Adversarial Contrastive Decoding: Boosting Safety Alignment of Large Language Models via Opposite Prompt Optimization

0

Sign in to get full access
Overview
- This paper introduces a novel approach called "Adversarial Contrastive Decoding" (ACD) to improve the safety alignment of large language models.
- The key idea is to optimize language models to generate outputs that are the opposite of unsafe prompts, in addition to optimizing for the original prompts.
- This "opposite prompt optimization" aims to push the model away from generating harmful content, even when prompted with adversarial inputs.
Plain English Explanation
Large language models, like GPT-3, have become incredibly powerful at generating human-like text. However, there are concerns that these models could be misused to create harmful or dangerous content, even when prompted with innocuous-seeming inputs.
The researchers behind this paper wanted to find a way to make these language models more "safety-aligned" - in other words, to make them less likely to generate unsafe or undesirable outputs, even when faced with prompts that are intended to elicit such content.
Their solution, Adversarial Contrastive Decoding (ACD), involves training the language model to not only generate outputs that match the original prompt, but also outputs that are the complete opposite of what an unsafe prompt would produce. This "opposite prompt optimization" essentially teaches the model to avoid generating harmful content, even when faced with prompts that are designed to elicit it.
By optimizing the model in this way, the researchers were able to enhance the contextual understanding of large language models and boost its safety alignment, making it less likely to generate problematic outputs, even when presented with adversarial prompts.
Technical Explanation
The key innovation of this paper is the Adversarial Contrastive Decoding (ACD) approach, which builds on previous work in improving the generation of adversarial examples against safety-aligned models.
The core idea is to train the language model not just to generate outputs that match the original prompt, but also to generate outputs that are the opposite of what an unsafe prompt would produce. This "opposite prompt optimization" is achieved by introducing a contrastive loss term that pushes the model to generate outputs that are dissimilar to the outputs obtained from unsafe prompts.
Specifically, the researchers first identify a set of "unsafe" prompts that are known to elicit harmful outputs from the language model. They then train the model to generate outputs that are the opposite of these unsafe prompts, in addition to optimizing for the original prompts.
The researchers evaluate their approach on a range of safety-critical tasks, including emulating disalignment in safety-aligned large language models and generating text that is less likely to contain harmful content. Their results show that the ACD approach is effective at improving the safety alignment of the language model, making it less likely to generate unsafe outputs, even when presented with adversarial prompts.
Critical Analysis
One potential limitation of the ACD approach is that it relies on the researchers having a pre-defined set of "unsafe" prompts that they can use for the opposite prompt optimization. In a real-world setting, it may be challenging to anticipate all the possible ways that a language model could be misused, and the researchers acknowledge that their approach may not be able to address all possible safety concerns.
Additionally, the researchers note that their approach could potentially have unintended consequences, such as making the language model less capable at generating certain types of content that may not be inherently unsafe, but could still be valuable for certain applications.
Overall, while the ACD approach appears to be a promising step towards improving the safety alignment of large language models, further research is needed to address these limitations and to explore other approaches to this important challenge.
Conclusion
This paper introduces a novel technique called Adversarial Contrastive Decoding (ACD) that aims to improve the safety alignment of large language models. By optimizing the model to generate outputs that are the opposite of unsafe prompts, in addition to the original prompts, the researchers were able to boost the safety and instruction alignment of the language model, making it less likely to generate harmful content even when faced with adversarial inputs.
While the ACD approach has some limitations, it represents an important step forward in the ongoing effort to develop language models that are more reliable, trustworthy, and aligned with human values and safety concerns. As the field of natural language processing continues to advance, techniques like ACD will likely play an increasingly important role in ensuring that these powerful technologies are used in ways that benefit society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Adversarial Contrastive Decoding: Boosting Safety Alignment of Large Language Models via Opposite Prompt Optimization
Zhengyue Zhao, Xiaoyun Zhang, Kaidi Xu, Xing Hu, Rui Zhang, Zidong Du, Qi Guo, Yunji Chen
With the widespread application of Large Language Models (LLMs), it has become a significant concern to ensure their safety and prevent harmful responses. While current safe-alignment methods based on instruction fine-tuning and Reinforcement Learning from Human Feedback (RLHF) can effectively reduce harmful responses from LLMs, they often require high-quality datasets and heavy computational overhead during model training. Another way to align language models is to modify the logit of tokens in model outputs without heavy training. Recent studies have shown that contrastive decoding can enhance the performance of language models by reducing the likelihood of confused tokens. However, these methods require the manual selection of contrastive models or instruction templates. To this end, we propose Adversarial Contrastive Decoding (ACD), an optimization-based framework to generate two opposite system prompts for prompt-based contrastive decoding. ACD only needs to apply a lightweight prompt tuning on a rather small anchor dataset (< 3 min for each model) without training the target model. Experiments conducted on extensive models and benchmarks demonstrate that the proposed method achieves much better safety performance than previous model training-free decoding methods without sacrificing its original generation ability.
Read more6/26/2024
💬
0
ROSE Doesn't Do That: Boosting the Safety of Instruction-Tuned Large Language Models with Reverse Prompt Contrastive Decoding
Qihuang Zhong, Liang Ding, Juhua Liu, Bo Du, Dacheng Tao
With the development of instruction-tuned large language models (LLMs), improving the safety of LLMs has become more critical. However, the current approaches for aligning the LLMs output with expected safety usually require substantial training efforts, e.g., high-quality safety data and expensive computational resources, which are costly and inefficient. To this end, we present reverse prompt contrastive decoding (ROSE), a simple-yet-effective method to directly boost the safety of existing instruction-tuned LLMs without any additional training. The principle of ROSE is to improve the probability of desired safe output via suppressing the undesired output induced by the carefully-designed reverse prompts. Experiments on 6 safety and 2 general-purpose tasks show that, our ROSE not only brings consistent and significant safety improvements (up to +13.8% safety score) upon 5 types of instruction-tuned LLMs, but also benefits the general-purpose ability of LLMs. In-depth analyses explore the underlying mechanism of ROSE, and reveal when and where to use it.
Read more6/18/2024
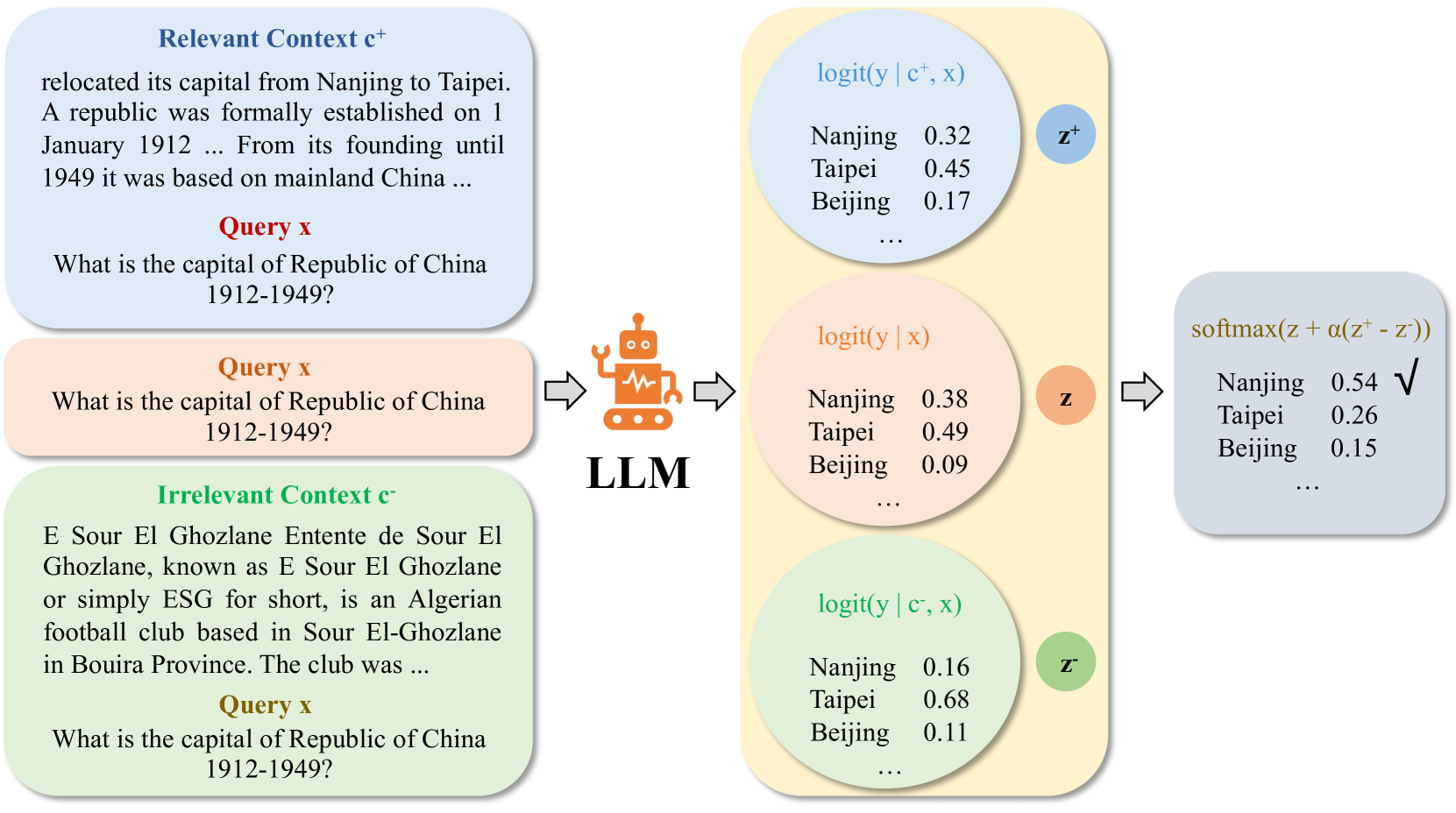
0
Enhancing Contextual Understanding in Large Language Models through Contrastive Decoding
Zheng Zhao, Emilio Monti, Jens Lehmann, Haytham Assem
Large language models (LLMs) tend to inadequately integrate input context during text generation, relying excessively on encoded prior knowledge in model parameters, potentially resulting in generated text with factual inconsistencies or contextually unfaithful content. LLMs utilize two primary knowledge sources: 1) prior (parametric) knowledge from pretraining, and 2) contextual (non-parametric) knowledge from input prompts. The study addresses the open question of how LLMs effectively balance these knowledge sources during the generation process, specifically in the context of open-domain question answering. To address this issue, we introduce a novel approach integrating contrastive decoding with adversarial irrelevant passages as negative samples to enhance robust context grounding during generation. Notably, our method operates at inference time without requiring further training. We conduct comprehensive experiments to demonstrate its applicability and effectiveness, providing empirical evidence showcasing its superiority over existing methodologies. Our code is publicly available at: https://github.com/amazon-science/ContextualUnderstanding-ContrastiveDecoding.
Read more5/7/2024

0
Adaptive Contrastive Decoding in Retrieval-Augmented Generation for Handling Noisy Contexts
Youna Kim, Hyuhng Joon Kim, Cheonbok Park, Choonghyun Park, Hyunsoo Cho, Junyeob Kim, Kang Min Yoo, Sang-goo Lee, Taeuk Kim
When using large language models (LLMs) in knowledge-intensive tasks, such as open-domain question answering, external context can bridge a gap between external knowledge and LLM's parametric knowledge. Recent research has been developed to amplify contextual knowledge over the parametric knowledge of LLM with contrastive decoding approaches. While these approaches could yield truthful responses when relevant context is provided, they are prone to vulnerabilities when faced with noisy contexts. We extend the scope of previous studies to encompass noisy contexts and propose adaptive contrastive decoding (ACD) to leverage contextual influence effectively. ACD demonstrates improvements in open-domain question answering tasks compared to baselines, especially in robustness by remaining undistracted by noisy contexts in retrieval-augmented generation.
Read more8/6/2024