Advancing Large Language Models to Capture Varied Speaking Styles and Respond Properly in Spoken Conversations
2402.12786
0
0
Abstract
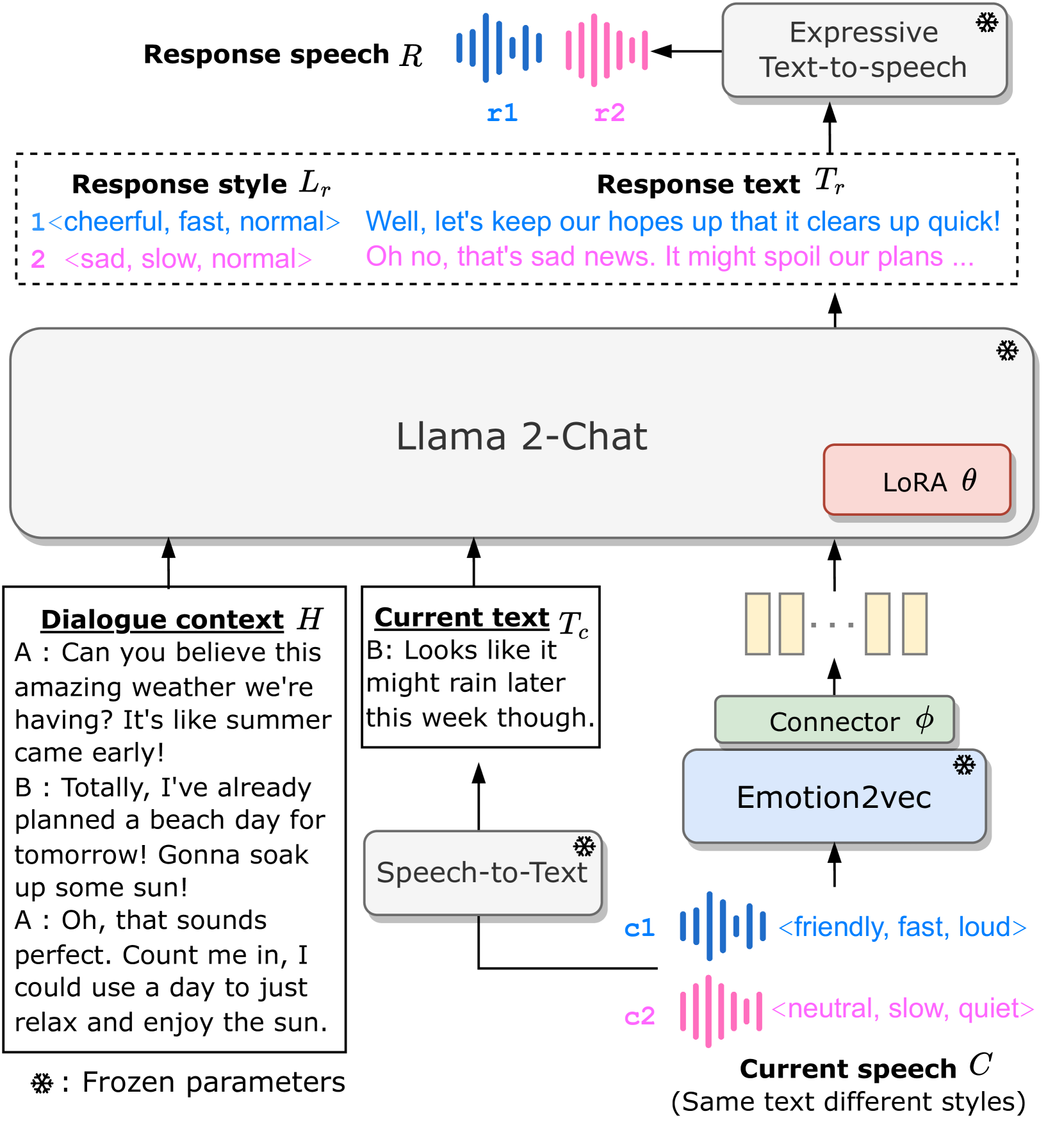
In spoken dialogue, even if two current turns are the same sentence, their responses might still differ when they are spoken in different styles. The spoken styles, containing paralinguistic and prosodic information, mark the most significant difference between text and speech modality. When using text-only LLMs to model spoken dialogue, text-only LLMs cannot give different responses based on the speaking style of the current turn. In this paper, we focus on enabling LLMs to listen to the speaking styles and respond properly. Our goal is to teach the LLM that even if the sentences are identical if they are spoken in different styles, their corresponding responses might be different. Since there is no suitable dataset for achieving this goal, we collect a speech-to-speech dataset, StyleTalk, with the following desired characteristics: when two current speeches have the same content but are spoken in different styles, their responses will be different. To teach LLMs to understand and respond properly to the speaking styles, we propose the Spoken-LLM framework that can model the linguistic content and the speaking styles. We train Spoken-LLM using the StyleTalk dataset and devise a two-stage training pipeline to help the Spoken-LLM better learn the speaking styles. Based on extensive experiments, we show that Spoken-LLM outperforms text-only baselines and prior speech LLMs methods.
Create account to get full access
Overview
- The paper explores techniques to advance large language models (LLMs) so they can better capture varied speaking styles and respond appropriately in spoken conversations.
- It introduces a new dataset called StyleTalk, which contains spoken conversations with diverse speaker styles and personalities.
- The researchers use this dataset to train LLMs to engage in more natural and contextually-appropriate dialogue, going beyond just generating grammatically correct responses.
Plain English Explanation
The paper focuses on improving large language models (LLMs) - powerful AI systems that can generate human-like text. The researchers want these models to be better at understanding and responding to different speaking styles and conversational contexts.
Typically, LLMs are trained on written text, which can make them sound a bit stiff or formal when used in spoken dialogue. The researchers created a new dataset called StyleTalk, which contains recordings of natural conversations with people of varying personalities and communication styles.
By training LLMs on this diverse data, the researchers hope to create models that can engage in more natural, contextually-appropriate conversation. Instead of just generating grammatically correct responses, the models will learn to adapt their language and tone to the specific speaker and situation.
This could lead to significant improvements in conversational AI assistants, allowing them to communicate in a more natural, human-like way. It could also benefit applications like voice interfaces, customer service chatbots, and virtual tutors.
Technical Explanation
The paper introduces a novel dataset called StyleTalk, which contains over 5,000 spoken conversations with diverse speaker styles and personalities. This is used to train large language models (LLMs) to better capture the nuances of spoken dialogue, beyond just generating grammatically correct responses.
The researchers experiment with different model architectures and training approaches to incorporate the rich contextual information present in the StyleTalk dataset. This includes techniques like link to "Large Language Model-based Situational Dialogues" and link to "Full-Duplex Speech Dialogue Scheme Based on Large Language Models".
Through extensive experiments, the researchers demonstrate that LLMs trained on StyleTalk are able to generate responses that better match the speaking style and personality of the conversational partner, compared to models trained on standard written text corpora. This represents an important step towards link to "Transforming LLMs into Cross-Modal, Cross-Lingual Agents" and link to "Speech Translation and Speech Foundation Models for Large Language Models".
Critical Analysis
The paper provides a valuable contribution by introducing the StyleTalk dataset and demonstrating its utility for training LLMs to better handle spoken dialogue. However, the researchers acknowledge that the dataset is still relatively small, and further work is needed to scale up these techniques to broader conversational domains.
Additionally, the paper does not explore the potential biases or limitations that may arise when training LLMs on a constrained set of conversational data. There may be concerns around the representativeness of the speakers and topics covered in StyleTalk, and how that could influence the model's performance and fairness.
Future research could also investigate techniques for link to "Bootstrapping Language and Speech Pre-Training via Joint Modeling" to further bridge the gap between written and spoken language understanding in LLMs.
Conclusion
This paper represents an important step towards developing large language models that can engage in more natural, contextually-appropriate spoken conversation. By introducing the StyleTalk dataset and demonstrating its value for training LLMs, the researchers have laid the groundwork for significant advancements in conversational AI.
As these techniques mature, we can expect to see substantial improvements in areas like virtual assistants, chatbots, and voice interfaces - where the ability to communicate in a more human-like manner can greatly enhance the user experience and the perceived intelligence of the system.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

PSLM: Parallel Generation of Text and Speech with LLMs for Low-Latency Spoken Dialogue Systems
Kentaro Mitsui, Koh Mitsuda, Toshiaki Wakatsuki, Yukiya Hono, Kei Sawada
0
0
Multimodal language models that process both text and speech have a potential for applications in spoken dialogue systems. However, current models face two major challenges in response generation latency: (1) generating a spoken response requires the prior generation of a written response, and (2) speech sequences are significantly longer than text sequences. This study addresses these issues by extending the input and output sequences of the language model to support the parallel generation of text and speech. Our experiments on spoken question answering tasks demonstrate that our approach improves latency while maintaining the quality of response content. Additionally, we show that latency can be further reduced by generating speech in multiple sequences. Demo samples are available at https://rinnakk.github.io/research/publications/PSLM.
6/19/2024
Prompting Large Language Models with Audio for General-Purpose Speech Summarization
Wonjune Kang, Deb Roy
0
0
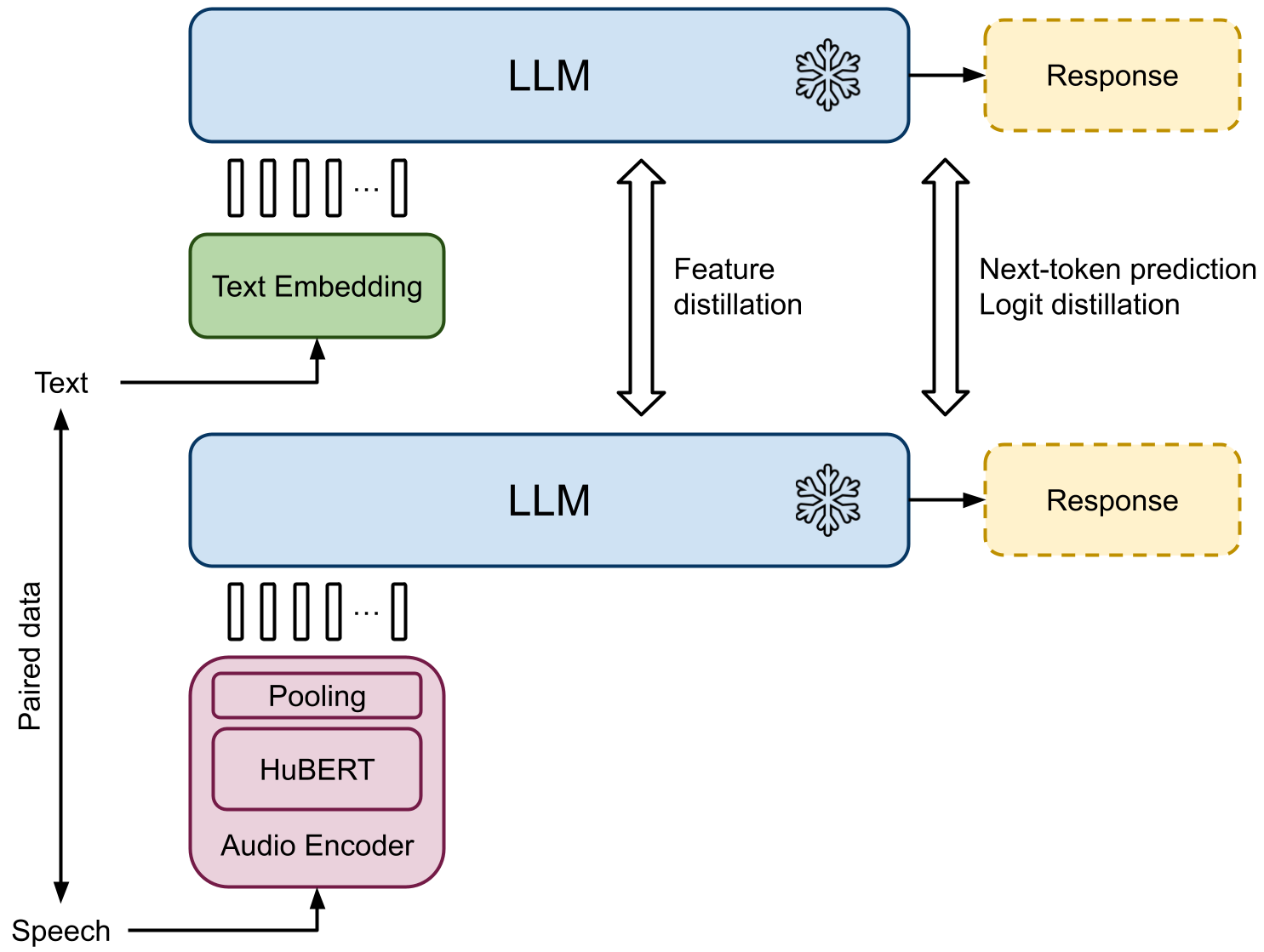
In this work, we introduce a framework for speech summarization that leverages the processing and reasoning capabilities of large language models (LLMs). We propose an end-to-end system that combines an instruction-tuned LLM with an audio encoder that converts speech into token representations that the LLM can interpret. Using a dataset with paired speech-text data, the overall system is trained to generate consistent responses to prompts with the same semantic information regardless of the input modality. The resulting framework allows the LLM to process speech inputs in the same way as text, enabling speech summarization by simply prompting the LLM. Unlike prior approaches, our method is able to summarize spoken content from any arbitrary domain, and it can produce summaries in different styles by varying the LLM prompting strategy. Experiments demonstrate that our approach outperforms a cascade baseline of speech recognition followed by LLM text processing.
6/11/2024
Large Language Model based Situational Dialogues for Second Language Learning
Shuyao Xu, Long Qin, Tianyang Chen, Zhenzhou Zha, Bingxue Qiu, Weizhi Wang
0
0
In second language learning, scenario-based conversation practice is important for language learners to achieve fluency in speaking, but students often lack sufficient opportunities to practice their conversational skills with qualified instructors or native speakers. To bridge this gap, we propose situational dialogue models for students to engage in conversational practice. Our situational dialogue models are fine-tuned on large language models (LLMs), with the aim of combining the engaging nature of an open-ended conversation with the focused practice of scenario-based tasks. Leveraging the generalization capabilities of LLMs, we demonstrate that our situational dialogue models perform effectively not only on training topics but also on topics not encountered during training. This offers a promising solution to support a wide range of conversational topics without extensive manual work. Additionally, research in the field of dialogue systems still lacks reliable automatic evaluation metrics, leading to human evaluation as the gold standard (Smith et al., 2022), which is typically expensive. To address the limitations of existing evaluation methods, we present a novel automatic evaluation method that employs fine-tuned LLMs to efficiently and effectively assess the performance of situational dialogue models.
4/1/2024

Transforming LLMs into Cross-modal and Cross-lingual RetrievalSystems
Frank Palma Gomez, Ramon Sanabria, Yun-hsuan Sung, Daniel Cer, Siddharth Dalmia, Gustavo Hernandez Abrego
0
0
Large language models (LLMs) are trained on text-only data that go far beyond the languages with paired speech and text data. At the same time, Dual Encoder (DE) based retrieval systems project queries and documents into the same embedding space and have demonstrated their success in retrieval and bi-text mining. To match speech and text in many languages, we propose using LLMs to initialize multi-modal DE retrieval systems. Unlike traditional methods, our system doesn't require speech data during LLM pre-training and can exploit LLM's multilingual text understanding capabilities to match speech and text in languages unseen during retrieval training. Our multi-modal LLM-based retrieval system is capable of matching speech and text in 102 languages despite only training on 21 languages. Our system outperforms previous systems trained explicitly on all 102 languages. We achieve a 10% absolute improvement in Recall@1 averaged across these languages. Additionally, our model demonstrates cross-lingual speech and text matching, which is further enhanced by readily available machine translation data.
4/5/2024