Adaptive Contrastive Decoding in Retrieval-Augmented Generation for Handling Noisy Contexts

0

Sign in to get full access
Overview
- Adaptive Contrastive Decoding (ACD) is a novel technique for handling noisy contexts in retrieval-augmented generation models.
- It aims to improve the robustness and reliability of such models by dynamically adjusting the decoding process based on the quality of the retrieved information.
- The paper presents the ACD approach and evaluates its performance on various language tasks.
Plain English Explanation
Retrieval-augmented generation models are AI systems that combine language generation with the ability to retrieve relevant information from a knowledge base. This can help them produce more informative and relevant outputs.
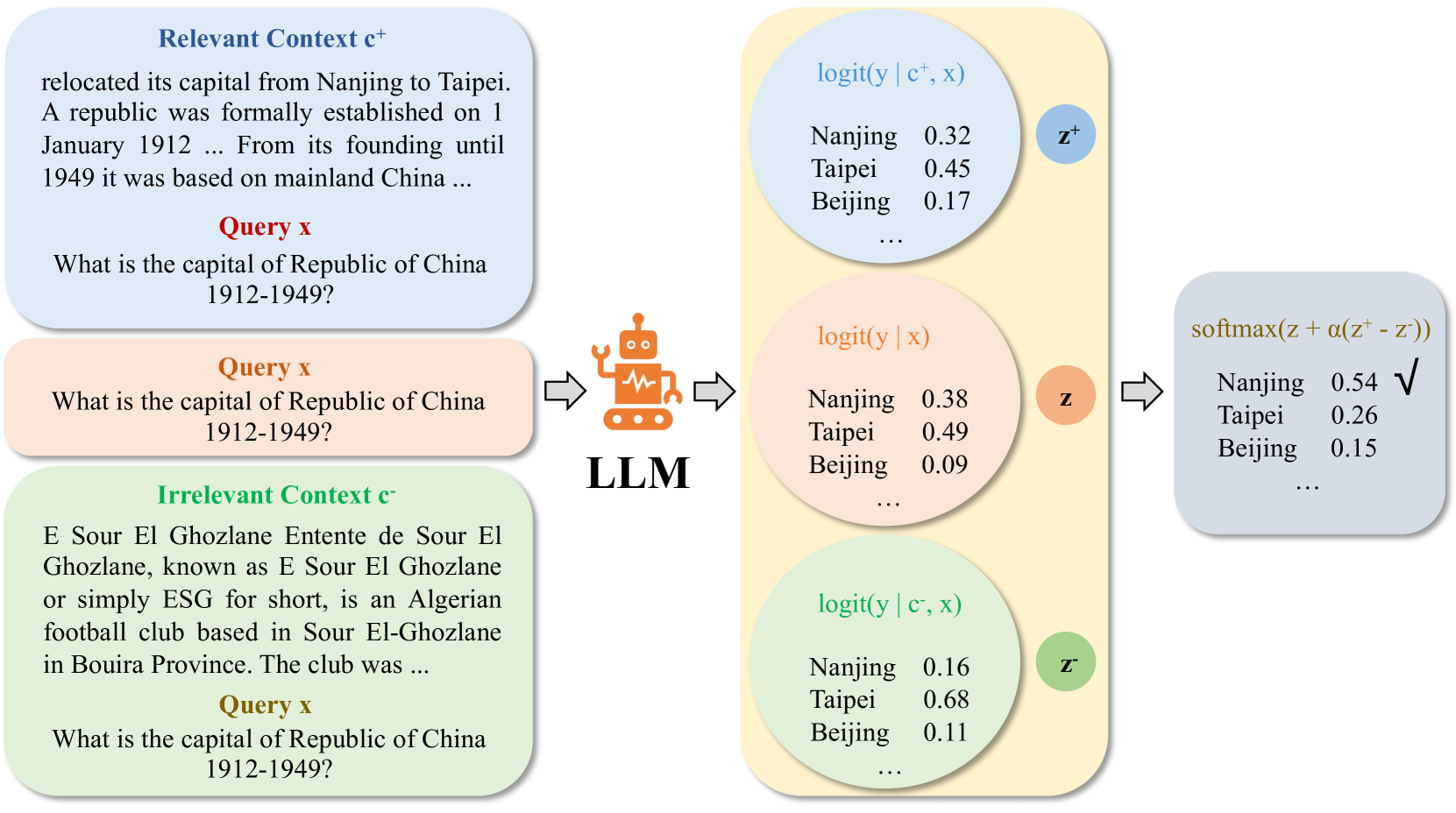
However, these models can struggle when the retrieved information is noisy or unreliable. Adaptive Contrastive Decoding (ACD) is a new technique that addresses this challenge. It works by dynamically adjusting the decoding process based on the quality of the retrieved information.
The key idea is to introduce a "contrastive" element to the decoding, where the model not only generates the most likely output but also considers alternative outputs that are similar but differ in important ways. This allows the model to be more discerning and to produce more reliable and informative results, even when the input context is noisy.
Technical Explanation
The ACD approach works by modifying the standard decoding algorithm used in retrieval-augmented generation models. Instead of simply generating the most likely output, the model also considers a set of alternative outputs that are similar but differ in important ways.
The model uses a contrastive loss function to encourage these alternative outputs to be more distinct from the most likely output. This helps the model to better understand the uncertainty and potential conflicts in the retrieved information, and to produce outputs that are more robust and reliable.
The specific implementation of ACD involves several key components, including:
- An adaptive contrastive decoding algorithm that dynamically adjusts the decoding process based on the quality of the retrieved information.
- A contrastive loss function that encourages the model to consider a diverse set of alternative outputs.
- A retrieval quality assessment module that evaluates the reliability of the retrieved information.
The paper evaluates the performance of ACD on a range of language tasks, including question answering, dialogue, and summarization. The results show that ACD can significantly improve the robustness and reliability of retrieval-augmented generation models, especially in the presence of noisy or unreliable input contexts.
Critical Analysis
The paper provides a promising approach for addressing the limitations of retrieval-augmented generation models in handling noisy contexts. The ACD technique seems to be a valuable contribution to the field, as it introduces a novel way to leverage contrastive decoding to improve the robustness and reliability of these models.
However, the paper does not address some potential limitations or areas for further research. For example, it is not clear how well ACD would scale to larger and more complex language models, or how it would perform on more diverse and challenging tasks. Additionally, the paper does not explore the computational and memory overhead associated with the contrastive decoding process, which could be an important consideration for real-world applications.
It would be useful for future research to further investigate the strengths and limitations of ACD, and to explore ways to optimize its performance and efficiency. Additionally, it would be valuable to see how ACD compares to other approaches for handling noisy contexts in retrieval-augmented generation, such as adaptive contrastive search or adversarial contrastive decoding.
Conclusion
Overall, the Adaptive Contrastive Decoding approach presented in this paper represents an important step forward in addressing the challenges of handling noisy contexts in retrieval-augmented generation models. By dynamically adjusting the decoding process based on the quality of the retrieved information, ACD can help to produce more robust and reliable outputs, with potential applications in a wide range of language-based tasks and services.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Adaptive Contrastive Decoding in Retrieval-Augmented Generation for Handling Noisy Contexts
Youna Kim, Hyuhng Joon Kim, Cheonbok Park, Choonghyun Park, Hyunsoo Cho, Junyeob Kim, Kang Min Yoo, Sang-goo Lee, Taeuk Kim
When using large language models (LLMs) in knowledge-intensive tasks, such as open-domain question answering, external context can bridge a gap between external knowledge and LLM's parametric knowledge. Recent research has been developed to amplify contextual knowledge over the parametric knowledge of LLM with contrastive decoding approaches. While these approaches could yield truthful responses when relevant context is provided, they are prone to vulnerabilities when faced with noisy contexts. We extend the scope of previous studies to encompass noisy contexts and propose adaptive contrastive decoding (ACD) to leverage contextual influence effectively. ACD demonstrates improvements in open-domain question answering tasks compared to baselines, especially in robustness by remaining undistracted by noisy contexts in retrieval-augmented generation.
Read more8/6/2024
0
Enhancing Contextual Understanding in Large Language Models through Contrastive Decoding
Zheng Zhao, Emilio Monti, Jens Lehmann, Haytham Assem
Large language models (LLMs) tend to inadequately integrate input context during text generation, relying excessively on encoded prior knowledge in model parameters, potentially resulting in generated text with factual inconsistencies or contextually unfaithful content. LLMs utilize two primary knowledge sources: 1) prior (parametric) knowledge from pretraining, and 2) contextual (non-parametric) knowledge from input prompts. The study addresses the open question of how LLMs effectively balance these knowledge sources during the generation process, specifically in the context of open-domain question answering. To address this issue, we introduce a novel approach integrating contrastive decoding with adversarial irrelevant passages as negative samples to enhance robust context grounding during generation. Notably, our method operates at inference time without requiring further training. We conduct comprehensive experiments to demonstrate its applicability and effectiveness, providing empirical evidence showcasing its superiority over existing methodologies. Our code is publicly available at: https://github.com/amazon-science/ContextualUnderstanding-ContrastiveDecoding.
Read more5/7/2024

0
AdaCAD: Adaptively Decoding to Balance Conflicts between Contextual and Parametric Knowledge
Han Wang, Archiki Prasad, Elias Stengel-Eskin, Mohit Bansal
Knowledge conflict arises from discrepancies between information in the context of a large language model (LLM) and the knowledge stored in its parameters. This can hurt performance when using standard decoding techniques, which tend to ignore the context. Existing test-time contrastive methods seek to address this by comparing the LLM's output distribution with and without the context and adjust the model according to the contrast between them. However, we find that these methods frequently misjudge the degree of conflict and struggle to handle instances that vary in their amount of conflict, with static methods over-adjusting when conflict is absent. We propose a fine-grained, instance-level approach called AdaCAD, which dynamically infers the weight of adjustment based on the degree of conflict, as measured by the Jensen-Shannon divergence between distributions representing contextual and parametric knowledge. Our experiments across four models on six diverse question-answering (QA) datasets and three summarization tasks demonstrate that our training-free adaptive method consistently outperforms other decoding methods on QA, with average accuracy gains of 14.21% (absolute) over a static contrastive baseline, and improves the factuality of summaries by 5.59 (AlignScore). Furthermore, our analysis shows that while decoding with contrastive baselines hurts performance when conflict is absent, AdaCAD mitigates these losses, making it more applicable to real-world datasets in which some examples have conflict and others do not.
Read more9/12/2024

0
Adaptive Contrastive Search: Uncertainty-Guided Decoding for Open-Ended Text Generation
Esteban Garces Arias, Julian Rodemann, Meimingwei Li, Christian Heumann, Matthias A{ss}enmacher
Decoding from the output distributions of large language models to produce high-quality text is a complex challenge in language modeling. Various approaches, such as beam search, sampling with temperature, $k-$sampling, nucleus $p-$sampling, typical decoding, contrastive decoding, and contrastive search, have been proposed to address this problem, aiming to improve coherence, diversity, as well as resemblance to human-generated text. In this study, we introduce adaptive contrastive search, a novel decoding strategy extending contrastive search by incorporating an adaptive degeneration penalty, guided by the estimated uncertainty of the model at each generation step. This strategy is designed to enhance both the creativity and diversity of the language modeling process while at the same time producing coherent and high-quality generated text output. Our findings indicate performance enhancement in both aspects, across different model architectures and datasets, underscoring the effectiveness of our method in text generation tasks. Our code base, datasets, and models are publicly available.
Read more7/29/2024