Adaptive Reinforcement Learning Planning: Harnessing Large Language Models for Complex Information Extraction
2406.11455
0
0
Abstract
Existing research on large language models (LLMs) shows that they can solve information extraction tasks through multi-step planning. However, their extraction behavior on complex sentences and tasks is unstable, emerging issues such as false positives and missing elements. We observe that decomposing complex extraction tasks and extracting them step by step can effectively improve LLMs' performance, and the extraction orders of entities significantly affect the final results of LLMs. This paper proposes a two-stage multi-step method for LLM-based information extraction and adopts the RL framework to execute the multi-step planning. We regard sequential extraction as a Markov decision process, build an LLM-based extraction environment, design a decision module to adaptively provide the optimal order for sequential entity extraction on different sentences, and utilize the DDQN algorithm to train the decision model. We also design the rewards and evaluation metrics suitable for the extraction results of LLMs. We conduct extensive experiments on multiple public datasets to demonstrate the effectiveness of our method in improving the information extraction capabilities of LLMs.
Create account to get full access
Overview
- This paper explores the use of large language models (LLMs) for complex information extraction and reinforcement learning (RL) planning.
- The researchers propose an Adaptive Reinforcement Learning Planning (ARLP) framework that leverages LLMs to address challenging information extraction tasks.
- The paper investigates how LLMs can be harnessed to improve RL planning and decision-making in complex environments.
Plain English Explanation
Large language models (LLMs) like GPT-3 have shown impressive abilities in generating human-like text and understanding natural language. This paper explores how these powerful AI models can be used to tackle complex information extraction and planning tasks, which are crucial for real-world applications like robotics, decision-making, and task automation.
The researchers developed an Adaptive Reinforcement Learning Planning (ARLP) framework that combines LLMs with reinforcement learning (RL) techniques. RL is a type of machine learning where an agent learns to make decisions by interacting with an environment and receiving rewards or penalties for its actions.
In the ARLP framework, the LLM is used to extract and process complex information from the environment, helping the RL agent make more informed decisions. This is particularly useful in scenarios where the environment is complex and the available information is ambiguous or incomplete. By leveraging the language understanding capabilities of LLMs, the RL agent can better navigate these challenging situations and make more effective plans.
The researchers also investigate how LLMs can be used as generative models to extract relevant information from unstructured data sources, such as documents or dialogues. This allows the RL agent to gather the necessary information to make informed decisions, even in environments where the relevant data is not neatly organized or easily accessible.
Overall, this research aims to unlock the potential of LLMs for complex problem-solving by integrating them with reinforcement learning techniques. By combining the language understanding and generation capabilities of LLMs with the decision-making and planning abilities of RL, the researchers hope to create more robust and adaptable AI systems that can tackle a wide range of real-world challenges.
Technical Explanation
The paper presents the Adaptive Reinforcement Learning Planning (ARLP) framework, which leverages large language models (LLMs) to enhance reinforcement learning (RL) planning and decision-making in complex environments.
The researchers first investigate how LLMs can be used as generative models to extract relevant information from unstructured data sources, such as documents or dialogues. This allows the RL agent to gather the necessary information to make informed decisions, even in environments where the relevant data is not neatly organized or easily accessible.
Next, the paper explores how LLMs can be integrated with RL agents to improve their planning and decision-making capabilities. The ARLP framework leverages the language understanding and reasoning abilities of LLMs to help the RL agent navigate complex environments, make more informed decisions, and generate effective plans of action.
The researchers conducted experiments to evaluate the performance of the ARLP framework on various information extraction and planning tasks. The results demonstrate that the integration of LLMs with RL can lead to significant improvements in the agent's ability to solve complex problems, compared to traditional RL approaches.
Moreover, the paper presents evidence suggesting that LLMs can be learnable planners themselves, capable of generating effective action sequences to achieve desired goals. This finding further highlights the potential of LLMs to serve as powerful tools for complex problem-solving and decision-making.
Critical Analysis
The paper presents a compelling approach to leveraging the capabilities of large language models (LLMs) for complex information extraction and reinforcement learning (RL) planning. The researchers have thoughtfully integrated LLMs into the RL framework, addressing the challenge of gathering and processing relevant information in complex environments.
One potential limitation of the research is the reliance on specific language models and RL algorithms, which may limit the generalizability of the findings. It would be interesting to see how the ARLP framework performs with a more diverse set of LLMs and RL techniques, as well as in a broader range of real-world applications.
Additionally, the paper does not delve deeply into the potential biases and limitations of LLMs when used in decision-making and planning contexts. It would be valuable for the researchers to address these concerns and explore strategies for mitigating any negative impacts on the ARLP system's reliability and fairness.
Despite these potential areas for further exploration, the paper makes a significant contribution to the field by demonstrating the power of combining LLMs and RL for complex problem-solving. The findings have important implications for the development of more capable and adaptable AI systems that can tackle a wide range of real-world challenges.
Conclusion
This paper presents the Adaptive Reinforcement Learning Planning (ARLP) framework, which leverages the capabilities of large language models (LLMs) to enhance reinforcement learning (RL) planning and decision-making in complex environments. The researchers have demonstrated how LLMs can be used as generative models to extract relevant information from unstructured data, and how they can be integrated with RL agents to improve their planning and decision-making abilities.
The findings of this research highlight the significant potential of combining LLMs and RL for complex problem-solving, with implications for a wide range of applications, from robotics and automation to decision support systems. As the capabilities of both LLMs and RL continue to evolve, this work serves as an important step in unlocking the full potential of these AI technologies for addressing real-world challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Reinforcement Learning Problem Solving with Large Language Models
Sina Gholamian, Domingo Huh
0
0
Large Language Models (LLMs) encapsulate an extensive amount of world knowledge, and this has enabled their application in various domains to improve the performance of a variety of Natural Language Processing (NLP) tasks. This has also facilitated a more accessible paradigm of conversation-based interactions between humans and AI systems to solve intended problems. However, one interesting avenue that shows untapped potential is the use of LLMs as Reinforcement Learning (RL) agents to enable conversational RL problem solving. Therefore, in this study, we explore the concept of formulating Markov Decision Process-based RL problems as LLM prompting tasks. We demonstrate how LLMs can be iteratively prompted to learn and optimize policies for specific RL tasks. In addition, we leverage the introduced prompting technique for episode simulation and Q-Learning, facilitated by LLMs. We then show the practicality of our approach through two detailed case studies for Research Scientist and Legal Matter Intake workflows.
4/30/2024
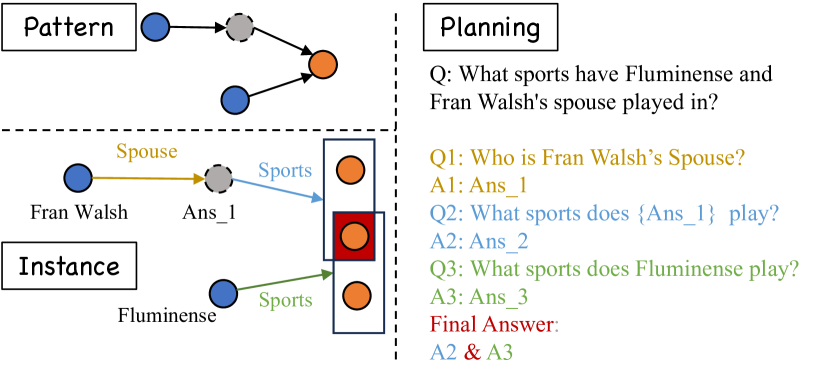
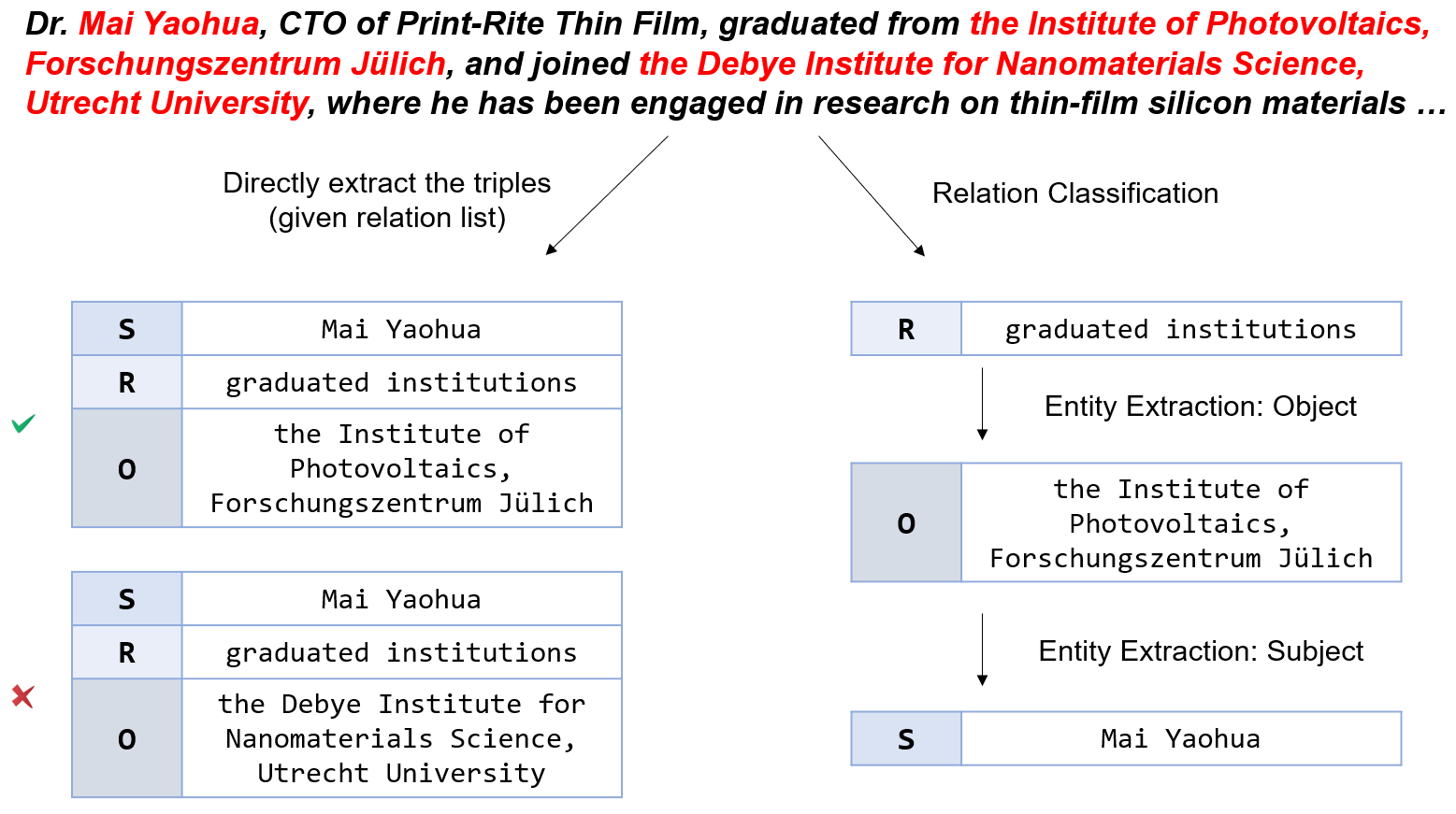
Learning to Plan for Retrieval-Augmented Large Language Models from Knowledge Graphs
Junjie Wang, Mingyang Chen, Binbin Hu, Dan Yang, Ziqi Liu, Yue Shen, Peng Wei, Zhiqiang Zhang, Jinjie Gu, Jun Zhou, Jeff Z. Pan, Wen Zhang, Huajun Chen
0
0
Improving the performance of large language models (LLMs) in complex question-answering (QA) scenarios has always been a research focal point. Recent studies have attempted to enhance LLMs' performance by combining step-wise planning with external retrieval. While effective for advanced models like GPT-3.5, smaller LLMs face challenges in decomposing complex questions, necessitating supervised fine-tuning. Previous work has relied on manual annotation and knowledge distillation from teacher LLMs, which are time-consuming and not accurate enough. In this paper, we introduce a novel framework for enhancing LLMs' planning capabilities by using planning data derived from knowledge graphs (KGs). LLMs fine-tuned with this data have improved planning capabilities, better equipping them to handle complex QA tasks that involve retrieval. Evaluations on multiple datasets, including our newly proposed benchmark, highlight the effectiveness of our framework and the benefits of KG-derived planning data.
6/21/2024
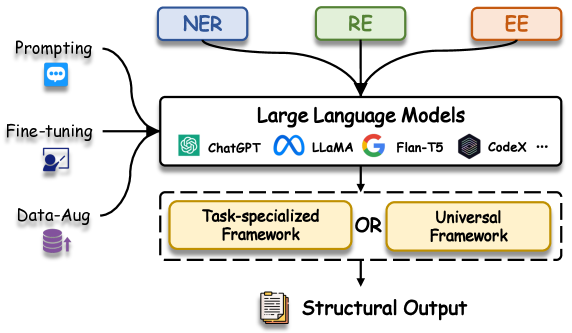
Large Language Models for Generative Information Extraction: A Survey
Derong Xu, Wei Chen, Wenjun Peng, Chao Zhang, Tong Xu, Xiangyu Zhao, Xian Wu, Yefeng Zheng, Yang Wang, Enhong Chen
0
0
Information extraction (IE) aims to extract structural knowledge (such as entities, relations, and events) from plain natural language texts. Recently, generative Large Language Models (LLMs) have demonstrated remarkable capabilities in text understanding and generation, allowing for generalization across various domains and tasks. As a result, numerous works have been proposed to harness abilities of LLMs and offer viable solutions for IE tasks based on a generative paradigm. To conduct a comprehensive systematic review and exploration of LLM efforts for IE tasks, in this study, we survey the most recent advancements in this field. We first present an extensive overview by categorizing these works in terms of various IE subtasks and learning paradigms, then we empirically analyze the most advanced methods and discover the emerging trend of IE tasks with LLMs. Based on thorough review conducted, we identify several insights in technique and promising research directions that deserve further exploration in future studies. We maintain a public repository and consistently update related resources at: url{https://github.com/quqxui/Awesome-LLM4IE-Papers}.
6/5/2024

Efficient Sequential Decision Making with Large Language Models
Dingyang Chen, Qi Zhang, Yinglun Zhu
0
0
This paper focuses on extending the success of large language models (LLMs) to sequential decision making. Existing efforts either (i) re-train or finetune LLMs for decision making, or (ii) design prompts for pretrained LLMs. The former approach suffers from the computational burden of gradient updates, and the latter approach does not show promising results. In this paper, we propose a new approach that leverages online model selection algorithms to efficiently incorporate LLMs agents into sequential decision making. Statistically, our approach significantly outperforms both traditional decision making algorithms and vanilla LLM agents. Computationally, our approach avoids the need for expensive gradient updates of LLMs, and throughout the decision making process, it requires only a small number of LLM calls. We conduct extensive experiments to verify the effectiveness of our proposed approach. As an example, on a large-scale Amazon dataset, our approach achieves more than a $6$x performance gain over baselines while calling LLMs in only $1.5$% of the time steps.
6/19/2024