PSLM: Parallel Generation of Text and Speech with LLMs for Low-Latency Spoken Dialogue Systems
2406.12428
0
0

Abstract
Multimodal language models that process both text and speech have a potential for applications in spoken dialogue systems. However, current models face two major challenges in response generation latency: (1) generating a spoken response requires the prior generation of a written response, and (2) speech sequences are significantly longer than text sequences. This study addresses these issues by extending the input and output sequences of the language model to support the parallel generation of text and speech. Our experiments on spoken question answering tasks demonstrate that our approach improves latency while maintaining the quality of response content. Additionally, we show that latency can be further reduced by generating speech in multiple sequences. Demo samples are available at https://rinnakk.github.io/research/publications/PSLM.
Create account to get full access
Overview
- The paper proposes a new system called PSLM (Parallel Speech and Language Model) that can generate text and speech in parallel for low-latency spoken dialogue systems.
- PSLM uses large language models (LLMs) to generate both text and speech simultaneously, enabling faster response times compared to traditional approaches.
- The authors claim PSLM can achieve significant reductions in latency while maintaining high quality in both text and speech output.
Plain English Explanation
The researchers have developed a new system called PSLM that can create text and speech at the same time. This is useful for spoken dialogue systems, where a user talks to a computer and expects a quick response.
Traditionally, these systems would first generate the text response and then convert it to speech. PSLM skips this sequential process by using powerful language models to produce the text and speech in parallel. This allows the system to respond much faster, without sacrificing the quality of the text or speech.
The key innovation is using large language models (LLMs) - advanced AI models that can understand and generate human-like text - to do both the text and speech generation at the same time. This improves on previous approaches that required separate models for text and speech.
By generating the text and speech in parallel, PSLM can provide responses to users much quicker than traditional systems. This is important for spoken dialogue applications, like virtual assistants, where low latency is crucial for natural conversations.
Technical Explanation
PSLM (Parallel Speech and Language Model) is a novel system that leverages large language models (LLMs) to generate text and speech in parallel for low-latency spoken dialogue applications.
The architecture of PSLM consists of two main components: a text generation module and a speech generation module. The text generation module uses an LLM to produce the textual response to the user's input. Simultaneously, the speech generation module takes the generated text and converts it to high-quality synthetic speech using a cross-modal and cross-lingual LLM.
This parallel processing allows PSLM to significantly reduce the overall latency compared to traditional approaches, which would generate the text first and then convert it to speech. The authors demonstrate that PSLM can achieve latency reductions of up to 50% while maintaining comparable quality in both text and speech output.
To further improve efficiency, the researchers also propose a conversational SimulMT approach that enables PSLM to start generating speech before the full text response is available, further reducing latency.
The authors evaluate PSLM on a variety of spoken dialogue benchmarks and show that it outperforms state-of-the-art sequential text-to-speech systems in terms of latency, while preserving high quality in both text and speech. They also demonstrate the versatility of PSLM by fine-tuning it on different languages and domains.
Critical Analysis
The PSLM paper presents a promising approach to improving the latency of spoken dialogue systems, but there are a few potential limitations and areas for further research:
-
The authors focus primarily on latency reduction and do not provide a comprehensive analysis of the trade-offs between latency, text quality, and speech quality. It would be helpful to understand how PSLM's performance compares to state-of-the-art systems on these other metrics.
-
The paper does not address the computational and resource requirements of running PSLM, which could be a significant consideration for real-world deployment, especially on resource-constrained devices.
-
While the authors demonstrate the versatility of PSLM through fine-tuning on different languages and domains, the evaluation is still limited to a relatively small set of benchmarks. Further testing on a wider range of scenarios would help validate the generalizability of the approach.
-
The paper does not explore the potential ethical implications of deploying a system like PSLM in sensitive applications, such as healthcare or education, where high-quality text and speech generation are critical.
Overall, the PSLM system represents an important step forward in improving the latency of spoken dialogue systems. However, future research should explore the broader performance trade-offs, scalability, and ethical considerations to fully assess the real-world impact of this technology.
Conclusion
The PSLM system proposed in this paper is a significant advancement in the field of spoken dialogue systems. By leveraging powerful large language models to generate text and speech in parallel, PSLM can achieve substantial reductions in latency while maintaining high quality in both outputs.
This is a critical innovation for applications where low-latency responses are essential, such as virtual assistants, conversational AI, and other interactive voice-based systems. The authors have demonstrated the effectiveness of PSLM on a range of benchmarks and shown its versatility across different languages and domains.
While the paper identifies some potential limitations and areas for further research, the core ideas behind PSLM have the potential to transform the way we design and deploy spoken dialogue systems, ultimately leading to more natural and responsive conversational experiences for users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
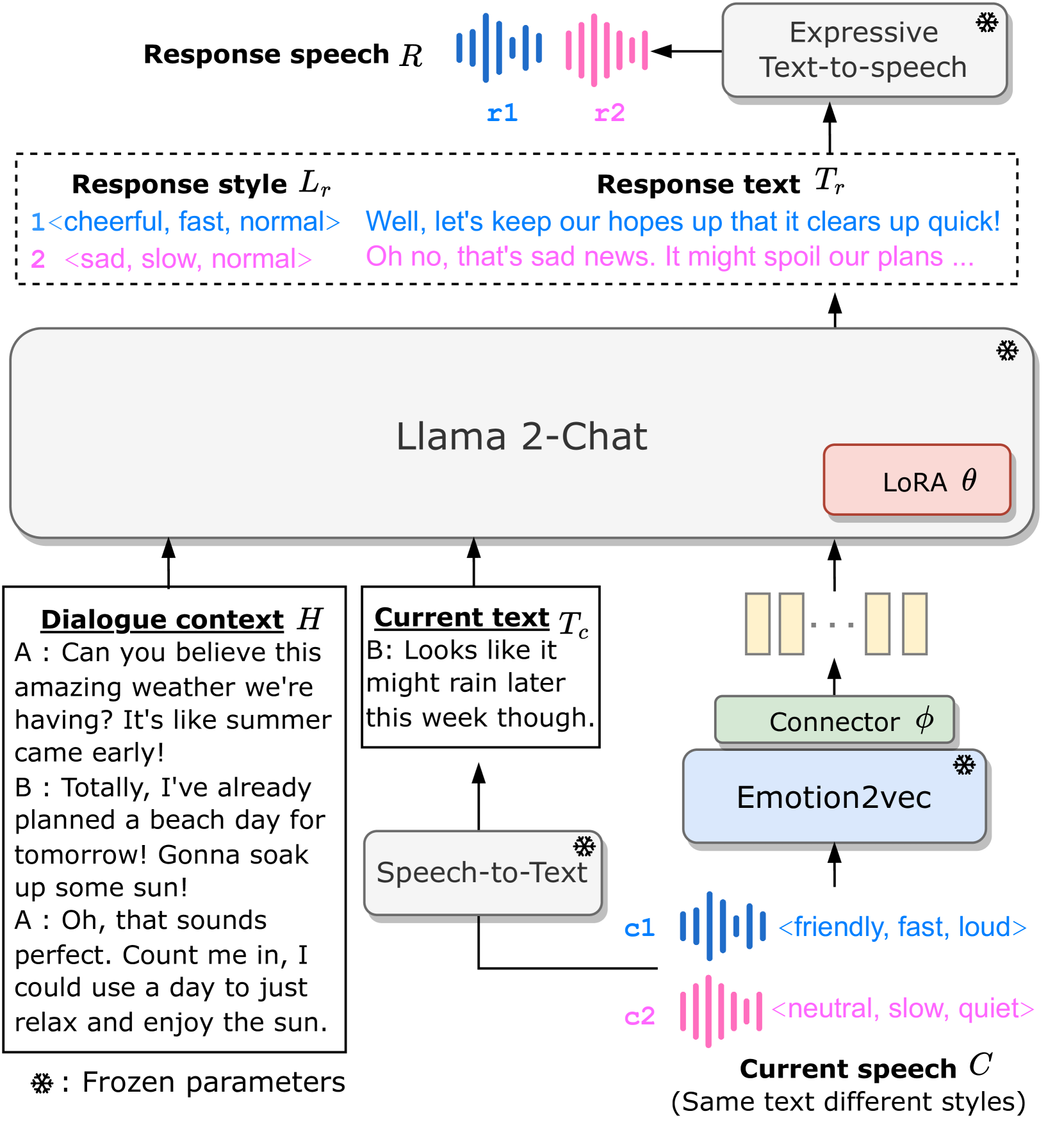
Advancing Large Language Models to Capture Varied Speaking Styles and Respond Properly in Spoken Conversations
Guan-Ting Lin, Cheng-Han Chiang, Hung-yi Lee
0
0
In spoken dialogue, even if two current turns are the same sentence, their responses might still differ when they are spoken in different styles. The spoken styles, containing paralinguistic and prosodic information, mark the most significant difference between text and speech modality. When using text-only LLMs to model spoken dialogue, text-only LLMs cannot give different responses based on the speaking style of the current turn. In this paper, we focus on enabling LLMs to listen to the speaking styles and respond properly. Our goal is to teach the LLM that even if the sentences are identical if they are spoken in different styles, their corresponding responses might be different. Since there is no suitable dataset for achieving this goal, we collect a speech-to-speech dataset, StyleTalk, with the following desired characteristics: when two current speeches have the same content but are spoken in different styles, their responses will be different. To teach LLMs to understand and respond properly to the speaking styles, we propose the Spoken-LLM framework that can model the linguistic content and the speaking styles. We train Spoken-LLM using the StyleTalk dataset and devise a two-stage training pipeline to help the Spoken-LLM better learn the speaking styles. Based on extensive experiments, we show that Spoken-LLM outperforms text-only baselines and prior speech LLMs methods.
5/31/2024
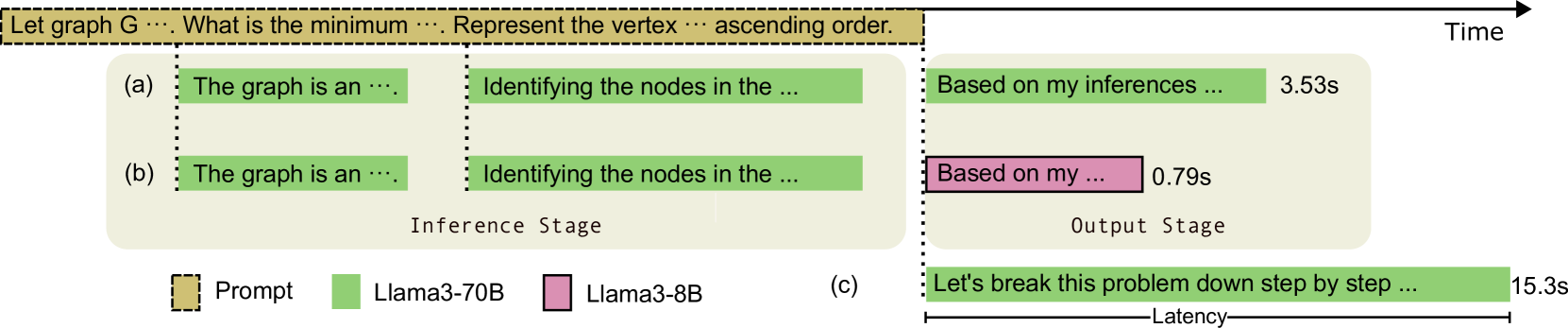
LiveMind: Low-latency Large Language Models with Simultaneous Inference
Chuangtao Chen, Grace Li Zhang, Xunzhao Yin, Cheng Zhuo, Ulf Schlichtmann, Bing Li
0
0
In this paper, we introduce a novel low-latency inference framework for large language models (LLMs) inference which enables LLMs to perform inferences with incomplete prompts. By reallocating computational processes to prompt input phase, we achieve a substantial reduction in latency, thereby significantly enhancing the interactive experience for users of LLMs. The framework adeptly manages the visibility of the streaming prompt to the model, allowing it to infer from incomplete prompts or await additional prompts. Compared with traditional inference methods that utilize complete prompts, our approach demonstrates an average reduction of 59% in response latency on the MMLU-Pro dataset, while maintaining comparable accuracy. Additionally, our framework facilitates collaborative inference and output across different models. By employing an LLM for inference and a small language model (SLM) for output, we achieve an average 68% reduction in response latency, alongside a 5.5% improvement in accuracy on the MMLU-Pro dataset compared with the SLM baseline. For long prompts exceeding 20 sentences, the response latency can be reduced by up to 93%.
6/21/2024
🗣️
A Full-duplex Speech Dialogue Scheme Based On Large Language Models
Peng Wang, Songshuo Lu, Yaohua Tang, Sijie Yan, Yuanjun Xiong, Wei Xia
0
0
We present a generative dialogue system capable of operating in a full-duplex manner, allowing for seamless interaction. It is based on a large language model (LLM) carefully aligned to be aware of a perception module, a motor function module, and the concept of a simple finite state machine (called neural FSM) with two states. The perception and motor function modules operate simultaneously, allowing the system to simultaneously speak and listen to the user. The LLM generates textual tokens for inquiry responses and makes autonomous decisions to start responding to, wait for, or interrupt the user by emitting control tokens to the neural FSM. All these tasks of the LLM are carried out as next token prediction on a serialized view of the dialogue in real-time. In automatic quality evaluations simulating real-life interaction, the proposed system reduces the average conversation response latency by more than 3 folds compared with LLM-based half-duplex dialogue systems while responding within less than 500 milliseconds in more than 50% of evaluated interactions. Running a LLM with only 8 billion parameters, our system exhibits a 8% higher interruption precision rate than the best available commercial LLM for voice-based dialogue.
5/31/2024

Transforming LLMs into Cross-modal and Cross-lingual RetrievalSystems
Frank Palma Gomez, Ramon Sanabria, Yun-hsuan Sung, Daniel Cer, Siddharth Dalmia, Gustavo Hernandez Abrego
0
0
Large language models (LLMs) are trained on text-only data that go far beyond the languages with paired speech and text data. At the same time, Dual Encoder (DE) based retrieval systems project queries and documents into the same embedding space and have demonstrated their success in retrieval and bi-text mining. To match speech and text in many languages, we propose using LLMs to initialize multi-modal DE retrieval systems. Unlike traditional methods, our system doesn't require speech data during LLM pre-training and can exploit LLM's multilingual text understanding capabilities to match speech and text in languages unseen during retrieval training. Our multi-modal LLM-based retrieval system is capable of matching speech and text in 102 languages despite only training on 21 languages. Our system outperforms previous systems trained explicitly on all 102 languages. We achieve a 10% absolute improvement in Recall@1 averaged across these languages. Additionally, our model demonstrates cross-lingual speech and text matching, which is further enhanced by readily available machine translation data.
4/5/2024