Adaptive Split Balancing for Optimal Random Forest

0
🗣️
Sign in to get full access
Overview
- A new random forest algorithm called Adaptive Split-Balancing Forest (ASBF) is proposed.
- ASBF uses a novel adaptive split-balancing method to construct trees, rather than the widely-used random feature selection.
- The algorithm achieves minimax optimality under the Lipschitz class and the broader Hölder class of problems.
- The authors identify that over-reliance on randomness in tree construction can compromise the approximation power of trees, leading to suboptimal results.
Plain English Explanation
The paper introduces a new version of the random forest algorithm, called the Adaptive Split-Balancing Forest (ASBF). Random forests are a popular machine learning technique that use an ensemble of decision trees to make predictions.
Typically, random forests build each tree by randomly selecting a subset of features to consider at each split. The ASBF algorithm proposes a different approach - instead of random feature selection, it uses a permutation-based balanced splitting criterion. This means that when building each tree, the algorithm systematically considers all features and selects the one that best balances the data into two evenly-sized subsets.
The authors explain that over-reliance on randomness in the tree construction process can actually reduce the approximation power of the trees, leading to suboptimal results. In contrast, the less random, permutation-based approach used in ASBF demonstrates optimality over a wide range of models.
In addition, the paper shows that the localized version of ASBF, which fits local regressions at the leaf nodes, can achieve the minimax rate under a broad class of statistical problems. This means it can perform very well even for complex, non-smooth data distributions.
Technical Explanation
The key innovation in the ASBF algorithm is the use of a novel adaptive split-balancing method to construct the trees, rather than the commonly-used random feature selection approach. Specifically, the algorithm employs a permutation-based balanced splitting criterion that systematically considers all features and selects the one that best splits the data into two evenly-sized subsets.
The authors prove that this less random, permutation-based tree construction method achieves minimax optimality under the Lipschitz class of problems. They also introduce a localized version of ASBF that fits local regressions at the leaf nodes, and show that this variant attains the minimax rate under the broad Hölder class $\mathcal{H}^{q,\beta}$ of problems for any $q\in\mathbb{N}$ and $\beta\in(0,1]$.
The paper identifies that over-reliance on auxiliary randomness in tree construction can actually compromise the approximation power of the trees, leading to suboptimal performance. In contrast, the proposed ASBF method demonstrates strong theoretical guarantees and improved dimensionality dependence in average treatment effect estimation problems.
Critical Analysis
The paper provides a solid theoretical analysis of the proposed ASBF algorithm and its variants, establishing strong optimality guarantees under various problem settings. However, the authors acknowledge that the practical implementation of the algorithm may be more computationally intensive than standard random forests, due to the need to systematically consider all features at each split.
Additionally, while the paper demonstrates superior performance of ASBF in simulations and real-world applications, it would be useful to see a more extensive empirical evaluation across a broader range of datasets and tasks. This could help better understand the practical tradeoffs and limitations of the approach.
It would also be valuable for the authors to discuss potential limitations or caveats of the ASBF method, such as its sensitivity to outliers or its performance in the presence of highly correlated features. Exploring these aspects could provide a more well-rounded understanding of the algorithm's strengths and weaknesses.
Conclusion
The proposed Adaptive Split-Balancing Forest (ASBF) algorithm represents a novel and theoretically-grounded approach to constructing random forests. By using a permutation-based balanced splitting criterion instead of random feature selection, ASBF can achieve minimax optimality under a broad range of statistical problems.
The key insight is that over-reliance on randomness in tree construction can actually compromise the approximation power of the trees, leading to suboptimal performance. The ASBF method addresses this issue, demonstrating strong theoretical guarantees and improved practical performance in simulations and real-world applications.
While the computational complexity of the algorithm may be a practical consideration, the theoretical and empirical results presented in this paper suggest that the ASBF approach is a promising direction for improving the performance of random forests, especially for complex, non-smooth data distributions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
Adaptive Split Balancing for Optimal Random Forest
Yuqian Zhang, Weijie Ji, Jelena Bradic
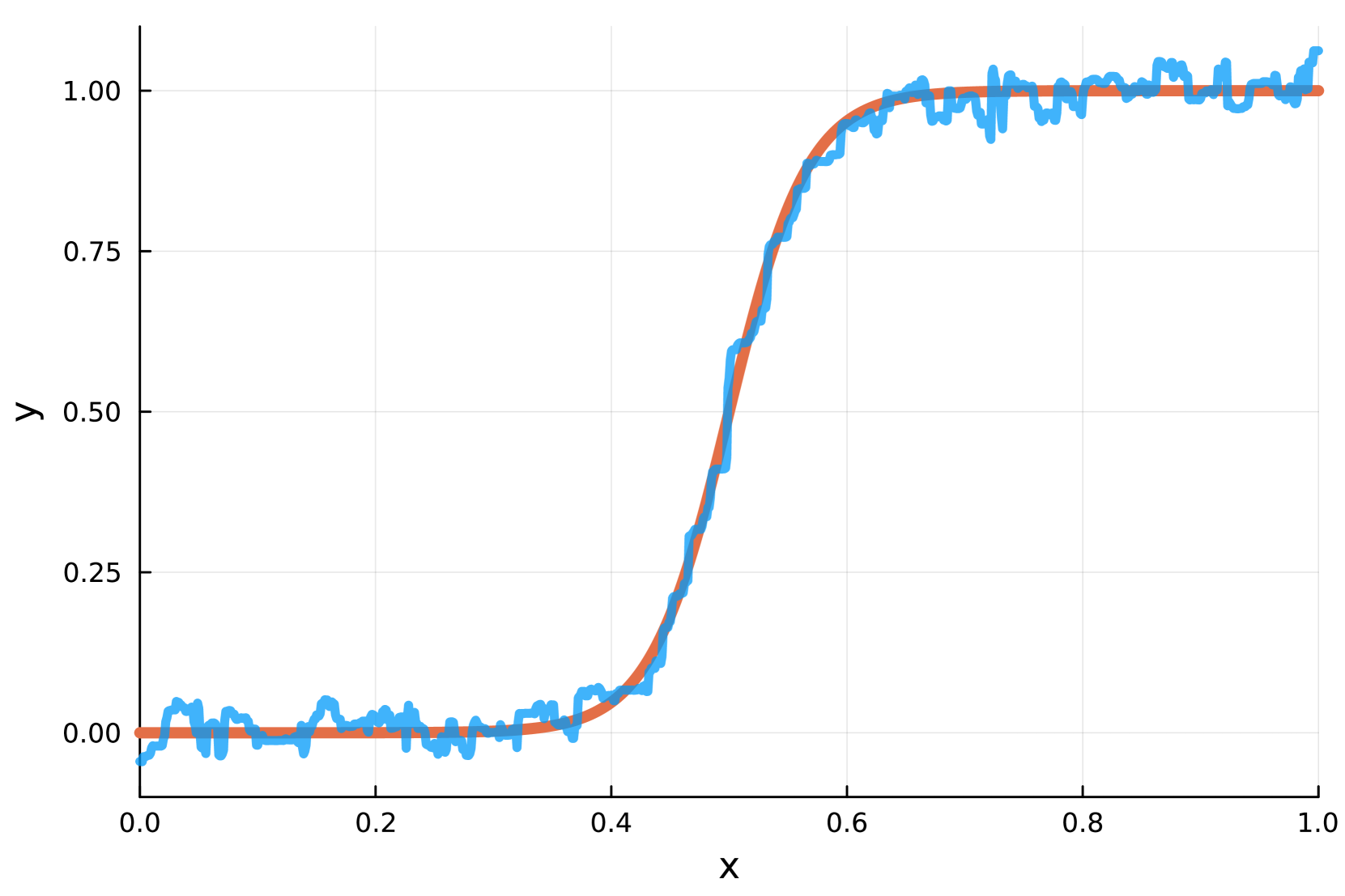
In this paper, we propose a new random forest algorithm that constructs the trees using a novel adaptive split-balancing method. Rather than relying on the widely-used random feature selection, we propose a permutation-based balanced splitting criterion. The adaptive split balancing forest (ASBF), achieves minimax optimality under the Lipschitz class. Its localized version, which fits local regressions at the leaf level, attains the minimax rate under the broad Holder class $mathcal{H}^{q,beta}$ of problems for any $qinmathbb{N}$ and $betain(0,1]$. We identify that over-reliance on auxiliary randomness in tree construction may compromise the approximation power of trees, leading to suboptimal results. Conversely, the proposed less random, permutation-based approach demonstrates optimality over a wide range of models. Although random forests are known to perform well empirically, their theoretical convergence rates are slow. Simplified versions that construct trees without data dependence offer faster rates but lack adaptability during tree growth. Our proposed method achieves optimality in simple, smooth scenarios while adaptively learning the tree structure from the data. Additionally, we establish uniform upper bounds and demonstrate that ASBF improves dimensionality dependence in average treatment effect estimation problems. Simulation studies and real-world applications demonstrate our methods' superior performance over existing random forests.
Read more9/4/2024
0
Alpha-Trimming: Locally Adaptive Tree Pruning for Random Forests
Nikola Surjanovic, Andrew Henrey, Thomas M. Loughin
We demonstrate that adaptively controlling the size of individual regression trees in a random forest can improve predictive performance, contrary to the conventional wisdom that trees should be fully grown. A fast pruning algorithm, alpha-trimming, is proposed as an effective approach to pruning trees within a random forest, where more aggressive pruning is performed in regions with a low signal-to-noise ratio. The amount of overall pruning is controlled by adjusting the weight on an information criterion penalty as a tuning parameter, with the standard random forest being a special case of our alpha-trimmed random forest. A remarkable feature of alpha-trimming is that its tuning parameter can be adjusted without refitting the trees in the random forest once the trees have been fully grown once. In a benchmark suite of 46 example data sets, mean squared prediction error is often substantially lowered by using our pruning algorithm and is never substantially increased compared to a random forest with fully-grown trees at default parameter settings.
Read more8/15/2024
↗️
0
Riemann-Lebesgue Forest for Regression
Tian Qin, Wei-Min Huang
We propose a novel ensemble method called Riemann-Lebesgue Forest (RLF) for regression. The core idea in RLF is to mimic the way how a measurable function can be approximated by partitioning its range into a few intervals. With this idea in mind, we develop a new tree learner named Riemann-Lebesgue Tree (RLT) which has a chance to perform Lebesgue type cutting,i.e splitting the node from response $Y$ at certain non-terminal nodes. We show that the optimal Lebesgue type cutting results in larger variance reduction in response $Y$ than ordinary CART cite{Breiman1984ClassificationAR} cutting (an analogue of Riemann partition). Such property is beneficial to the ensemble part of RLF. We also generalize the asymptotic normality of RLF under different parameter settings. Two one-dimensional examples are provided to illustrate the flexibility of RLF. The competitive performance of RLF against original random forest cite{Breiman2001RandomF} is demonstrated by experiments in simulation data and real world datasets.
Read more5/13/2024
👨🏫
0
Hyperbolic Random Forests
Lars Doorenbos, Pablo M'arquez-Neila, Raphael Sznitman, Pascal Mettes
Hyperbolic space is becoming a popular choice for representing data due to the hierarchical structure - whether implicit or explicit - of many real-world datasets. Along with it comes a need for algorithms capable of solving fundamental tasks, such as classification, in hyperbolic space. Recently, multiple papers have investigated hyperbolic alternatives to hyperplane-based classifiers, such as logistic regression and SVMs. While effective, these approaches struggle with more complex hierarchical data. We, therefore, propose to generalize the well-known random forests to hyperbolic space. We do this by redefining the notion of a split using horospheres. Since finding the globally optimal split is computationally intractable, we find candidate horospheres through a large-margin classifier. To make hyperbolic random forests work on multi-class data and imbalanced experiments, we furthermore outline a new method for combining classes based on their lowest common ancestor and a class-balanced version of the large-margin loss. Experiments on standard and new benchmarks show that our approach outperforms both conventional random forest algorithms and recent hyperbolic classifiers.
Read more6/26/2024