InstructAV: Instruction Fine-tuning Large Language Models for Authorship Verification

0

Sign in to get full access
Overview
- This paper presents "InstructAV", a method for fine-tuning large language models to perform authorship verification tasks.
- Authorship verification is the task of determining whether a given text was written by a particular author.
- The authors demonstrate that fine-tuning language models with instructional prompts can significantly improve their performance on authorship verification benchmarks.
Plain English Explanation
The researchers developed a new technique called "InstructAV" to improve the ability of large language models to determine whether a piece of writing was created by a specific author. Authorship verification is the process of analyzing a text and deciding if it was written by a particular person.
The key idea behind InstructAV is to fine-tune the language model using instructional prompts, which provide the model with clear guidelines on how to approach the authorship verification task. This training process helps the model learn the relevant skills and knowledge needed to make accurate authorship judgments.
The researchers show that language models trained with InstructAV significantly outperform standard language models on authorship verification benchmarks. This suggests that the instructional fine-tuning approach is an effective way to tailor large language models for this specific task.
The advantages of InstructAV include link to "Directed Domain Fine-tuning: Tailoring Separate Modalities" the ability to leverage the powerful capabilities of large language models while also customizing them for targeted applications, as well as the potential to link to "Towards Robust Instruction Tuning for Multimodal Large Language Models" make language models more robust and reliable for real-world use cases.
Technical Explanation
The authors of this paper propose a technique called "InstructAV" for fine-tuning large language models to perform authorship verification tasks. Authorship verification is the problem of determining whether a given text was written by a particular author.
The key innovation of InstructAV is the use of instructional prompts during the fine-tuning process. These prompts provide the language model with clear guidelines on how to approach the authorship verification task, such as what information to focus on and how to make authorship judgments. This instructional fine-tuning helps the model learn the relevant skills and knowledge needed for accurate authorship verification.
The authors evaluate InstructAV on several authorship verification benchmarks and show that it significantly outperforms standard fine-tuning approaches. They also demonstrate that InstructAV is effective at transferring knowledge to new domains, as evidenced by its strong performance on cross-domain authorship verification tasks.
The success of InstructAV suggests that instructional fine-tuning is a promising technique for link to "CAVE: Controllable Authorship Verification Explanations" tailoring large language models to specific applications, such as link to "InstructTA: Instruction-Tuned Targeted Attack on Large Vision Models" authorship verification. This approach could lead to more robust and reliable language models that can be effectively deployed in real-world scenarios.
Critical Analysis
The authors of this paper present a compelling approach for fine-tuning large language models for authorship verification tasks. The key strength of InstructAV is its use of instructional prompts, which helps the model learn the relevant skills and knowledge needed for accurate authorship judgments.
One potential limitation of the study is the reliance on a relatively small number of authorship verification datasets. While the authors demonstrate the effectiveness of InstructAV on these benchmarks, it would be valuable to see how the approach performs on a wider range of datasets, including those with more diverse writing styles and genres.
Additionally, the paper does not provide much insight into the specific mechanisms by which the instructional fine-tuning process improves the model's authorship verification capabilities. Further research exploring the internal workings of InstructAV could lead to a better understanding of how instructional prompts influence the model's decision-making and reasoning processes.
Overall, the InstructAV approach represents an important step towards link to "Contrastive Instruction Tuning" developing more capable and versatile language models for real-world applications. The authors' findings suggest that instructional fine-tuning is a promising direction for future research in this area.
Conclusion
This paper presents InstructAV, a novel technique for fine-tuning large language models to perform authorship verification tasks. The key innovation of InstructAV is the use of instructional prompts during the fine-tuning process, which helps the model learn the relevant skills and knowledge needed for accurate authorship judgments.
The authors demonstrate that language models trained with InstructAV significantly outperform standard fine-tuning approaches on a range of authorship verification benchmarks. This suggests that instructional fine-tuning is an effective way to tailor large language models for specific applications, potentially leading to more robust and reliable models that can be deployed in real-world scenarios.
While the study has some limitations, the success of InstructAV represents an important step forward in the field of link to "Towards Robust Instruction Tuning for Multimodal Large Language Models" language model personalization and customization. The findings of this paper could inspire further research into instructional fine-tuning techniques and their application to a wider range of tasks and domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
InstructAV: Instruction Fine-tuning Large Language Models for Authorship Verification
Yujia Hu, Zhiqiang Hu, Chun-Wei Seah, Roy Ka-Wei Lee
Large Language Models (LLMs) have demonstrated remarkable proficiency in a wide range of NLP tasks. However, when it comes to authorship verification (AV) tasks, which involve determining whether two given texts share the same authorship, even advanced models like ChatGPT exhibit notable limitations. This paper introduces a novel approach, termed InstructAV, for authorship verification. This approach utilizes LLMs in conjunction with a parameter-efficient fine-tuning (PEFT) method to simultaneously improve accuracy and explainability. The distinctiveness of InstructAV lies in its ability to align classification decisions with transparent and understandable explanations, representing a significant progression in the field of authorship verification. Through comprehensive experiments conducted across various datasets, InstructAV demonstrates its state-of-the-art performance on the AV task, offering high classification accuracy coupled with enhanced explanation reliability.
Read more7/19/2024
0
CAVE: Controllable Authorship Verification Explanations
Sahana Ramnath, Kartik Pandey, Elizabeth Boschee, Xiang Ren
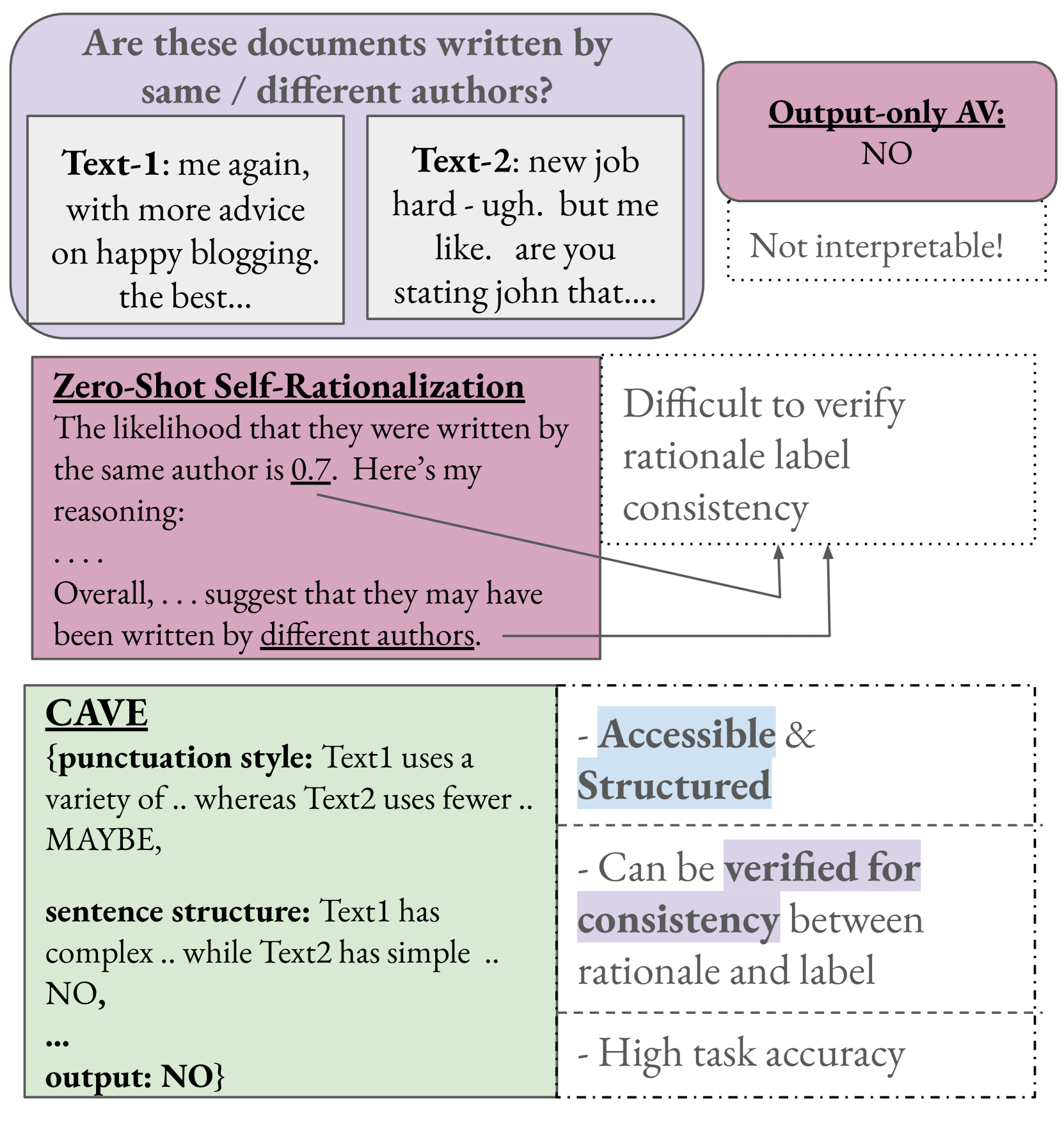
Authorship Verification (AV) (do two documents have the same author?) is essential in many sensitive real-life applications. AV is often used in proprietary domains that require a private, offline model, making SOTA online models like ChatGPT undesirable. Current offline models however have lower downstream utility due to low accuracy/scalability (eg: traditional stylometry AV systems) and lack of accessible post-hoc explanations. In this work, we take the first step to address the above challenges with our trained, offline Llama-3-8B model CAVE (Controllable Authorship Verification Explanations): CAVE generates free-text AV explanations that are controlled to be (1) structured (can be decomposed into sub-explanations in terms of relevant linguistic features), and (2) easily verified for explanation-label consistency (via intermediate labels in sub-explanations). We first engineer a prompt that can generate silver training data from a SOTA teacher model in the desired CAVE output format. We then filter and distill this data into a pretrained Llama-3-8B, our carefully selected student model. Results on three difficult AV datasets IMDb62, Blog-Auth, and Fanfiction show that CAVE generates high quality explanations (as measured by automatic and human evaluation) as well as competitive task accuracies.
Read more9/6/2024
🏅
0
InstructTA: Instruction-Tuned Targeted Attack for Large Vision-Language Models
Xunguang Wang, Zhenlan Ji, Pingchuan Ma, Zongjie Li, Shuai Wang
Large vision-language models (LVLMs) have demonstrated their incredible capability in image understanding and response generation. However, this rich visual interaction also makes LVLMs vulnerable to adversarial examples. In this paper, we formulate a novel and practical targeted attack scenario that the adversary can only know the vision encoder of the victim LVLM, without the knowledge of its prompts (which are often proprietary for service providers and not publicly available) and its underlying large language model (LLM). This practical setting poses challenges to the cross-prompt and cross-model transferability of targeted adversarial attack, which aims to confuse the LVLM to output a response that is semantically similar to the attacker's chosen target text. To this end, we propose an instruction-tuned targeted attack (dubbed textsc{InstructTA}) to deliver the targeted adversarial attack on LVLMs with high transferability. Initially, we utilize a public text-to-image generative model to reverse the target response into a target image, and employ GPT-4 to infer a reasonable instruction $boldsymbol{p}^prime$ from the target response. We then form a local surrogate model (sharing the same vision encoder with the victim LVLM) to extract instruction-aware features of an adversarial image example and the target image, and minimize the distance between these two features to optimize the adversarial example. To further improve the transferability with instruction tuning, we augment the instruction $boldsymbol{p}^prime$ with instructions paraphrased from GPT-4. Extensive experiments demonstrate the superiority of our proposed method in targeted attack performance and transferability. The code is available at https://github.com/xunguangwang/InstructTA.
Read more6/27/2024

0
Addressing Topic Leakage in Cross-Topic Evaluation for Authorship Verification
Jitkapat Sawatphol, Can Udomcharoenchaikit, Sarana Nutanong
Authorship verification (AV) aims to identify whether a pair of texts has the same author. We address the challenge of evaluating AV models' robustness against topic shifts. The conventional evaluation assumes minimal topic overlap between training and test data. However, we argue that there can still be topic leakage in test data, causing misleading model performance and unstable rankings. To address this, we propose an evaluation method called Heterogeneity-Informed Topic Sampling (HITS), which creates a smaller dataset with a heterogeneously distributed topic set. Our experimental results demonstrate that HITS-sampled datasets yield a more stable ranking of models across random seeds and evaluation splits. Our contributions include: 1. An analysis of causes and effects of topic leakage. 2. A demonstration of the HITS in reducing the effects of topic leakage, and 3. The Robust Authorship Verification bENchmark (RAVEN) that allows topic shortcut test to uncover AV models' reliance on topic-specific features.
Read more7/30/2024