Adversarial Attacks on Hidden Tasks in Multi-Task Learning

0

Sign in to get full access
Overview
- This research paper explores how adversarial attacks can target "hidden tasks" in multi-task learning models, which are additional tasks the model learns alongside the primary task.
- The authors demonstrate that adversaries can leverage these hidden tasks to launch effective attacks, even when the primary task is well-protected.
- The paper provides insights into the vulnerabilities of multi-task learning models and the importance of considering hidden tasks when designing defenses against adversarial attacks.
Plain English Explanation
Machine learning models are often trained to perform multiple tasks simultaneously, a technique called multi-task learning. While the primary task might be well-protected against adversarial attacks, the model may also learn "hidden tasks" that are not as carefully secured. Researchers have found that adversaries can exploit these hidden tasks to launch effective attacks, even when the main task appears secure.
In this paper, the authors investigate this vulnerability in multi-task learning models. They demonstrate how adversaries can target the hidden tasks to compromise the model's overall performance, including the primary task. This is a concerning discovery, as it suggests that focusing solely on protecting the main task may not be enough to safeguard these models against malicious attacks.
Previous research has explored adversarial attacks on single-task models, but this work highlights the additional challenges posed by multi-task learning. The authors provide insights into the inner workings of these complex models and how their hidden capabilities can be exploited by determined adversaries.
Technical Explanation
The researchers conducted experiments on multi-task learning models trained to perform various tasks, such as image classification, sentiment analysis, and named entity recognition. They found that adversaries could effectively target the hidden tasks within these models, even when the primary task was well-protected against adversarial attacks.
By crafting adversarial examples tailored to the hidden tasks, the researchers were able to degrade the model's overall performance, including its accuracy on the main task. This vulnerability arises from the model's need to balance its learning across multiple objectives, which can leave some tasks more exposed to attacks than others.
Further research has explored the transferability of adversarial examples across different tasks and models, highlighting the broader implications of this work. The authors suggest that future defenses against adversarial attacks should consider the model's entire learning process, not just the primary task.
Critical Analysis
The research presented in this paper raises important concerns about the security of multi-task learning models. While the authors have demonstrated the feasibility of these attacks, there are still open questions about the real-world impact and practical implications.
Some studies have explored the challenges of transferring adversarial examples between different tasks and architectures, which could limit the practicality of these attacks in certain scenarios. Additionally, the authors acknowledge that their experiments were conducted on relatively simple multi-task learning models, and more complex real-world systems may be better equipped to mitigate these vulnerabilities.
Further research is needed to understand the extent to which these hidden task attacks can be generalized and the effectiveness of potential countermeasures. As the use of multi-task learning continues to grow, it is crucial to thoroughly investigate these security concerns and develop robust defenses to protect these models from malicious exploitation.
Conclusion
This research paper sheds light on a significant vulnerability in multi-task learning models, where adversaries can target hidden tasks to compromise the overall performance of the system. The authors provide valuable insights into the complex interplay between different learning objectives within these models and the importance of considering the entire learning process when designing defenses against adversarial attacks.
As machine learning becomes increasingly ubiquitous, it is critical to address these security challenges to ensure the reliable and trustworthy deployment of these technologies. The findings presented in this paper underscore the need for continued research and innovation in the field of adversarial machine learning, with the ultimate goal of building more secure and resilient AI systems.
Further research on the transferability of adversarial examples and the development of effective countermeasures will be crucial in strengthening the robustness of multi-task learning models and safeguarding their deployment in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Adversarial Attacks on Hidden Tasks in Multi-Task Learning
Yu Zhe, Rei Nagaike, Daiki Nishiyama, Kazuto Fukuchi, Jun Sakuma
Deep learning models are susceptible to adversarial attacks, where slight perturbations to input data lead to misclassification. Adversarial attacks become increasingly effective with access to information about the targeted classifier. In the context of multi-task learning, where a single model learns multiple tasks simultaneously, attackers may aim to exploit vulnerabilities in specific tasks with limited information. This paper investigates the feasibility of attacking hidden tasks within multi-task classifiers, where model access regarding the hidden target task and labeled data for the hidden target task are not available, but model access regarding the non-target tasks is available. We propose a novel adversarial attack method that leverages knowledge from non-target tasks and the shared backbone network of the multi-task model to force the model to forget knowledge related to the target task. Experimental results on CelebA and DeepFashion datasets demonstrate the effectiveness of our method in degrading the accuracy of hidden tasks while preserving the performance of visible tasks, contributing to the understanding of adversarial vulnerabilities in multi-task classifiers.
Read more5/29/2024

0
Cross-Task Attack: A Self-Supervision Generative Framework Based on Attention Shift
Qingyuan Zeng, Yunpeng Gong, Min Jiang
Studying adversarial attacks on artificial intelligence (AI) systems helps discover model shortcomings, enabling the construction of a more robust system. Most existing adversarial attack methods only concentrate on single-task single-model or single-task cross-model scenarios, overlooking the multi-task characteristic of artificial intelligence systems. As a result, most of the existing attacks do not pose a practical threat to a comprehensive and collaborative AI system. However, implementing cross-task attacks is highly demanding and challenging due to the difficulty in obtaining the real labels of different tasks for the same picture and harmonizing the loss functions across different tasks. To address this issue, we propose a self-supervised Cross-Task Attack framework (CTA), which utilizes co-attention and anti-attention maps to generate cross-task adversarial perturbation. Specifically, the co-attention map reflects the area to which different visual task models pay attention, while the anti-attention map reflects the area that different visual task models neglect. CTA generates cross-task perturbations by shifting the attention area of samples away from the co-attention map and closer to the anti-attention map. We conduct extensive experiments on multiple vision tasks and the experimental results confirm the effectiveness of the proposed design for adversarial attacks.
Read more7/19/2024
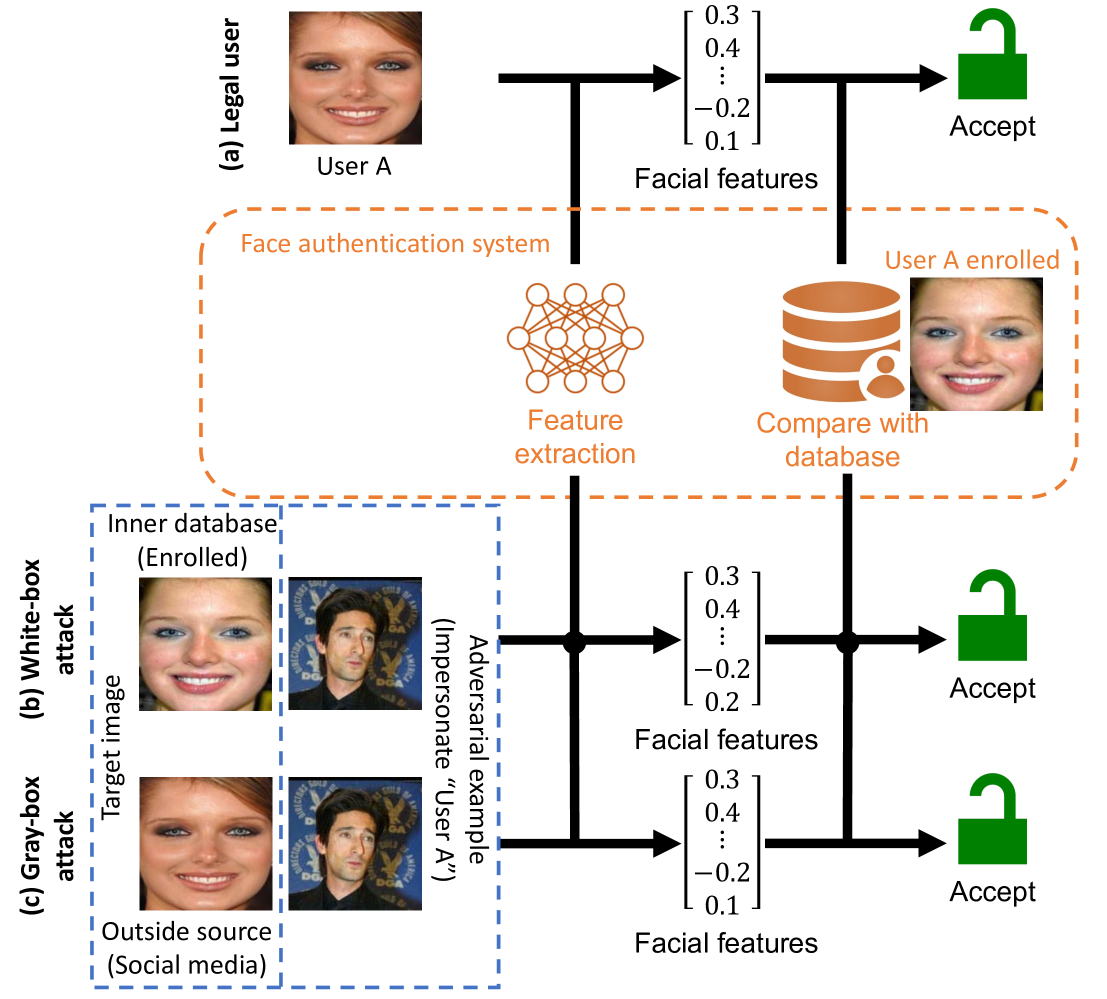
0
A Multi-task Adversarial Attack Against Face Authentication
Hanrui Wang, Shuo Wang, Cunjian Chen, Massimo Tistarelli, Zhe Jin
Deep-learning-based identity management systems, such as face authentication systems, are vulnerable to adversarial attacks. However, existing attacks are typically designed for single-task purposes, which means they are tailored to exploit vulnerabilities unique to the individual target rather than being adaptable for multiple users or systems. This limitation makes them unsuitable for certain attack scenarios, such as morphing, universal, transferable, and counter attacks. In this paper, we propose a multi-task adversarial attack algorithm called MTADV that are adaptable for multiple users or systems. By interpreting these scenarios as multi-task attacks, MTADV is applicable to both single- and multi-task attacks, and feasible in the white- and gray-box settings. Furthermore, MTADV is effective against various face datasets, including LFW, CelebA, and CelebA-HQ, and can work with different deep learning models, such as FaceNet, InsightFace, and CurricularFace. Importantly, MTADV retains its feasibility as a single-task attack targeting a single user/system. To the best of our knowledge, MTADV is the first adversarial attack method that can target all of the aforementioned scenarios in one algorithm.
Read more8/16/2024

0
Persistent Backdoor Attacks in Continual Learning
Zhen Guo, Abhinav Kumar, Reza Tourani
Backdoor attacks pose a significant threat to neural networks, enabling adversaries to manipulate model outputs on specific inputs, often with devastating consequences, especially in critical applications. While backdoor attacks have been studied in various contexts, little attention has been given to their practicality and persistence in continual learning, particularly in understanding how the continual updates to model parameters, as new data distributions are learned and integrated, impact the effectiveness of these attacks over time. To address this gap, we introduce two persistent backdoor attacks-Blind Task Backdoor and Latent Task Backdoor-each leveraging minimal adversarial influence. Our blind task backdoor subtly alters the loss computation without direct control over the training process, while the latent task backdoor influences only a single task's training, with all other tasks trained benignly. We evaluate these attacks under various configurations, demonstrating their efficacy with static, dynamic, physical, and semantic triggers. Our results show that both attacks consistently achieve high success rates across different continual learning algorithms, while effectively evading state-of-the-art defenses, such as SentiNet and I-BAU.
Read more9/24/2024