Adaptive Advantage-Guided Policy Regularization for Offline Reinforcement Learning

0

Sign in to get full access
Overview
- This paper introduces a new method called Adaptive Advantage-Guided Policy Regularization (A2PO) for offline reinforcement learning.
- A2PO aims to effectively learn policies from offline datasets without the need for online interaction with the environment.
- The method adaptively regularizes the policy by leveraging advantage-guided regularization, which helps the policy generalize beyond the observed data.
Plain English Explanation
Reinforcement learning is a powerful technique for training AI systems to make decisions and solve complex problems. Typically, these systems learn by interacting with an environment and receiving feedback on their actions. However, in some cases, it may not be possible or practical to have the AI system directly interact with the real-world environment.
Offline reinforcement learning is a approach that allows the AI system to learn from previously collected data, without the need for direct interaction. This is useful in scenarios where data is more readily available than the ability to interact with the environment, such as in robotics, healthcare, or finance.
The A2PO method introduced in this paper aims to improve upon existing offline reinforcement learning techniques. It does this by using a novel "advantage-guided" regularization technique that helps the AI system generalize its learning beyond the specific data it was trained on. This allows the system to make better decisions in a wider range of situations.
The advantage-guided regularization used in A2PO works by nudging the AI system towards actions that are likely to lead to better outcomes, based on the existing data. This helps the system avoid getting stuck in suboptimal policies and instead find more generally effective solutions.
Additionally, the A2PO method is "adaptive," meaning it can automatically adjust the amount of regularization applied based on the characteristics of the training data. This helps ensure the system learns as effectively as possible from the available information.
Technical Explanation
The key technical components of the A2PO method are:
-
Advantage-Guided Policy Regularization: A2PO uses an advantage-guided regularization term in the policy optimization objective. This term encourages the policy to select actions that have high estimated advantage values, based on the offline data. This helps the policy generalize beyond the observed data.
-
Adaptive Regularization Strength: The strength of the advantage-guided regularization is automatically adjusted during training. This adaptation is based on the quality of the current policy, ensuring the regularization is applied effectively throughout the learning process.
-
Practical Implementations: The authors provide two practical implementations of A2PO, one using preferred action optimized diffusion policies and another using policy-guided diffusion. These provide flexible ways to incorporate the advantage-guided regularization into the policy optimization.
The paper also includes a thorough experimental evaluation of A2PO on a range of offline reinforcement learning benchmarks. The results show that A2PO outperforms state-of-the-art offline RL methods, demonstrating the effectiveness of the advantage-guided regularization and adaptive strength adjustment.
Critical Analysis
The paper presents a well-designed and thoughtfully implemented approach to offline reinforcement learning. The key strengths of the A2PO method are its ability to effectively leverage offline data through advantage-guided regularization, and its adaptive mechanism for adjusting the regularization strength.
That said, the paper does acknowledge some limitations and areas for future work. For example, the authors note that the performance of A2PO can still be sensitive to the quality and distribution of the offline dataset. Additionally, the paper does not explore the application of A2PO to more complex, high-dimensional environments, which may require further advancements to the method.
Further research could also investigate ways to make the A2PO method even more robust and broadly applicable, such as by incorporating additional techniques for improving policy generalization or by exploring the use of A2PO in other reinforcement learning settings beyond the offline case.
Conclusion
The Adaptive Advantage-Guided Policy Regularization (A2PO) method introduced in this paper represents an important advancement in the field of offline reinforcement learning. By leveraging advantage-guided regularization and an adaptive approach to adjusting the regularization strength, A2PO can effectively learn policies from offline data, without the need for direct interaction with the environment.
The strong experimental results demonstrate the potential of A2PO to improve the performance of AI systems in a wide range of real-world applications where offline data is more readily available than the ability to interact with the environment. As the field of offline reinforcement learning continues to evolve, the insights and techniques presented in this paper are likely to have a significant impact on the development of more effective and versatile AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Adaptive Advantage-Guided Policy Regularization for Offline Reinforcement Learning
Tenglong Liu, Yang Li, Yixing Lan, Hao Gao, Wei Pan, Xin Xu
In offline reinforcement learning, the challenge of out-of-distribution (OOD) is pronounced. To address this, existing methods often constrain the learned policy through policy regularization. However, these methods often suffer from the issue of unnecessary conservativeness, hampering policy improvement. This occurs due to the indiscriminate use of all actions from the behavior policy that generates the offline dataset as constraints. The problem becomes particularly noticeable when the quality of the dataset is suboptimal. Thus, we propose Adaptive Advantage-guided Policy Regularization (A2PR), obtaining high-advantage actions from an augmented behavior policy combined with VAE to guide the learned policy. A2PR can select high-advantage actions that differ from those present in the dataset, while still effectively maintaining conservatism from OOD actions. This is achieved by harnessing the VAE capacity to generate samples matching the distribution of the data points. We theoretically prove that the improvement of the behavior policy is guaranteed. Besides, it effectively mitigates value overestimation with a bounded performance gap. Empirically, we conduct a series of experiments on the D4RL benchmark, where A2PR demonstrates state-of-the-art performance. Furthermore, experimental results on additional suboptimal mixed datasets reveal that A2PR exhibits superior performance. Code is available at https://github.com/ltlhuuu/A2PR.
Read more7/16/2024
0
A2PO: Towards Effective Offline Reinforcement Learning from an Advantage-aware Perspective
Yunpeng Qing, Shunyu liu, Jingyuan Cong, Kaixuan Chen, Yihe Zhou, Mingli Song
Offline reinforcement learning endeavors to leverage offline datasets to craft effective agent policy without online interaction, which imposes proper conservative constraints with the support of behavior policies to tackle the out-of-distribution problem. However, existing works often suffer from the constraint conflict issue when offline datasets are collected from multiple behavior policies, i.e., different behavior policies may exhibit inconsistent actions with distinct returns across the state space. To remedy this issue, recent advantage-weighted methods prioritize samples with high advantage values for agent training while inevitably ignoring the diversity of behavior policy. In this paper, we introduce a novel Advantage-Aware Policy Optimization (A2PO) method to explicitly construct advantage-aware policy constraints for offline learning under mixed-quality datasets. Specifically, A2PO employs a conditional variational auto-encoder to disentangle the action distributions of intertwined behavior policies by modeling the advantage values of all training data as conditional variables. Then the agent can follow such disentangled action distribution constraints to optimize the advantage-aware policy towards high advantage values. Extensive experiments conducted on both the single-quality and mixed-quality datasets of the D4RL benchmark demonstrate that A2PO yields results superior to the counterparts. Our code will be made publicly available.
Read more9/25/2024

0
Augmenting Offline RL with Unlabeled Data
Zhao Wang, Briti Gangopadhyay, Jia-Fong Yeh, Shingo Takamatsu
Recent advancements in offline Reinforcement Learning (Offline RL) have led to an increased focus on methods based on conservative policy updates to address the Out-of-Distribution (OOD) issue. These methods typically involve adding behavior regularization or modifying the critic learning objective, focusing primarily on states or actions with substantial dataset support. However, we challenge this prevailing notion by asserting that the absence of an action or state from a dataset does not necessarily imply its suboptimality. In this paper, we propose a novel approach to tackle the OOD problem. We introduce an offline RL teacher-student framework, complemented by a policy similarity measure. This framework enables the student policy to gain insights not only from the offline RL dataset but also from the knowledge transferred by a teacher policy. The teacher policy is trained using another dataset consisting of state-action pairs, which can be viewed as practical domain knowledge acquired without direct interaction with the environment. We believe this additional knowledge is key to effectively solving the OOD issue. This research represents a significant advancement in integrating a teacher-student network into the actor-critic framework, opening new avenues for studies on knowledge transfer in offline RL and effectively addressing the OOD challenge.
Read more6/12/2024
0
Preferred-Action-Optimized Diffusion Policies for Offline Reinforcement Learning
Tianle Zhang, Jiayi Guan, Lin Zhao, Yihang Li, Dongjiang Li, Zecui Zeng, Lei Sun, Yue Chen, Xuelong Wei, Lusong Li, Xiaodong He
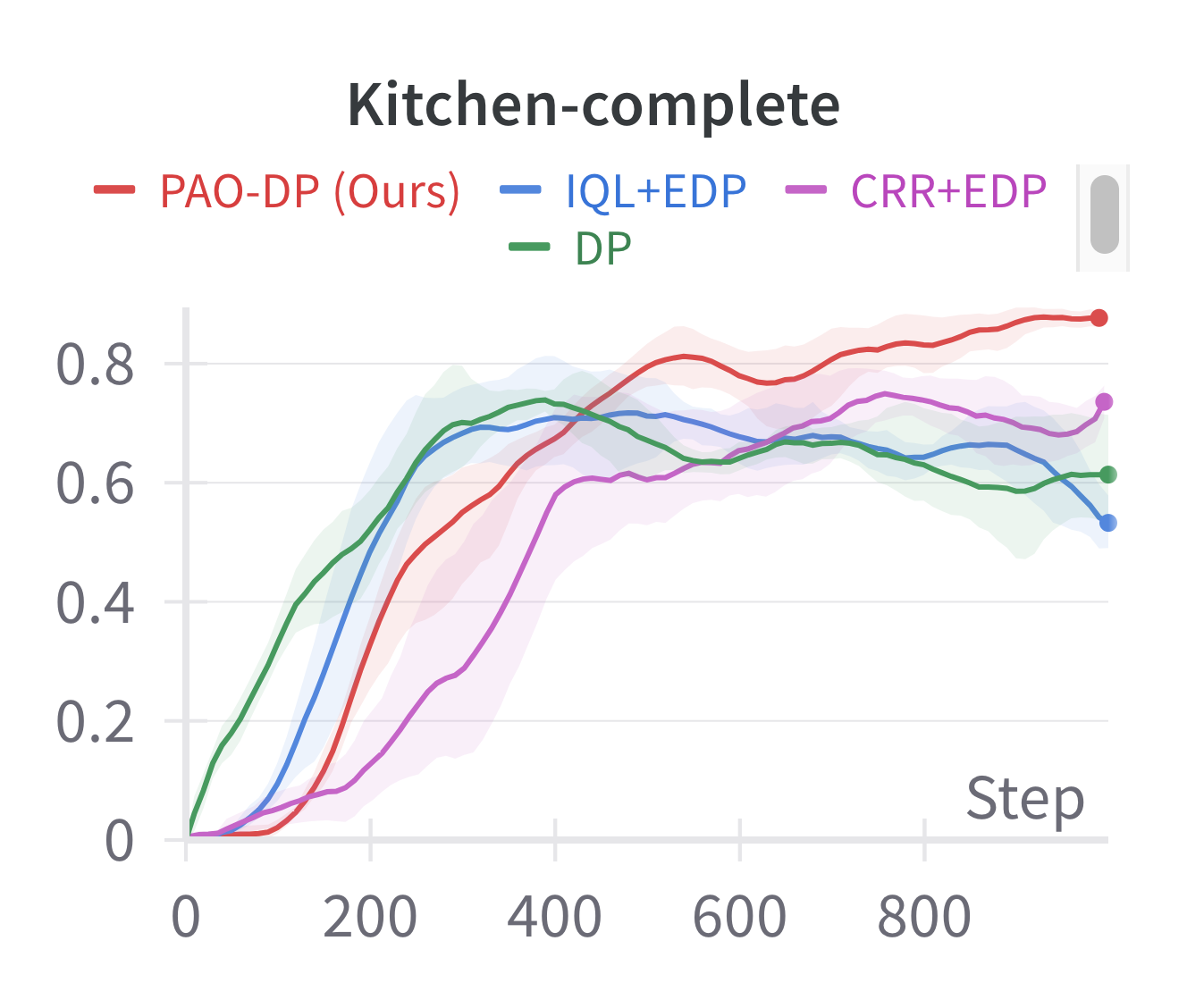
Offline reinforcement learning (RL) aims to learn optimal policies from previously collected datasets. Recently, due to their powerful representational capabilities, diffusion models have shown significant potential as policy models for offline RL issues. However, previous offline RL algorithms based on diffusion policies generally adopt weighted regression to improve the policy. This approach optimizes the policy only using the collected actions and is sensitive to Q-values, which limits the potential for further performance enhancement. To this end, we propose a novel preferred-action-optimized diffusion policy for offline RL. In particular, an expressive conditional diffusion model is utilized to represent the diverse distribution of a behavior policy. Meanwhile, based on the diffusion model, preferred actions within the same behavior distribution are automatically generated through the critic function. Moreover, an anti-noise preference optimization is designed to achieve policy improvement by using the preferred actions, which can adapt to noise-preferred actions for stable training. Extensive experiments demonstrate that the proposed method provides competitive or superior performance compared to previous state-of-the-art offline RL methods, particularly in sparse reward tasks such as Kitchen and AntMaze. Additionally, we empirically prove the effectiveness of anti-noise preference optimization.
Read more5/30/2024