language model based systems
Yen Sia Low (Atropos Health, New York NY, USA), Michael L. Jackson (Atropos Health, New York NY, USA), Rebecca J. Hyde (Atropos Health, New York NY, USA), Robert E. Brown (Atropos Health, New York NY, USA), Neil M. Sanghavi (Atropos Health, New York NY, USA), Julian D. Baldwin (Atropos Health, New York NY, USA), C. William Pike (Atropos Health, New York NY, USA), Jananee Muralidharan (Atropos Health, New York NY, USA), Gavin Hui (Atropos Health, New York NY, USA, Department of Medicine, University of California, Los Angeles CA, USA), Natasha Alexander (Department of Pediatrics, The Hospital for Sick Children, Toronto ON, Canada), Hadeel Hassan (Department of Pediatrics, The Hospital for Sick Children, Toronto ON, Canada), Rahul V. Nene (Department of Emergency Medicine, University of California, San Diego CA, USA), Morgan Pike (Department of Emergency Medicine, University of Michigan, Ann Arbor MI, USA), Courtney J. Pokrzywa (Department of Surgery, Columbia University, New York NY, USA), Shivam Vedak (Center for Biomedical Informatics Research, Stanford University, Stanford CA, USA), Adam Paul Yan (Department of Pediatrics, The Hospital for Sick Children, Toronto ON, Canada), Dong-han Yao (Center for Biomedical Informatics Research, Stanford University, Stanford CA, USA), Amy R. Zipursky (Department of Pediatrics, The Hospital for Sick Children, Toronto ON, Canada), Christina Dinh (Atropos Health, New York NY, USA), Philip Ballentine (Atropos Health, New York NY, USA), Dan C. Derieg (Atropos Health, New York NY, USA), Vladimir Polony (Atropos Health, New York NY, USA), Rehan N. Chawdry (Atropos Health, New York NY, USA), Jordan Davies (Atropos Health, New York NY, USA), Brigham B. Hyde (Atropos Health, New York NY, USA), Nigam H. Shah (Atropos Health, New York NY, USA, Center for Biomedical Informatics Research, Stanford University, Stanford CA, USA), Saurabh Gombar (Atropos Health, New York NY, USA, Department of Pathology, Stanford University, Stanford CA, USA)
Evidence to guide healthcare decisions is often limited by a lack of relevant and trustworthy literature as well as difficulty in contextualizing existing research for a specific patient. Large language models (LLMs) could potentially address both challenges by either summarizing published literature or generating new studies based on real-world data (RWD). We evaluated the ability of five LLM-based systems in answering 50 clinical questions and had nine independent physicians review the responses for relevance, reliability, and actionability. As it stands, general-purpose LLMs (ChatGPT-4, Claude 3 Opus, Gemini Pro 1.5) rarely produced answers that were deemed relevant and evidence-based (2% - 10%). In contrast, retrieval augmented generation (RAG)-based and agentic LLM systems produced relevant and evidence-based answers for 24% (OpenEvidence) to 58% (ChatRWD) of questions. Only the agentic ChatRWD was able to answer novel questions compared to other LLMs (65% vs. 0-9%). These results suggest that while general-purpose LLMs should not be used as-is, a purpose-built system for evidence summarization based on RAG and one for generating novel evidence working synergistically would improve availability of pertinent evidence for patient care.
Read more7/2/2024

0
Towards Evaluating and Building Versatile Large Language Models for Medicine
Chaoyi Wu, Pengcheng Qiu, Jinxin Liu, Hongfei Gu, Na Li, Ya Zhang, Yanfeng Wang, Weidi Xie
In this study, we present MedS-Bench, a comprehensive benchmark designed to evaluate the performance of large language models (LLMs) in clinical contexts. Unlike existing benchmarks that focus on multiple-choice question answering, MedS-Bench spans 11 high-level clinical tasks, including clinical report summarization, treatment recommendations, diagnosis, named entity recognition, and medical concept explanation, among others. We evaluated six leading LLMs, e.g., MEDITRON, Mistral, InternLM 2, Llama 3, GPT-4, and Claude-3.5 using few-shot prompting, and found that even the most sophisticated models struggle with these complex tasks. To address these limitations, we developed MedS-Ins, a large-scale instruction tuning dataset for medicine. MedS-Ins comprises 58 medically oriented language corpora, totaling 13.5 million samples across 122 tasks. To demonstrate the dataset's utility, we conducted a proof-of-concept experiment by performing instruction tuning on a lightweight, open-source medical language model. The resulting model, MMedIns-Llama 3, significantly outperformed existing models across nearly all clinical tasks. To promote further advancements in the application of LLMs to clinical challenges, we have made the MedS-Ins dataset fully accessible and invite the research community to contribute to its expansion.Additionally, we have launched a dynamic leaderboard for MedS-Bench, which we plan to regularly update the test set to track progress and enhance the adaptation of general LLMs to the medical domain. Leaderboard: https://henrychur.github.io/MedS-Bench/. Github: https://github.com/MAGIC-AI4Med/MedS-Ins.
Read more9/6/2024