Addressing Topic Leakage in Cross-Topic Evaluation for Authorship Verification

0

Sign in to get full access
Overview
- This paper addresses the issue of topic leakage in cross-topic authorship verification, where the model learns to identify the author based on topic-specific cues rather than true stylistic differences.
- The authors propose a novel approach called TAPS (Topic-Aware Prompts and Sampling) to mitigate this problem by introducing topic-aware prompts and topic-stratified sampling during training and evaluation.
- The paper presents experiments on two datasets, demonstrating that TAPS can significantly improve the robustness and generalization of authorship verification models compared to existing methods.
Plain English Explanation
Authorship verification is the task of determining whether a given text was written by a specific author. One challenge in this field is topic leakage, where the model learns to identify the author based on the topic of the text rather than the author's unique writing style.
For example, if the model is trained on texts about technology, it may learn to associate certain words or phrases with a particular author, but this association may not hold true for texts on a different topic, such as politics. This can lead to poor performance when the model is evaluated on texts from a different topic.
To address this issue, the researchers propose a method called TAPS (Topic-Aware Prompts and Sampling). The key ideas are:
-
Topic-Aware Prompts: Instead of using generic prompts during training, the model is trained with prompts that are tailored to specific topics. This helps the model learn to focus on stylistic differences rather than topic-specific cues.
-
Topic-Stratified Sampling: The training and evaluation data are divided into different topic categories, and the model is trained and evaluated on a balanced mix of topics. This ensures that the model learns to generalize across topics, rather than relying on topic-specific patterns.
By incorporating these techniques, the authors show that their TAPS approach can significantly improve the robustness and generalization of authorship verification models, outperforming existing methods on two different datasets.
Technical Explanation
The paper proposes a novel approach called TAPS (Topic-Aware Prompts and Sampling) to address the issue of topic leakage in cross-topic authorship verification. The key components of TAPS are:
-
Topic-Aware Prompts: Instead of using generic prompts during training, the model is trained with prompts that are tailored to specific topics. This helps the model learn to focus on stylistic differences rather than topic-specific cues.
-
Topic-Stratified Sampling: The training and evaluation data are divided into different topic categories, and the model is trained and evaluated on a balanced mix of topics. This ensures that the model learns to generalize across topics, rather than relying on topic-specific patterns.
The authors evaluate their approach on two datasets: InstructAV and Can Authorship Attribution Models Distinguish Speakers in Speech?. The results show that TAPS can significantly improve the robustness and generalization of authorship verification models, outperforming existing methods.
Critical Analysis
The paper addresses an important challenge in authorship verification, namely the issue of topic leakage, where models can learn to identify authors based on topic-specific cues rather than true stylistic differences. The proposed TAPS approach seems promising in addressing this problem, as demonstrated by the experiments on the two datasets.
However, the paper could benefit from a more thorough discussion of the limitations and potential drawbacks of the TAPS approach. For example, it would be interesting to see how the method performs on a more diverse set of datasets or genres, as the current evaluation is limited to two specific datasets.
Additionally, the paper does not provide much insight into the potential trade-offs or computational costs associated with the TAPS approach, such as the impact of the topic-aware prompts and topic-stratified sampling on training time or model complexity. Exploring these aspects could help researchers and practitioners better understand the practical implications of adopting the TAPS method.
Overall, the paper presents a valuable contribution to the field of authorship verification, and the TAPS approach appears to be a promising direction for further research and development in this area.
Conclusion
This paper addresses the critical issue of topic leakage in cross-topic authorship verification, where models can learn to identify authors based on topic-specific cues rather than true stylistic differences. The authors propose a novel approach called TAPS (Topic-Aware Prompts and Sampling) to mitigate this problem, which involves the use of topic-aware prompts and topic-stratified sampling during training and evaluation.
The experimental results demonstrate that the TAPS approach can significantly improve the robustness and generalization of authorship verification models, outperforming existing methods on two different datasets. This work represents an important step forward in developing more reliable and accurate authorship verification systems, which have applications in fields such as forensics, plagiarism detection, and literary analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Addressing Topic Leakage in Cross-Topic Evaluation for Authorship Verification
Jitkapat Sawatphol, Can Udomcharoenchaikit, Sarana Nutanong
Authorship verification (AV) aims to identify whether a pair of texts has the same author. We address the challenge of evaluating AV models' robustness against topic shifts. The conventional evaluation assumes minimal topic overlap between training and test data. However, we argue that there can still be topic leakage in test data, causing misleading model performance and unstable rankings. To address this, we propose an evaluation method called Heterogeneity-Informed Topic Sampling (HITS), which creates a smaller dataset with a heterogeneously distributed topic set. Our experimental results demonstrate that HITS-sampled datasets yield a more stable ranking of models across random seeds and evaluation splits. Our contributions include: 1. An analysis of causes and effects of topic leakage. 2. A demonstration of the HITS in reducing the effects of topic leakage, and 3. The Robust Authorship Verification bENchmark (RAVEN) that allows topic shortcut test to uncover AV models' reliance on topic-specific features.
Read more7/30/2024

0
InstructAV: Instruction Fine-tuning Large Language Models for Authorship Verification
Yujia Hu, Zhiqiang Hu, Chun-Wei Seah, Roy Ka-Wei Lee
Large Language Models (LLMs) have demonstrated remarkable proficiency in a wide range of NLP tasks. However, when it comes to authorship verification (AV) tasks, which involve determining whether two given texts share the same authorship, even advanced models like ChatGPT exhibit notable limitations. This paper introduces a novel approach, termed InstructAV, for authorship verification. This approach utilizes LLMs in conjunction with a parameter-efficient fine-tuning (PEFT) method to simultaneously improve accuracy and explainability. The distinctiveness of InstructAV lies in its ability to align classification decisions with transparent and understandable explanations, representing a significant progression in the field of authorship verification. Through comprehensive experiments conducted across various datasets, InstructAV demonstrates its state-of-the-art performance on the AV task, offering high classification accuracy coupled with enhanced explanation reliability.
Read more7/19/2024
🗣️
0
Can Authorship Attribution Models Distinguish Speakers in Speech Transcripts?
Cristina Aggazzotti, Nicholas Andrews, Elizabeth Allyn Smith
Authorship verification is the task of determining if two distinct writing samples share the same author and is typically concerned with the attribution of written text. In this paper, we explore the attribution of transcribed speech, which poses novel challenges. The main challenge is that many stylistic features, such as punctuation and capitalization, are not informative in this setting. On the other hand, transcribed speech exhibits other patterns, such as filler words and backchannels (e.g., 'um', 'uh-huh'), which may be characteristic of different speakers. We propose a new benchmark for speaker attribution focused on human-transcribed conversational speech transcripts. To limit spurious associations of speakers with topic, we employ both conversation prompts and speakers participating in the same conversation to construct verification trials of varying difficulties. We establish the state of the art on this new benchmark by comparing a suite of neural and non-neural baselines, finding that although written text attribution models achieve surprisingly good performance in certain settings, they perform markedly worse as conversational topic is increasingly controlled. We present analyses of the impact of transcription style on performance as well as the ability of fine-tuning on speech transcripts to improve performance.
Read more6/17/2024
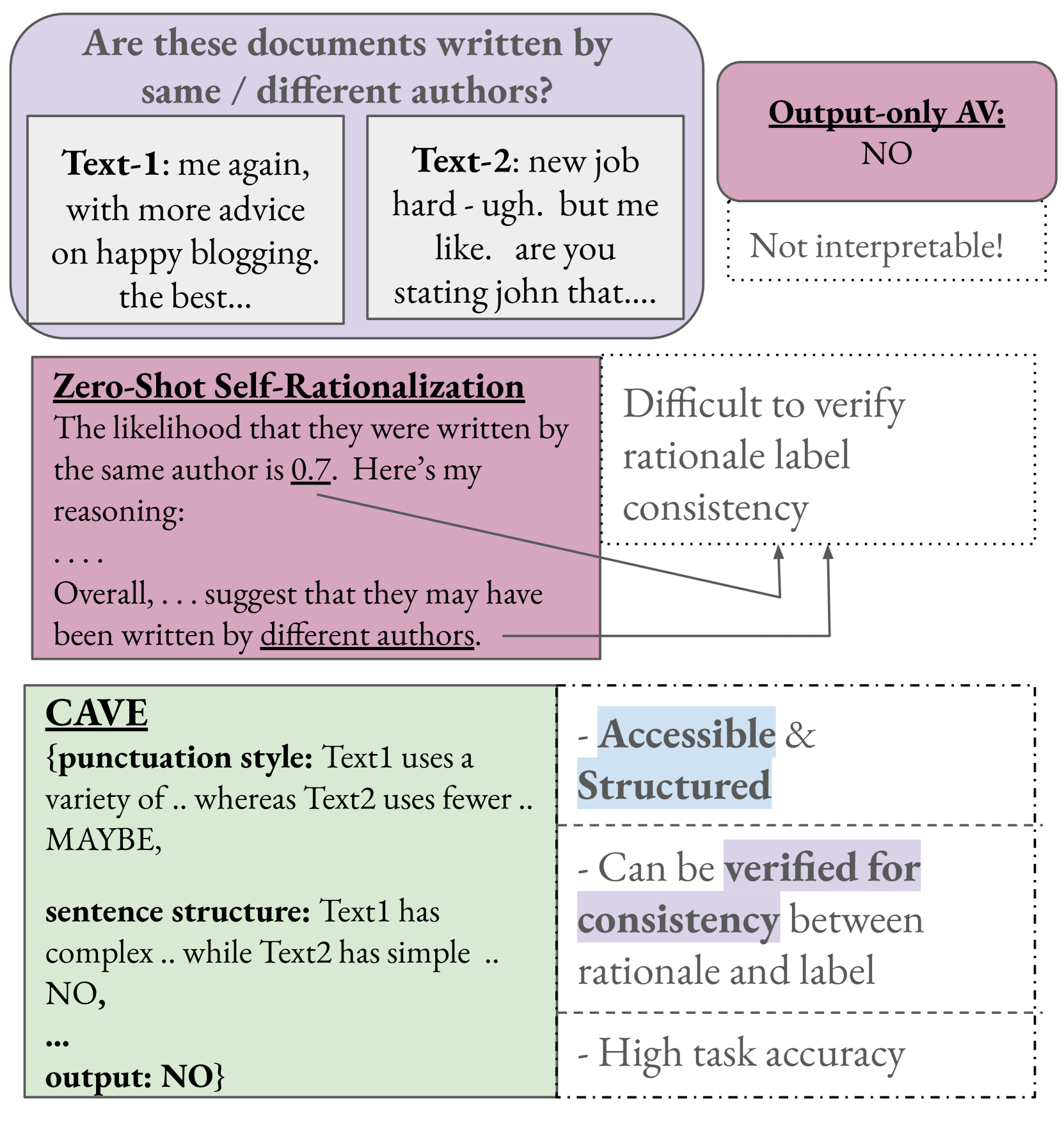
0
CAVE: Controllable Authorship Verification Explanations
Sahana Ramnath, Kartik Pandey, Elizabeth Boschee, Xiang Ren
Authorship Verification (AV) (do two documents have the same author?) is essential in many sensitive real-life applications. AV is often used in proprietary domains that require a private, offline model, making SOTA online models like ChatGPT undesirable. Current offline models however have lower downstream utility due to low accuracy/scalability (eg: traditional stylometry AV systems) and lack of accessible post-hoc explanations. In this work, we take the first step to address the above challenges with our trained, offline Llama-3-8B model CAVE (Controllable Authorship Verification Explanations): CAVE generates free-text AV explanations that are controlled to be (1) structured (can be decomposed into sub-explanations in terms of relevant linguistic features), and (2) easily verified for explanation-label consistency (via intermediate labels in sub-explanations). We first engineer a prompt that can generate silver training data from a SOTA teacher model in the desired CAVE output format. We then filter and distill this data into a pretrained Llama-3-8B, our carefully selected student model. Results on three difficult AV datasets IMDb62, Blog-Auth, and Fanfiction show that CAVE generates high quality explanations (as measured by automatic and human evaluation) as well as competitive task accuracies.
Read more9/6/2024