Why So Gullible? Enhancing the Robustness of Retrieval-Augmented Models against Counterfactual Noise

0
🔍
Sign in to get full access
Overview
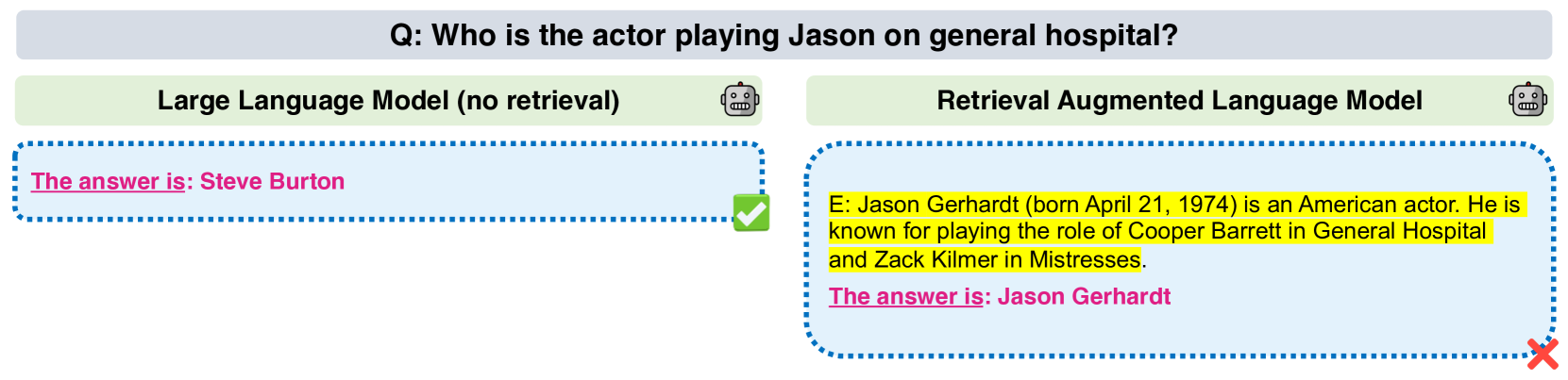
- Existing retrieval-augmented language models (LMs) assume that retrieved documents are either relevant or irrelevant to the query.
- This paper investigates a more challenging scenario where even relevant documents may contain misleading or incorrect information, leading to conflicts among the retrieved documents.
- The authors observe that existing LMs are highly sensitive to the presence of conflicting information during both fine-tuning and in-context few-shot learning.
- The paper proposes approaches to handle knowledge conflicts among retrieved documents by fine-tuning a discriminator or prompting GPT-3.5 to elicit its discriminative capability.
- The authors also provide a machine-generated, conflict-induced dataset called "MacNoise" to encourage further research in this direction.
Plain English Explanation
Language models (LMs) are powerful tools that can understand and generate human-like text. However, when these models rely on retrieving information from external sources, they can run into a problem. Even the relevant documents they retrieve may contain incorrect or misleading information, leading to conflicts between the retrieved documents.
This paper looks at this challenge and proposes ways to make LMs more robust to these conflicts. The researchers found that existing LMs are quite fragile when faced with conflicting information, both during the training process (fine-tuning) and when using the model to answer questions (in-context few-shot learning).
To address this, the paper suggests two approaches: fine-tuning a discriminator to identify and handle conflicting information, or prompting the GPT-3.5 model to bring out its own ability to distinguish between reliable and unreliable information. The researchers found that these methods significantly improve the model's robustness to conflicting information.
Additionally, the paper introduces a new dataset called "MacNoise" that contains machine-generated content with intentional conflicts. This dataset can be used to further study how language models can become more reliable in the face of potential misinformation.
Technical Explanation
The paper investigates a more challenging scenario for retrieval-augmented language models (LMs) than the typical assumption of a clear dichotomy between query-relevant and irrelevant retrieved documents. The authors observe that even the relevant documents may contain misleading or incorrect information, leading to conflicts among the retrieved documents. This can negatively influence the model's decisions by introducing noise.
The researchers find that existing LMs are highly sensitive to the presence of conflicting information, both during the fine-tuning process and in-context few-shot learning. To address this, they propose two approaches:
-
Fine-tuning a discriminator: The authors fine-tune a discriminator to explicitly identify and handle conflicting information among the retrieved documents. This helps the model become more robust to knowledge conflicts.
-
Prompting GPT-3.5: The researchers prompt GPT-3.5 to elicit its inherent discriminative capability, enabling the model to better distinguish reliable from unreliable information.
The paper's empirical results on open-domain question-answering tasks show that these approaches significantly enhance the model's robustness to conflicting information. The authors also explore incorporating the fine-tuned discriminator's decision into the in-context learning process, proposing a way to combine the benefits of two disparate learning schemes.
Finally, the paper introduces "MacNoise," a machine-generated, conflict-induced dataset, to encourage further research in this direction and help develop more reliable retrieval-augmented language models.
Critical Analysis
The paper presents a thoughtful exploration of an important challenge facing retrieval-augmented language models: the presence of conflicting information within the retrieved document set. The authors' observations about the brittleness of existing models to such conflicts are well-supported, and their proposed approaches to enhance model robustness are promising.
One potential limitation of the study is the reliance on machine-generated data (the "MacNoise" dataset) to simulate conflicting information. While this allows for greater control and scalability, it may not fully capture the nuances and complexities of real-world scenarios where conflicting information arises from diverse human sources. Further research may be needed to understand how these methods perform on more naturalistic data.
Additionally, the paper focuses on open-domain question-answering tasks, which may not be representative of all potential applications of retrieval-augmented language models. It would be valuable to explore the efficacy of the proposed approaches in other domains, such as dialogue systems or specialized knowledge tasks, where the handling of conflicting information may be equally critical.
Overall, this paper makes a valuable contribution to the field by highlighting an important challenge and proposing promising solutions. The insights and techniques presented here could inform the development of more robust and reliable retrieval-augmented language models that can better navigate the complexities of real-world information.
Conclusion
This paper investigates a more challenging scenario for retrieval-augmented language models, where even the relevant documents retrieved may contain misleading or incorrect information, leading to conflicts that can negatively impact model decisions. The authors observe that existing LMs are highly sensitive to such conflicts and propose two approaches to enhance model robustness: fine-tuning a discriminator and prompting GPT-3.5 to elicit its discriminative capability.
The empirical results demonstrate that these methods significantly improve the model's ability to handle conflicting information, both during fine-tuning and in-context few-shot learning. The introduction of the "MacNoise" dataset further encourages research in this direction, aiming to develop more reliable retrieval-augmented language models that can navigate the challenges of real-world information with greater resilience.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
0
Why So Gullible? Enhancing the Robustness of Retrieval-Augmented Models against Counterfactual Noise
Giwon Hong, Jeonghwan Kim, Junmo Kang, Sung-Hyon Myaeng, Joyce Jiyoung Whang
Most existing retrieval-augmented language models (LMs) assume a naive dichotomy within a retrieved document set: query-relevance and irrelevance. Our work investigates a more challenging scenario in which even the relevant documents may contain misleading or incorrect information, causing conflict among the retrieved documents and thereby negatively influencing model decisions as noise. We observe that existing LMs are highly brittle to the presence of conflicting information in both the fine-tuning and in-context few-shot learning scenarios. We propose approaches for handling knowledge conflicts among retrieved documents by explicitly fine-tuning a discriminator or prompting GPT-3.5 to elicit its discriminative capability. Our empirical results on open-domain QA show that these approaches significantly enhance model robustness. We also provide our findings on incorporating the fine-tuned discriminator's decision into the in-context learning process, proposing a way to exploit the benefits of two disparate learning schemes. Alongside our findings, we provide MacNoise, a machine-generated, conflict-induced dataset to further encourage research in this direction.
Read more6/11/2024

0
Towards Building a Robust Knowledge Intensive Question Answering Model with Large Language Models
Hong Xingyun Hong, Shao Yan Shao, Wang Zhilin Wang, Duan Manni Duan, Jin Xiongnan
The development of LLMs has greatly enhanced the intelligence and fluency of question answering, while the emergence of retrieval enhancement has enabled models to better utilize external information. However, the presence of noise and errors in retrieved information poses challenges to the robustness of LLMs. In this work, to evaluate the model's performance under multiple interferences, we first construct a dataset based on machine reading comprehension datasets simulating various scenarios, including critical information absence, noise, and conflicts. To address the issue of model accuracy decline caused by noisy external information, we propose a data augmentation-based fine-tuning method to enhance LLM's robustness against noise. Additionally, contrastive learning approach is utilized to preserve the model's discrimination capability of external information. We have conducted experiments on both existing LLMs and our approach, the results are evaluated by GPT-4, which indicates that our proposed methods improve model robustness while strengthening the model's discrimination capability.
Read more9/11/2024
💬
0
Assessing Implicit Retrieval Robustness of Large Language Models
Xiaoyu Shen, Rexhina Blloshmi, Dawei Zhu, Jiahuan Pei, Wei Zhang
Retrieval-augmented generation has gained popularity as a framework to enhance large language models with external knowledge. However, its effectiveness hinges on the retrieval robustness of the model. If the model lacks retrieval robustness, its performance is constrained by the accuracy of the retriever, resulting in significant compromises when the retrieved context is irrelevant. In this paper, we evaluate the implicit retrieval robustness of various large language models, instructing them to directly output the final answer without explicitly judging the relevance of the retrieved context. Our findings reveal that fine-tuning on a mix of gold and distracting context significantly enhances the model's robustness to retrieval inaccuracies, while still maintaining its ability to extract correct answers when retrieval is accurate. This suggests that large language models can implicitly handle relevant or irrelevant retrieved context by learning solely from the supervision of the final answer in an end-to-end manner. Introducing an additional process for explicit relevance judgment can be unnecessary and disrupts the end-to-end approach.
Read more6/27/2024
0
Making Retrieval-Augmented Language Models Robust to Irrelevant Context
Ori Yoran, Tomer Wolfson, Ori Ram, Jonathan Berant
Retrieval-augmented language models (RALMs) hold promise to produce language understanding systems that are are factual, efficient, and up-to-date. An important desideratum of RALMs, is that retrieved information helps model performance when it is relevant, and does not harm performance when it is not. This is particularly important in multi-hop reasoning scenarios, where misuse of irrelevant evidence can lead to cascading errors. However, recent work has shown that retrieval augmentation can sometimes have a negative effect on performance. In this work, we present a thorough analysis on five open-domain question answering benchmarks, characterizing cases when retrieval reduces accuracy. We then propose two methods to mitigate this issue. First, a simple baseline that filters out retrieved passages that do not entail question-answer pairs according to a natural language inference (NLI) model. This is effective in preventing performance reduction, but at a cost of also discarding relevant passages. Thus, we propose a method for automatically generating data to fine-tune the language model to properly leverage retrieved passages, using a mix of relevant and irrelevant contexts at training time. We empirically show that even 1,000 examples suffice to train the model to be robust to irrelevant contexts while maintaining high performance on examples with relevant ones.
Read more5/7/2024