BLSP: Bootstrapping Language-Speech Pre-training via Behavior Alignment of Continuation Writing
2309.00916
0
0
🤔
Abstract
The emergence of large language models (LLMs) has sparked significant interest in extending their remarkable language capabilities to speech. However, modality alignment between speech and text still remains an open problem. Current solutions can be categorized into two strategies. One is a cascaded approach where outputs (tokens or states) of a separately trained speech recognition system are used as inputs for LLMs, which limits their potential in modeling alignment between speech and text. The other is an end-to-end approach that relies on speech instruction data, which is very difficult to collect in large quantities. In this paper, we address these issues and propose the BLSP approach that Bootstraps Language-Speech Pre-training via behavior alignment of continuation writing. We achieve this by learning a lightweight modality adapter between a frozen speech encoder and an LLM, ensuring that the LLM exhibits the same generation behavior regardless of the modality of input: a speech segment or its transcript. The training process can be divided into two steps. The first step prompts an LLM to generate texts with speech transcripts as prefixes, obtaining text continuations. In the second step, these continuations are used as supervised signals to train the modality adapter in an end-to-end manner. We demonstrate that this straightforward process can extend the capabilities of LLMs to speech, enabling speech recognition, speech translation, spoken language understanding, and speech conversation, even in zero-shot cross-lingual scenarios.
Create account to get full access
Overview
- Researchers propose a new approach called BLSP (Bootstraps Language-Speech Pre-training) to align speech and text in large language models (LLMs).
- Current solutions either use a cascaded approach with separate speech recognition and language models or rely on scarce speech instruction data.
- BLSP uses a lightweight modality adapter to enable LLMs to exhibit the same generation behavior for both speech and text inputs, without requiring large speech datasets.
Plain English Explanation
The paper addresses the challenge of getting large language models (LLMs) to work well with speech, not just text. Current approaches either use separate speech recognition and language models, which limits their potential, or require hard-to-find speech instruction data, as in this example.
The researchers' solution, called BLSP, is a clever way to train a "modality adapter" that allows LLMs to handle speech and text inputs equally well. This involves prompting the LLM to generate text continuations from speech transcripts, then using those continuations to train the adapter.
This straightforward approach lets the LLM extend its capabilities to speech recognition, translation, understanding, and conversation, even across languages, without needing large speech datasets. It's an innovative way to align speech and language in large language models.
Technical Explanation
The BLSP approach has two key steps:
-
The researchers prompt an LLM to generate text continuations from speech transcripts as input. This allows the LLM to exhibit the same generation behavior regardless of whether the input is speech or text.
-
They then use these text continuations as supervised signals to train a lightweight "modality adapter" that maps speech inputs to the LLM's internal representations. This enables the LLM to handle speech inputs while maintaining its strong language abilities.
By training the modality adapter in this way, the researchers can extend the LLM's capabilities to various speech-related tasks like recognition, translation, and conversation, even in zero-shot cross-lingual scenarios. The approach is straightforward and does not require collecting large speech instruction datasets, which are difficult to obtain.
Critical Analysis
The paper presents a clever and resourceful approach to the challenge of aligning speech and text in large language models. By leveraging the LLM's existing text generation abilities, the researchers are able to sidestep the need for extensive speech data, which is a common limitation in this area of research.
That said, the paper does not provide a detailed analysis of the limitations or failure modes of the BLSP approach. It would be helpful to understand the specific types of speech data or tasks where the method may struggle, as well as any performance trade-offs compared to other solutions.
Additionally, the paper does not explore the potential biases or fairness issues that may arise from using an LLM as the foundation for speech-related applications. As these models can reflect societal biases, it would be important to investigate how the BLSP approach may amplify or mitigate such concerns.
Overall, the BLSP method represents an innovative step forward in bridging the gap between speech and language models. Further research into its robustness and potential pitfalls would help strengthen the foundation for deploying such techniques in real-world applications.
Conclusion
The BLSP approach proposed in this paper offers a novel solution to the challenge of aligning speech and text in large language models. By training a lightweight modality adapter using the LLM's own text generation capabilities, the researchers have found a way to extend the model's abilities to speech-related tasks without relying on scarce speech instruction data.
This work has the potential to significantly improve the performance and accessibility of speech-enabled applications powered by large language models. By eliminating the need for separate speech recognition systems, the BLSP method could lead to more integrated and efficient multimodal AI systems.
Moving forward, further research into the robustness and fairness implications of this approach will be important to ensure it can be deployed responsibly. But the core innovation presented in this paper represents an exciting step forward in bridging the gap between speech and language in the era of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

BLSP-KD: Bootstrapping Language-Speech Pre-training via Knowledge Distillation
Chen Wang, Minpeng Liao, Zhongqiang Huang, Jiajun Zhang
0
0
Recent end-to-end approaches have shown promise in extending large language models (LLMs) to speech inputs, but face limitations in directly assessing and optimizing alignment quality and fail to achieve fine-grained alignment due to speech-text length mismatch. We introduce BLSP-KD, a novel approach for Bootstrapping Language-Speech Pretraining via Knowledge Distillation, which addresses these limitations through two key techniques. First, it optimizes speech-text alignment by minimizing the divergence between the LLM's next-token prediction distributions for speech and text inputs using knowledge distillation. Second, it employs a continuous-integrate-andfire strategy to segment speech into tokens that correspond one-to-one with text tokens, enabling fine-grained alignment. We also introduce Partial LoRA (PLoRA), a new adaptation method supporting LLM finetuning for speech inputs under knowledge distillation. Quantitative evaluation shows that BLSP-KD outperforms previous end-to-end baselines and cascaded systems with comparable scale of parameters, facilitating general instruction-following capabilities for LLMs with speech inputs. This approach provides new possibilities for extending LLMs to spoken language interactions.
5/30/2024

Transferable speech-to-text large language model alignment module
Boyong Wu, Chao Yan, Haoran Pu
0
0
By leveraging the power of Large Language Models(LLMs) and speech foundation models, state of the art speech-text bimodal works can achieve challenging tasks like spoken translation(ST) and question answering(SQA) altogether with much simpler architectures. In this paper, we utilize the capability of Whisper encoder and pre-trained Yi-6B. Empirical results reveal that modal alignment can be achieved with one layer module and hundred hours of speech-text multitask corpus. We further swap the Yi-6B with human preferences aligned version of Yi-6B-Chat during inference, and discover that the alignment capability is applicable as well. In addition, the alignment subspace revealed by singular value decomposition(SVD) also implies linear alignment subspace is sparse, which leaves the possibility to concatenate other features like voice-print or video to expand modality.
6/21/2024

BLSP-Emo: Towards Empathetic Large Speech-Language Models
Chen Wang, Minpeng Liao, Zhongqiang Huang, Junhong Wu, Chengqing Zong, Jiajun Zhang
0
0
The recent release of GPT-4o showcased the potential of end-to-end multimodal models, not just in terms of low latency but also in their ability to understand and generate expressive speech with rich emotions. While the details are unknown to the open research community, it likely involves significant amounts of curated data and compute, neither of which is readily accessible. In this paper, we present BLSP-Emo (Bootstrapped Language-Speech Pretraining with Emotion support), a novel approach to developing an end-to-end speech-language model capable of understanding both semantics and emotions in speech and generate empathetic responses. BLSP-Emo utilizes existing speech recognition (ASR) and speech emotion recognition (SER) datasets through a two-stage process. The first stage focuses on semantic alignment, following recent work on pretraining speech-language models using ASR data. The second stage performs emotion alignment with the pretrained speech-language model on an emotion-aware continuation task constructed from SER data. Our experiments demonstrate that the BLSP-Emo model excels in comprehending speech and delivering empathetic responses, both in instruction-following tasks and conversations.
6/7/2024
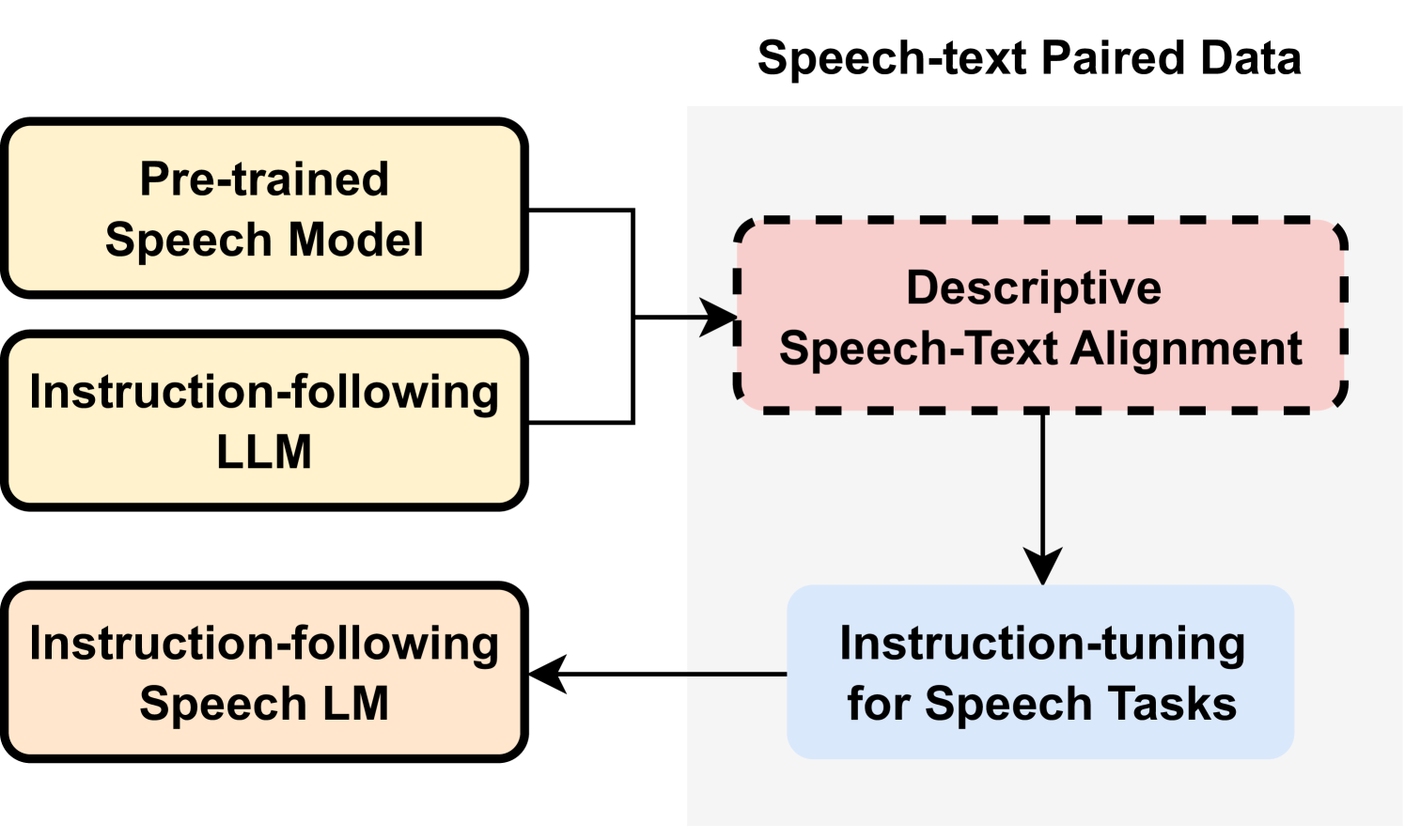
DeSTA: Enhancing Speech Language Models through Descriptive Speech-Text Alignment
Ke-Han Lu, Zhehuai Chen, Szu-Wei Fu, He Huang, Boris Ginsburg, Yu-Chiang Frank Wang, Hung-yi Lee
0
0
Recent speech language models (SLMs) typically incorporate pre-trained speech models to extend the capabilities from large language models (LLMs). In this paper, we propose a Descriptive Speech-Text Alignment approach that leverages speech captioning to bridge the gap between speech and text modalities, enabling SLMs to interpret and generate comprehensive natural language descriptions, thereby facilitating the capability to understand both linguistic and non-linguistic features in speech. Enhanced with the proposed approach, our model demonstrates superior performance on the Dynamic-SUPERB benchmark, particularly in generalizing to unseen tasks. Moreover, we discover that the aligned model exhibits a zero-shot instruction-following capability without explicit speech instruction tuning. These findings highlight the potential to reshape instruction-following SLMs by incorporating rich, descriptive speech captions.
6/28/2024