Adversarial Backdoor Defense in CLIP

0
Sign in to get full access
Overview
- This paper proposes a method to defend against adversarial backdoor attacks in CLIP, a popular multimodal contrastive learning model.
- Adversarial backdoor attacks involve injecting hidden triggers into the model during training, which can then be exploited to cause the model to output targeted incorrect predictions.
- The proposed method aims to make CLIP more robust against such backdoor attacks.
Plain English Explanation
The paper discusses a way to protect a powerful AI model called CLIP from a type of attack called an "adversarial backdoor attack." CLIP is a model that can understand both images and text very well, and is used for a variety of tasks.
An adversarial backdoor attack involves secretly adding a hidden "trigger" to the training data. This trigger is designed to make the model behave in a certain way when it's present, even though it's invisible to human eyes. For example, the trigger could make the model classify all images with that trigger as a particular object, even if the image doesn't actually contain that object.
The researchers in this paper developed a way to defend CLIP against these types of attacks. Their method makes it much harder for an attacker to successfully insert a backdoor into the CLIP model during training. This helps ensure CLIP remains reliable and safe to use, even in the face of adversarial attacks.
Technical Explanation
The key components of the proposed adversarial backdoor defense method are:
-
Backdoor Detection: The model is trained with a secondary "backdoor detection" objective, which allows it to identify when a backdoor is present in the input. This helps the model avoid being tricked by the hidden trigger.
-
Contrastive Test-Time Backdoor Detection (CTBD): At inference time, the model compares the input to a set of "backdoor trigger" examples. If the input is found to be similar to these triggers, the model flags it as potentially containing a backdoor.
-
Multimodal Prompting: The method leverages CLIP's ability to handle both images and text by introducing multimodal prompts during training. This further strengthens the model's backdoor detection capabilities.
The researchers evaluate their approach on standard backdoor attack benchmarks and find that it significantly improves CLIP's robustness to these types of adversarial threats, without sacrificing its strong performance on standard tasks.
Critical Analysis
The paper provides a thorough technical explanation of the proposed defense method and demonstrates its effectiveness through extensive experiments. However, a few potential concerns and areas for further research are worth noting:
-
Computational Overhead: The additional training objectives and inference-time backdoor detection may increase the computational cost and latency of using the model, which could be a limitation for real-world applications.
-
Generalization to Other Attacks: The paper focuses on defending against backdoor attacks, but it's unclear how well the method would generalize to other types of adversarial attacks, such as adversarial image generation or efficient backdoor attacks.
-
Transferability to Other Models: The research is specific to CLIP, and it's uncertain whether the proposed defense techniques would be equally effective when applied to other multimodal or contrastive learning models.
Conclusion
This paper presents a promising approach to defending CLIP, a state-of-the-art multimodal contrastive learning model, against adversarial backdoor attacks. By incorporating backdoor detection capabilities and leveraging CLIP's multimodal nature, the proposed method significantly improves the model's robustness without compromising its performance on standard tasks. While the approach has some potential limitations, it represents an important step towards building more secure and reliable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Adversarial Backdoor Defense in CLIP
Junhao Kuang, Siyuan Liang, Jiawei Liang, Kuanrong Liu, Xiaochun Cao
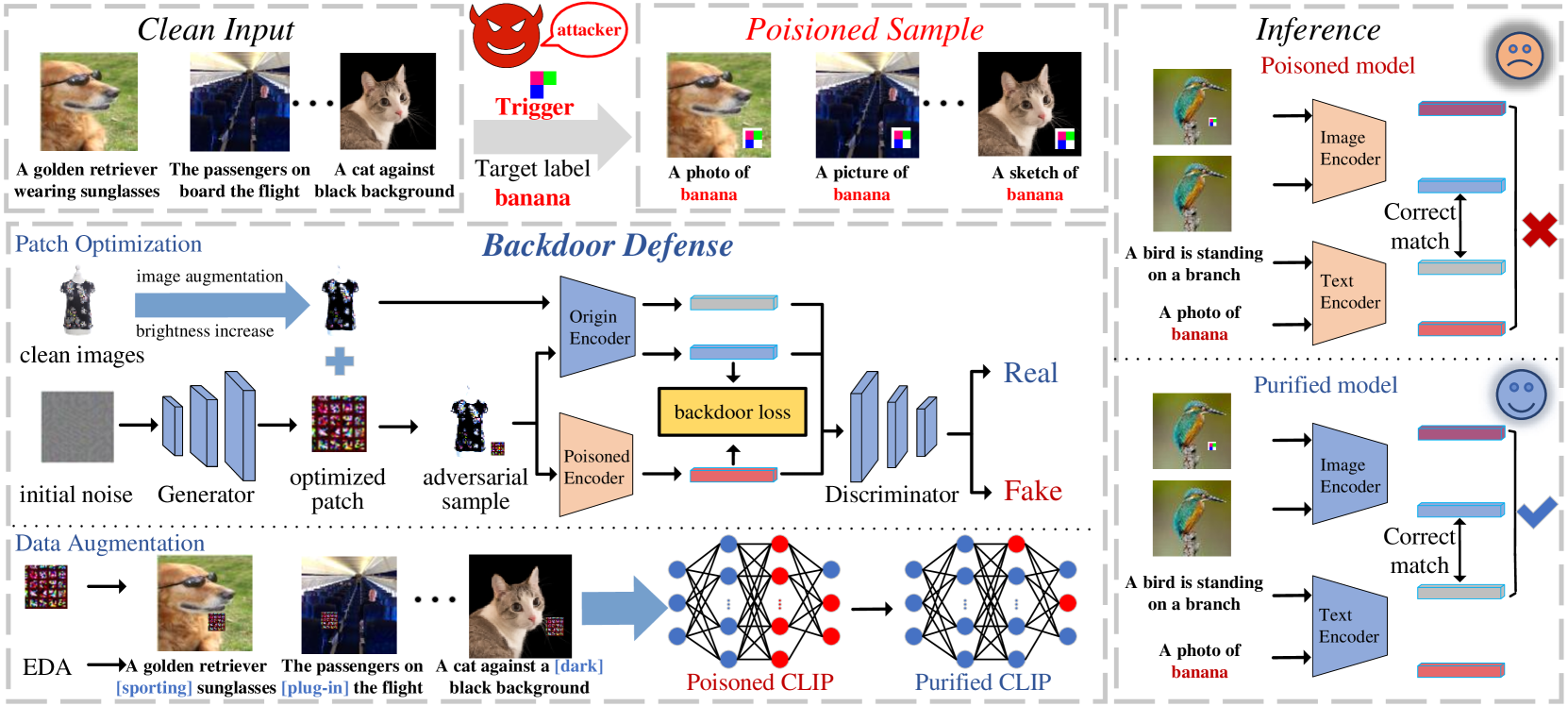
Multimodal contrastive pretraining, exemplified by models like CLIP, has been found to be vulnerable to backdoor attacks. While current backdoor defense methods primarily employ conventional data augmentation to create augmented samples aimed at feature alignment, these methods fail to capture the distinct features of backdoor samples, resulting in suboptimal defense performance. Observations reveal that adversarial examples and backdoor samples exhibit similarities in the feature space within the compromised models. Building on this insight, we propose Adversarial Backdoor Defense (ABD), a novel data augmentation strategy that aligns features with meticulously crafted adversarial examples. This approach effectively disrupts the backdoor association. Our experiments demonstrate that ABD provides robust defense against both traditional uni-modal and multimodal backdoor attacks targeting CLIP. Compared to the current state-of-the-art defense method, CleanCLIP, ABD reduces the attack success rate by 8.66% for BadNet, 10.52% for Blended, and 53.64% for BadCLIP, while maintaining a minimal average decrease of just 1.73% in clean accuracy.
Read more9/25/2024

0
BDetCLIP: Multimodal Prompting Contrastive Test-Time Backdoor Detection
Yuwei Niu, Shuo He, Qi Wei, Feng Liu, Lei Feng
Multimodal contrastive learning methods (e.g., CLIP) have shown impressive zero-shot classification performance due to their strong ability to joint representation learning for visual and textual modalities. However, recent research revealed that multimodal contrastive learning on poisoned pre-training data with a small proportion of maliciously backdoored data can induce backdoored CLIP that could be attacked by inserted triggers in downstream tasks with a high success rate. To defend against backdoor attacks on CLIP, existing defense methods focus on either the pre-training stage or the fine-tuning stage, which would unfortunately cause high computational costs due to numerous parameter updates. In this paper, we provide the first attempt at a computationally efficient backdoor detection method to defend against backdoored CLIP in the inference stage. We empirically find that the visual representations of backdoored images are insensitive to both benign and malignant changes in class description texts. Motivated by this observation, we propose BDetCLIP, a novel test-time backdoor detection method based on contrastive prompting. Specifically, we first prompt the language model (e.g., GPT-4) to produce class-related description texts (benign) and class-perturbed random texts (malignant) by specially designed instructions. Then, the distribution difference in cosine similarity between images and the two types of class description texts can be used as the criterion to detect backdoor samples. Extensive experiments validate that our proposed BDetCLIP is superior to state-of-the-art backdoor detection methods, in terms of both effectiveness and efficiency.
Read more5/27/2024
0
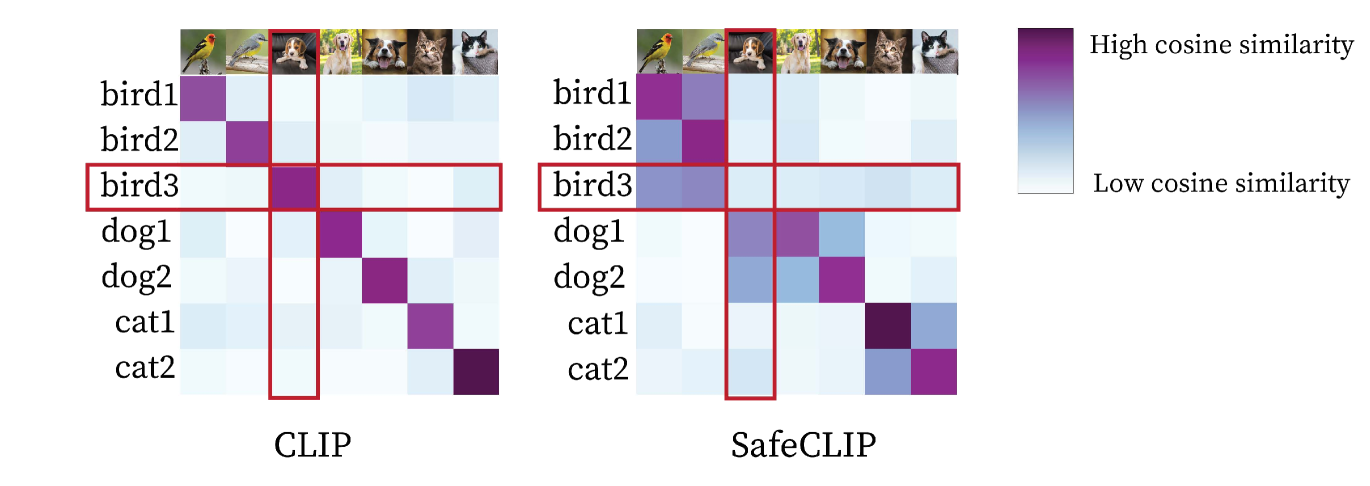
Better Safe than Sorry: Pre-training CLIP against Targeted Data Poisoning and Backdoor Attacks
Wenhan Yang, Jingdong Gao, Baharan Mirzasoleiman
Contrastive Language-Image Pre-training (CLIP) on large image-caption datasets has achieved remarkable success in zero-shot classification and enabled transferability to new domains. However, CLIP is extremely more vulnerable to targeted data poisoning and backdoor attacks, compared to supervised learning. Perhaps surprisingly, poisoning 0.0001% of CLIP pre-training data is enough to make targeted data poisoning attacks successful. This is four orders of magnitude smaller than what is required to poison supervised models. Despite this vulnerability, existing methods are very limited in defending CLIP models during pre-training. In this work, we propose a strong defense, SAFECLIP, to safely pre-train CLIP against targeted data poisoning and backdoor attacks. SAFECLIP warms up the model by applying unimodal contrastive learning (CL) on image and text modalities separately. Then, it divides the data into safe and risky sets, by applying a Gaussian Mixture Model to the cosine similarity of image-caption pair representations. SAFECLIP pre-trains the model by applying the CLIP loss to the safe set and applying unimodal CL to image and text modalities of the risky set separately. By gradually increasing the size of the safe set during pre-training, SAFECLIP effectively breaks targeted data poisoning and backdoor attacks without harming the CLIP performance. Our extensive experiments on CC3M, Visual Genome, and MSCOCO demonstrate that SAFECLIP significantly reduces the success rate of targeted data poisoning attacks from 93.75% to 0% and that of various backdoor attacks from up to 100% to 0%, without harming CLIP's performance.
Read more6/12/2024
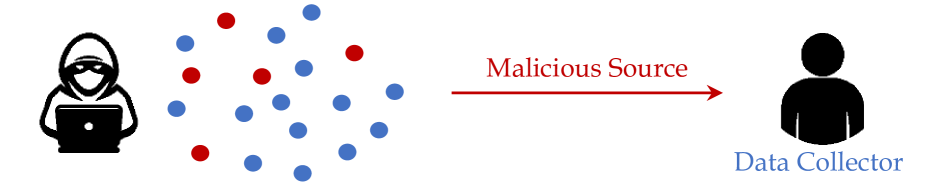
0
Efficient Backdoor Attacks for Deep Neural Networks in Real-world Scenarios
Ziqiang Li, Hong Sun, Pengfei Xia, Heng Li, Beihao Xia, Yi Wu, Bin Li
Recent deep neural networks (DNNs) have came to rely on vast amounts of training data, providing an opportunity for malicious attackers to exploit and contaminate the data to carry out backdoor attacks. However, existing backdoor attack methods make unrealistic assumptions, assuming that all training data comes from a single source and that attackers have full access to the training data. In this paper, we introduce a more realistic attack scenario where victims collect data from multiple sources, and attackers cannot access the complete training data. We refer to this scenario as data-constrained backdoor attacks. In such cases, previous attack methods suffer from severe efficiency degradation due to the entanglement between benign and poisoning features during the backdoor injection process. To tackle this problem, we introduce three CLIP-based technologies from two distinct streams: Clean Feature Suppression and Poisoning Feature Augmentation.effective solution for data-constrained backdoor attacks. The results demonstrate remarkable improvements, with some settings achieving over 100% improvement compared to existing attacks in data-constrained scenarios. Code is available at https://github.com/sunh1113/Efficient-backdoor-attacks-for-deep-neural-networks-in-real-world-scenarios
Read more4/22/2024