Fine-grained Hallucination Detection and Editing for Language Models

0

Sign in to get full access
Overview
- Explores methods for detecting and editing hallucinations in language models
- Proposes a fine-grained approach to identify and correct hallucinated content
- Demonstrates the effectiveness of the approach on multiple datasets and tasks
Plain English Explanation
Language models, which are AI systems trained on large amounts of text data, can sometimes generate false or nonsensical information called "hallucinations." Detecting and Mitigating Hallucinations in Large Vision-Language Models explores ways to identify and correct these hallucinations.
The researchers developed a fine-grained approach that can pinpoint exactly which parts of the model's output are hallucinated. This allows the model to be edited or "corrected" to remove the hallucinated content. The team tested their method on multiple datasets and tasks, showing that it can effectively detect and mitigate hallucinations in language models.
By being able to identify and fix hallucinations, this research could help make language models more reliable and trustworthy, especially in critical applications like medical diagnosis or financial advice.
Technical Explanation
The paper proposes a fine-grained approach to hallucination detection and editing. The key elements of their approach include:
- Hallucination Detection: The model is trained to classify each token in the output as either "hallucinated" or "non-hallucinated" using a sequence labeling setup.
- Hallucination Editing: Based on the hallucination detection, the model can then selectively edit or "correct" the hallucinated parts of the output.
- Multi-Task Training: The detection and editing models are trained jointly in a multi-task setup, allowing them to learn complementary skills.
The researchers evaluate their approach on multiple datasets and tasks, including news headline generation and long-form text generation. They demonstrate that their fine-grained method outperforms previous approaches in accurately identifying and mitigating hallucinations.
Critical Analysis
The paper provides a thorough and technical exploration of the hallucination detection and editing problem. However, a few potential limitations or areas for further research are worth noting:
- Dataset Bias: The performance of the models may be influenced by the specific characteristics of the datasets used for evaluation. Assessing the approach on a broader range of datasets could provide a more comprehensive understanding of its capabilities.
- Real-World Deployment: While the results are promising, the researchers do not address the practical challenges of deploying such a system in real-world applications, such as computational efficiency, integration with existing language models, and user experience considerations.
- Human Evaluation: The paper primarily relies on automated metrics to assess the quality of the edited outputs. Incorporating human evaluation could provide additional insights into the perceived coherence and faithfulness of the corrected text.
Overall, the paper presents a innovative approach to a critical problem in language modeling, but further research and practical considerations may be needed to fully realize the potential of fine-grained hallucination detection and editing.
Conclusion
This research addresses the important challenge of hallucinations in language models, proposing a fine-grained approach to identify and correct these issues. By being able to precisely pinpoint and edit hallucinated content, the technique could help improve the reliability and trustworthiness of language models, with potential applications in fields like healthcare, finance, and education. While the paper provides a strong technical foundation, additional work may be needed to fully understand the real-world implications and deployment considerations of this approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fine-grained Hallucination Detection and Editing for Language Models
Abhika Mishra, Akari Asai, Vidhisha Balachandran, Yizhong Wang, Graham Neubig, Yulia Tsvetkov, Hannaneh Hajishirzi
Large language models (LMs) are prone to generate factual errors, which are often called hallucinations. In this paper, we introduce a comprehensive taxonomy of hallucinations and argue that hallucinations manifest in diverse forms, each requiring varying degrees of careful assessments to verify factuality. We propose a novel task of automatic fine-grained hallucination detection and construct a new evaluation benchmark, FavaBench, that includes about one thousand fine-grained human judgments on three LM outputs across various domains. Our analysis reveals that ChatGPT and Llama2-Chat (70B, 7B) exhibit diverse types of hallucinations in the majority of their outputs in information-seeking scenarios. We train FAVA, a retrieval-augmented LM by carefully creating synthetic data to detect and correct fine-grained hallucinations. On our benchmark, our automatic and human evaluations show that FAVA significantly outperforms ChatGPT and GPT-4 on fine-grained hallucination detection, and edits suggested by FAVA improve the factuality of LM-generated text.
Read more8/14/2024
0
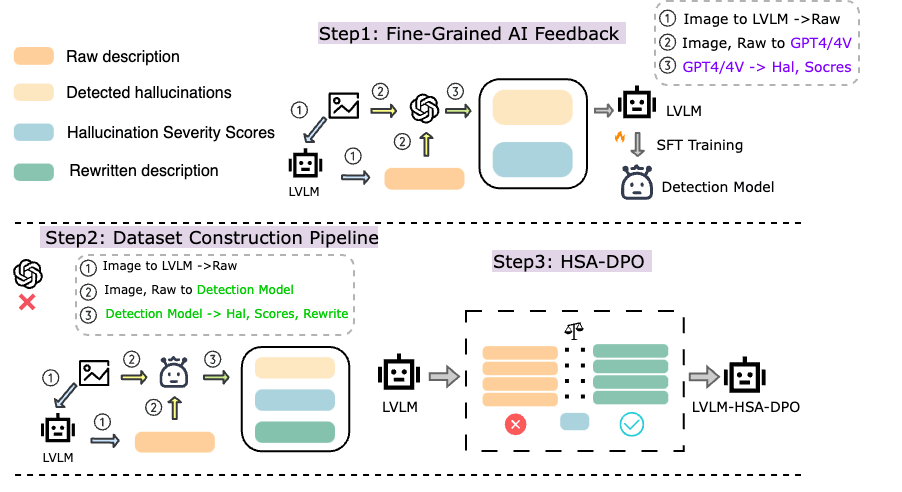
Detecting and Mitigating Hallucination in Large Vision Language Models via Fine-Grained AI Feedback
Wenyi Xiao, Ziwei Huang, Leilei Gan, Wanggui He, Haoyuan Li, Zhelun Yu, Hao Jiang, Fei Wu, Linchao Zhu
The rapidly developing Large Vision Language Models (LVLMs) have shown notable capabilities on a range of multi-modal tasks, but still face the hallucination phenomena where the generated texts do not align with the given contexts, significantly restricting the usages of LVLMs. Most previous work detects and mitigates hallucination at the coarse-grained level or requires expensive annotation (e.g., labeling by proprietary models or human experts). To address these issues, we propose detecting and mitigating hallucinations in LVLMs via fine-grained AI feedback. The basic idea is that we generate a small-size sentence-level hallucination annotation dataset by proprietary models, whereby we train a hallucination detection model which can perform sentence-level hallucination detection, covering primary hallucination types (i.e., object, attribute, and relationship). Then, we propose a detect-then-rewrite pipeline to automatically construct preference dataset for training hallucination mitigating model. Furthermore, we propose differentiating the severity of hallucinations, and introducing a Hallucination Severity-Aware Direct Preference Optimization (HSA-DPO) for mitigating hallucination in LVLMs by incorporating the severity of hallucinations into preference learning. Extensive experiments demonstrate the effectiveness of our method.
Read more4/23/2024

0
Multilingual Fine-Grained News Headline Hallucination Detection
Jiaming Shen, Tianqi Liu, Jialu Liu, Zhen Qin, Jay Pavagadhi, Simon Baumgartner, Michael Bendersky
The popularity of automated news headline generation has surged with advancements in pre-trained language models. However, these models often suffer from the ``hallucination'' problem, where the generated headline is not fully supported by its source article. Efforts to address this issue have predominantly focused on English, using over-simplistic classification schemes that overlook nuanced hallucination types. In this study, we introduce the first multilingual, fine-grained news headline hallucination detection dataset that contains over 11 thousand pairs in 5 languages, each annotated with detailed hallucination types by experts. We conduct extensive experiments on this dataset under two settings. First, we implement several supervised fine-tuning approaches as preparatory solutions and demonstrate this dataset's challenges and utilities. Second, we test various large language models' in-context learning abilities and propose two novel techniques, language-dependent demonstration selection and coarse-to-fine prompting, to boost the few-shot hallucination detection performance in terms of the example-F1 metric. We release this dataset to foster further research in multilingual, fine-grained headline hallucination detection.
Read more7/24/2024

0
Mitigating Large Language Model Hallucination with Faithful Finetuning
Minda Hu, Bowei He, Yufei Wang, Liangyou Li, Chen Ma, Irwin King
Large language models (LLMs) have demonstrated remarkable performance on various natural language processing tasks. However, they are prone to generating fluent yet untruthful responses, known as hallucinations. Hallucinations can lead to the spread of misinformation and cause harm in critical applications. Mitigating hallucinations is challenging as they arise from factors such as noisy data, model overconfidence, lack of knowledge, and the generation process itself. Recent efforts have attempted to address this issue through representation editing and decoding algorithms, reducing hallucinations without major structural changes or retraining. However, these approaches either implicitly edit LLMs' behavior in latent space or suppress the tendency to output unfaithful results during decoding instead of explicitly modeling on hallucination. In this work, we introduce Faithful Finetuning (F2), a novel method that explicitly models the process of faithful question answering through carefully designed loss functions during fine-tuning. We conduct extensive experiments on popular datasets and demonstrate that F2 achieves significant improvements over vanilla models and baselines.
Read more6/18/2024