CAVE: Controllable Authorship Verification Explanations

0
Sign in to get full access
Overview
- This paper introduces CAVE, a framework for generating controllable and explainable authorship verification explanations.
- CAVE uses a language model to generate textual explanations that justify the model's decision about whether a given text was written by a particular author.
- The authors demonstrate that CAVE can produce high-quality, controllable, and interpretable explanations that outperform existing approaches.
Plain English Explanation
The paper presents a new system called CAVE (Controllable Authorship Verification Explanations) that can determine whether a piece of writing was created by a specific person. CAVE uses a powerful language model to analyze the text and then generate an explanation in plain language to justify its decision.
The key innovation of CAVE is that it allows users to control the style and content of the explanations. For example, users can request an explanation that focuses on particular writing features, or one that is more concise or detailed. This gives users more insight into how the system is making its decisions, which is important for building trust and understanding.
The researchers show that CAVE's explanations are of high quality and outperform previous approaches. This is significant because being able to understand and trust AI systems that make important decisions about authorship is crucial in areas like law, journalism, and academia.
Overall, CAVE represents an important step forward in making AI systems that can analyze text more transparent and controllable. By providing clear and customizable explanations, CAVE helps bridge the gap between the inner workings of the system and the needs of human users.
Technical Explanation
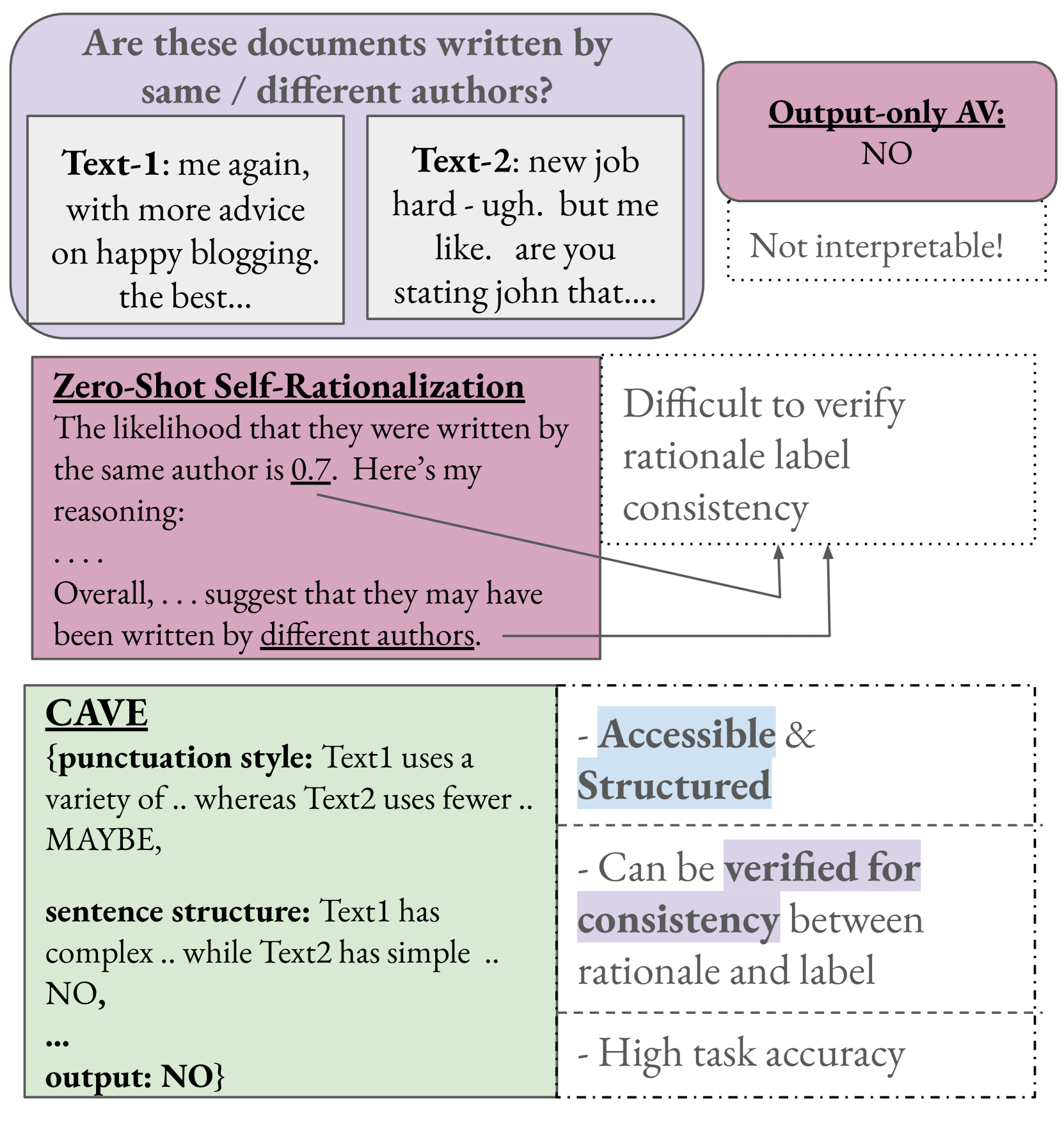
The authors propose CAVE, a framework for generating controllable and explainable authorship verification explanations. CAVE uses a pre-trained language model that is fine-tuned on a dataset of author-labeled texts. Given a new text, CAVE generates an explanation that justifies whether the text was written by a particular author.
A key aspect of CAVE is its controllability. Users can specify the desired properties of the explanation, such as its length, focus on particular writing features, or level of detail. CAVE achieves this by incorporating user-specified control codes into the language model's input, which guide the generation process.
The authors evaluate CAVE on several authorship verification datasets and compare it to existing baselines. They find that CAVE generates high-quality, interpretable explanations that outperform previous methods in terms of faithfulness to the model's decisions and overall explanation quality.
Additionally, the authors conduct human evaluations to assess the usefulness and understandability of CAVE's explanations. The results show that users find the explanations to be informative and that the controllability feature is valuable for tailoring the explanations to their needs.
Critical Analysis
The CAVE framework represents an important advancement in making authorship verification systems more transparent and accessible to users. By generating explanations that justify the model's decisions, CAVE helps bridge the gap between the system's internal workings and the needs of human users.
One potential limitation of the approach is that it relies on a pre-trained language model, which may encode biases or limitations. The authors acknowledge this and suggest further research on model fine-tuning and debiasing techniques to address this issue.
Additionally, while the authors demonstrate the effectiveness of CAVE on several datasets, it would be valuable to explore its performance on a wider range of text types and authorship verification scenarios. This could help validate the generalizability of the approach and identify any potential limitations.
Finally, the authors do not delve deeply into the potential ethical implications of authorship verification systems. As these technologies become more widespread, it will be crucial to consider their societal impact, particularly in sensitive domains like law and journalism. Further research on the responsible development and deployment of such systems is warranted.
Overall, the CAVE framework represents a significant advancement in the field of explainable AI for authorship verification. By providing controllable and interpretable explanations, the system has the potential to enhance trust, transparency, and understanding between AI systems and human users.
Conclusion
The CAVE framework introduced in this paper represents an important step forward in making authorship verification systems more transparent and accessible to users. By generating high-quality, controllable explanations that justify the model's decisions, CAVE helps bridge the gap between the inner workings of the system and the needs of human users.
The researchers demonstrate the effectiveness of CAVE on several authorship verification datasets and show that it outperforms existing approaches. The ability to customize the explanations to user preferences is a particularly valuable feature, as it allows users to tailor the system's output to their specific needs and understanding.
While the paper highlights the strengths of the CAVE framework, it also acknowledges potential limitations, such as the reliance on a pre-trained language model and the need to consider the ethical implications of authorship verification systems. Addressing these challenges through further research and development will be crucial for the widespread adoption and responsible use of these technologies.
Overall, the CAVE framework represents a significant advancement in the field of explainable AI for text analysis. By providing users with clear and customizable explanations, CAVE has the potential to enhance trust, transparency, and understanding between AI systems and the humans who rely on them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CAVE: Controllable Authorship Verification Explanations
Sahana Ramnath, Kartik Pandey, Elizabeth Boschee, Xiang Ren
Authorship Verification (AV) (do two documents have the same author?) is essential in many sensitive real-life applications. AV is often used in proprietary domains that require a private, offline model, making SOTA online models like ChatGPT undesirable. Current offline models however have lower downstream utility due to low accuracy/scalability (eg: traditional stylometry AV systems) and lack of accessible post-hoc explanations. In this work, we take the first step to address the above challenges with our trained, offline Llama-3-8B model CAVE (Controllable Authorship Verification Explanations): CAVE generates free-text AV explanations that are controlled to be (1) structured (can be decomposed into sub-explanations in terms of relevant linguistic features), and (2) easily verified for explanation-label consistency (via intermediate labels in sub-explanations). We first engineer a prompt that can generate silver training data from a SOTA teacher model in the desired CAVE output format. We then filter and distill this data into a pretrained Llama-3-8B, our carefully selected student model. Results on three difficult AV datasets IMDb62, Blog-Auth, and Fanfiction show that CAVE generates high quality explanations (as measured by automatic and human evaluation) as well as competitive task accuracies.
Read more9/6/2024

0
InstructAV: Instruction Fine-tuning Large Language Models for Authorship Verification
Yujia Hu, Zhiqiang Hu, Chun-Wei Seah, Roy Ka-Wei Lee
Large Language Models (LLMs) have demonstrated remarkable proficiency in a wide range of NLP tasks. However, when it comes to authorship verification (AV) tasks, which involve determining whether two given texts share the same authorship, even advanced models like ChatGPT exhibit notable limitations. This paper introduces a novel approach, termed InstructAV, for authorship verification. This approach utilizes LLMs in conjunction with a parameter-efficient fine-tuning (PEFT) method to simultaneously improve accuracy and explainability. The distinctiveness of InstructAV lies in its ability to align classification decisions with transparent and understandable explanations, representing a significant progression in the field of authorship verification. Through comprehensive experiments conducted across various datasets, InstructAV demonstrates its state-of-the-art performance on the AV task, offering high classification accuracy coupled with enhanced explanation reliability.
Read more7/19/2024

0
TextCAVs: Debugging vision models using text
Angus Nicolson, Yarin Gal, J. Alison Noble
Concept-based interpretability methods are a popular form of explanation for deep learning models which provide explanations in the form of high-level human interpretable concepts. These methods typically find concept activation vectors (CAVs) using a probe dataset of concept examples. This requires labelled data for these concepts -- an expensive task in the medical domain. We introduce TextCAVs: a novel method which creates CAVs using vision-language models such as CLIP, allowing for explanations to be created solely using text descriptions of the concept, as opposed to image exemplars. This reduced cost in testing concepts allows for many concepts to be tested and for users to interact with the model, testing new ideas as they are thought of, rather than a delay caused by image collection and annotation. In early experimental results, we demonstrate that TextCAVs produces reasonable explanations for a chest x-ray dataset (MIMIC-CXR) and natural images (ImageNet), and that these explanations can be used to debug deep learning-based models.
Read more8/19/2024

0
ClaimVer: Explainable Claim-Level Verification and Evidence Attribution of Text Through Knowledge Graphs
Preetam Prabhu Srikar Dammu, Himanshu Naidu, Mouly Dewan, YoungMin Kim, Tanya Roosta, Aman Chadha, Chirag Shah
In the midst of widespread misinformation and disinformation through social media and the proliferation of AI-generated texts, it has become increasingly difficult for people to validate and trust information they encounter. Many fact-checking approaches and tools have been developed, but they often lack appropriate explainability or granularity to be useful in various contexts. A text validation method that is easy to use, accessible, and can perform fine-grained evidence attribution has become crucial. More importantly, building user trust in such a method requires presenting the rationale behind each prediction, as research shows this significantly influences people's belief in automated systems. Localizing and bringing users' attention to the specific problematic content is also paramount, instead of providing simple blanket labels. In this paper, we present ClaimVer, a human-centric framework tailored to meet users' informational and verification needs by generating rich annotations and thereby reducing cognitive load. Designed to deliver comprehensive evaluations of texts, it highlights each claim, verifies it against a trusted knowledge graph (KG), presents the evidence, and provides succinct, clear explanations for each claim prediction. Finally, our framework introduces an attribution score, enhancing applicability across a wide range of downstream tasks.
Read more9/24/2024