Towards Robust Policy: Enhancing Offline Reinforcement Learning with Adversarial Attacks and Defenses
2405.11206
0
0

Abstract
Offline reinforcement learning (RL) addresses the challenge of expensive and high-risk data exploration inherent in RL by pre-training policies on vast amounts of offline data, enabling direct deployment or fine-tuning in real-world environments. However, this training paradigm can compromise policy robustness, leading to degraded performance in practical conditions due to observation perturbations or intentional attacks. While adversarial attacks and defenses have been extensively studied in deep learning, their application in offline RL is limited. This paper proposes a framework to enhance the robustness of offline RL models by leveraging advanced adversarial attacks and defenses. The framework attacks the actor and critic components by perturbing observations during training and using adversarial defenses as regularization to enhance the learned policy. Four attacks and two defenses are introduced and evaluated on the D4RL benchmark. The results show the vulnerability of both the actor and critic to attacks and the effectiveness of the defenses in improving policy robustness. This framework holds promise for enhancing the reliability of offline RL models in practical scenarios.
Create account to get full access
Overview
- This paper explores ways to enhance offline reinforcement learning (RL) by making it more robust against adversarial attacks.
- Offline RL trains an agent to perform a task without interacting with the real environment, which can be safer and more efficient than traditional online RL.
- However, offline RL models can be vulnerable to adversarial perturbations that could cause them to make poor decisions.
- The researchers propose using adversarial attacks and defenses to improve the robustness of offline RL agents.
Plain English Explanation
Reinforcement learning (RL) is a type of machine learning where an agent learns to perform a task by interacting with an environment and receiving rewards or penalties. Traditionally, RL agents are trained by directly interacting with the real environment, which can be time-consuming, expensive, or even dangerous in some cases.
Offline RL solves this problem by training the agent using previously collected data, without any direct interaction. This can be more efficient and practical, but it also introduces new challenges. One key issue is that offline RL models can be vulnerable to adversarial attacks - small, carefully crafted changes to the input data that can cause the model to make poor decisions.
This paper explores ways to make offline RL more robust to these adversarial attacks. The researchers propose using adversarial attacks during the training process to help the model learn to be more resilient. They also investigate defensive techniques that can be applied to the trained model to further enhance its robustness.
The goal is to create offline RL agents that can perform well and make reliable decisions, even in the face of adversarial attempts to manipulate their behavior. This could have important implications for using RL in safety-critical applications where reliability and security are paramount.
Technical Explanation
The paper begins by reviewing the current state of offline RL research and the challenges posed by adversarial attacks. The authors then propose a framework for enhancing the robustness of offline RL agents through the use of adversarial attacks and defenses.
The key elements of their approach include:
-
Adversarial Attack Generation: The researchers develop techniques to generate adversarial perturbations that can be applied to the input data during offline RL training. This helps the model learn to be more resilient to such attacks.
-
Adversarial Defense Training: The training process is modified to incorporate the adversarial perturbations, incentivizing the model to learn representations that are robust to these attacks.
-
Adversarial Evaluation: The trained models are evaluated under various adversarial attack scenarios to assess their robustness and identify any remaining vulnerabilities.
-
Defensive Techniques: The authors explore different defensive strategies, such as input transformation and adversarial training, to further enhance the model's resilience to adversarial perturbations.
Through a series of experiments on several benchmark RL tasks, the researchers demonstrate that their approach can significantly improve the robustness of offline RL agents without compromising their overall performance.
Critical Analysis
The paper presents a promising approach for enhancing the robustness of offline RL, which is an important step towards making RL systems more reliable and deployable in real-world applications. The use of adversarial attacks and defenses during training is a novel and well-motivated strategy, and the experimental results provide strong evidence for its effectiveness.
However, the paper also acknowledges several limitations and areas for further research. For example, the proposed techniques may not be as effective against more advanced or adaptive adversarial attacks, and the computational overhead of the adversarial training process could be a practical challenge.
Additionally, the paper focuses primarily on improving the robustness of the policy (decision-making) component of the RL agent, but does not address the potential vulnerabilities of the value function or other critical elements of the RL system. Expanding the scope of the robustness analysis could lead to a more comprehensive understanding of the problem.
Further research is also needed to understand the underlying mechanisms by which the proposed techniques enhance robustness, and to explore the broader implications of this work for the design and deployment of secure and reliable RL systems.
Conclusion
This paper presents a novel approach for improving the robustness of offline reinforcement learning agents by incorporating adversarial attacks and defenses into the training process. The results demonstrate that this strategy can significantly enhance the resilience of RL models to adversarial perturbations without compromising their overall performance.
While the proposed techniques have limitations and require further research, this work represents an important step towards developing more secure and reliable RL systems that can be safely deployed in real-world, safety-critical applications. By explicitly addressing the problem of adversarial vulnerabilities, the authors have laid the groundwork for a new generation of RL agents that are better equipped to handle the challenges of the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Optimal Attack and Defense for Reinforcement Learning
Jeremy McMahan, Young Wu, Xiaojin Zhu, Qiaomin Xie
0
0
To ensure the usefulness of Reinforcement Learning (RL) in real systems, it is crucial to ensure they are robust to noise and adversarial attacks. In adversarial RL, an external attacker has the power to manipulate the victim agent's interaction with the environment. We study the full class of online manipulation attacks, which include (i) state attacks, (ii) observation attacks (which are a generalization of perceived-state attacks), (iii) action attacks, and (iv) reward attacks. We show the attacker's problem of designing a stealthy attack that maximizes its own expected reward, which often corresponds to minimizing the victim's value, is captured by a Markov Decision Process (MDP) that we call a meta-MDP since it is not the true environment but a higher level environment induced by the attacked interaction. We show that the attacker can derive optimal attacks by planning in polynomial time or learning with polynomial sample complexity using standard RL techniques. We argue that the optimal defense policy for the victim can be computed as the solution to a stochastic Stackelberg game, which can be further simplified into a partially-observable turn-based stochastic game (POTBSG). Neither the attacker nor the victim would benefit from deviating from their respective optimal policies, thus such solutions are truly robust. Although the defense problem is NP-hard, we show that optimal Markovian defenses can be computed (learned) in polynomial time (sample complexity) in many scenarios.
6/18/2024

Augmenting Offline RL with Unlabeled Data
Zhao Wang, Briti Gangopadhyay, Jia-Fong Yeh, Shingo Takamatsu
0
0
Recent advancements in offline Reinforcement Learning (Offline RL) have led to an increased focus on methods based on conservative policy updates to address the Out-of-Distribution (OOD) issue. These methods typically involve adding behavior regularization or modifying the critic learning objective, focusing primarily on states or actions with substantial dataset support. However, we challenge this prevailing notion by asserting that the absence of an action or state from a dataset does not necessarily imply its suboptimality. In this paper, we propose a novel approach to tackle the OOD problem. We introduce an offline RL teacher-student framework, complemented by a policy similarity measure. This framework enables the student policy to gain insights not only from the offline RL dataset but also from the knowledge transferred by a teacher policy. The teacher policy is trained using another dataset consisting of state-action pairs, which can be viewed as practical domain knowledge acquired without direct interaction with the environment. We believe this additional knowledge is key to effectively solving the OOD issue. This research represents a significant advancement in integrating a teacher-student network into the actor-critic framework, opening new avenues for studies on knowledge transfer in offline RL and effectively addressing the OOD challenge.
6/12/2024
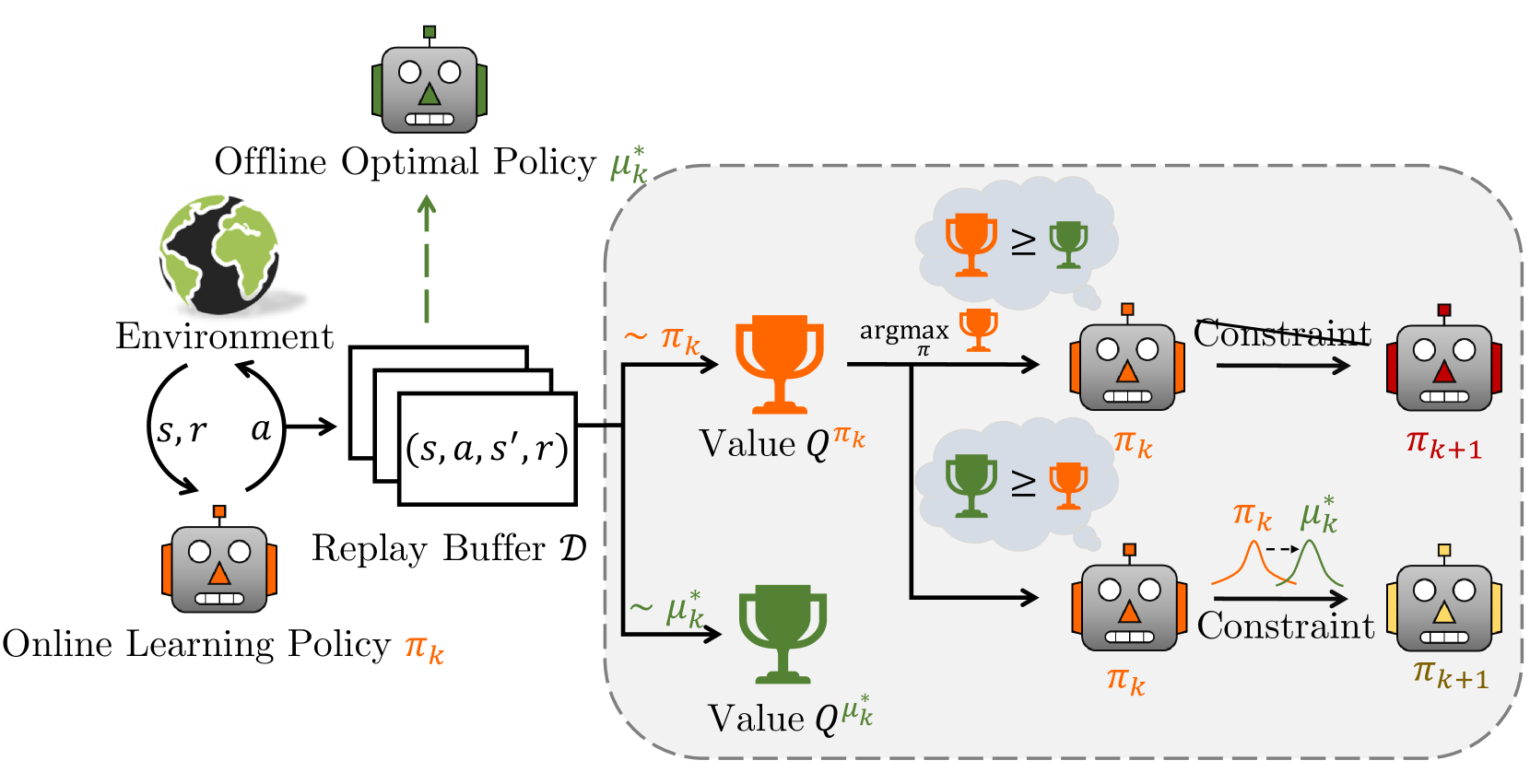
Offline-Boosted Actor-Critic: Adaptively Blending Optimal Historical Behaviors in Deep Off-Policy RL
Yu Luo, Tianying Ji, Fuchun Sun, Jianwei Zhang, Huazhe Xu, Xianyuan Zhan
0
0
Off-policy reinforcement learning (RL) has achieved notable success in tackling many complex real-world tasks, by leveraging previously collected data for policy learning. However, most existing off-policy RL algorithms fail to maximally exploit the information in the replay buffer, limiting sample efficiency and policy performance. In this work, we discover that concurrently training an offline RL policy based on the shared online replay buffer can sometimes outperform the original online learning policy, though the occurrence of such performance gains remains uncertain. This motivates a new possibility of harnessing the emergent outperforming offline optimal policy to improve online policy learning. Based on this insight, we present Offline-Boosted Actor-Critic (OBAC), a model-free online RL framework that elegantly identifies the outperforming offline policy through value comparison, and uses it as an adaptive constraint to guarantee stronger policy learning performance. Our experiments demonstrate that OBAC outperforms other popular model-free RL baselines and rivals advanced model-based RL methods in terms of sample efficiency and asymptotic performance across 53 tasks spanning 6 task suites.
5/30/2024
Efficient Offline Reinforcement Learning: The Critic is Critical
Adam Jelley, Trevor McInroe, Sam Devlin, Amos Storkey
0
0
Recent work has demonstrated both benefits and limitations from using supervised approaches (without temporal-difference learning) for offline reinforcement learning. While off-policy reinforcement learning provides a promising approach for improving performance beyond supervised approaches, we observe that training is often inefficient and unstable due to temporal difference bootstrapping. In this paper we propose a best-of-both approach by first learning the behavior policy and critic with supervised learning, before improving with off-policy reinforcement learning. Specifically, we demonstrate improved efficiency by pre-training with a supervised Monte-Carlo value-error, making use of commonly neglected downstream information from the provided offline trajectories. We find that we are able to more than halve the training time of the considered offline algorithms on standard benchmarks, and surprisingly also achieve greater stability. We further build on the importance of having consistent policy and value functions to propose novel hybrid algorithms, TD3+BC+CQL and EDAC+BC, that regularize both the actor and the critic towards the behavior policy. This helps to more reliably improve on the behavior policy when learning from limited human demonstrations. Code is available at https://github.com/AdamJelley/EfficientOfflineRL
6/21/2024