Better Safe than Sorry: Pre-training CLIP against Targeted Data Poisoning and Backdoor Attacks
2310.05862
0
0
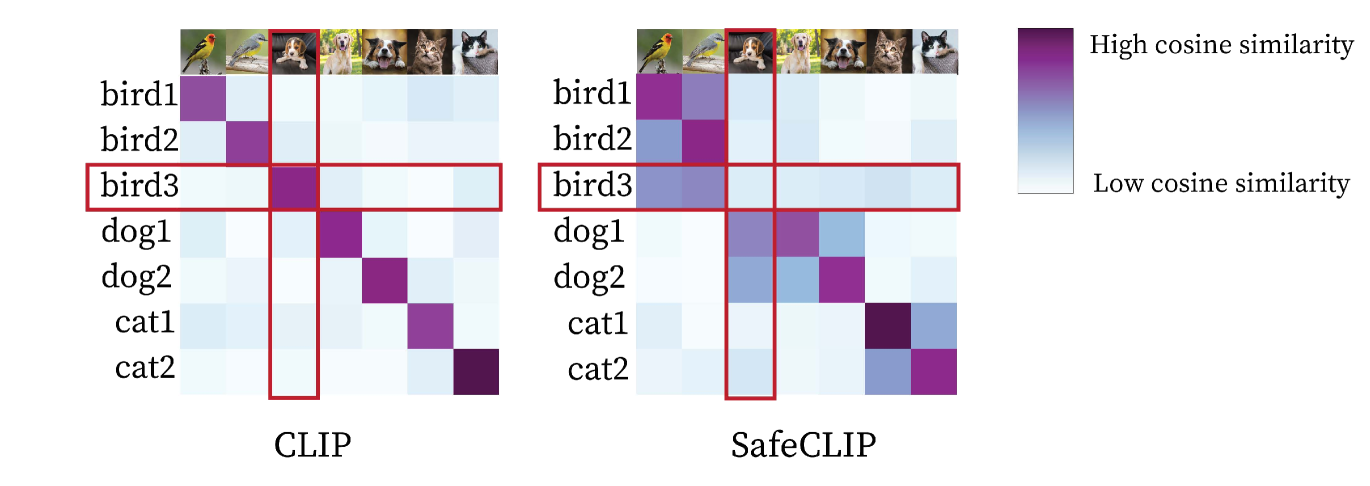
Abstract
Contrastive Language-Image Pre-training (CLIP) on large image-caption datasets has achieved remarkable success in zero-shot classification and enabled transferability to new domains. However, CLIP is extremely more vulnerable to targeted data poisoning and backdoor attacks, compared to supervised learning. Perhaps surprisingly, poisoning 0.0001% of CLIP pre-training data is enough to make targeted data poisoning attacks successful. This is four orders of magnitude smaller than what is required to poison supervised models. Despite this vulnerability, existing methods are very limited in defending CLIP models during pre-training. In this work, we propose a strong defense, SAFECLIP, to safely pre-train CLIP against targeted data poisoning and backdoor attacks. SAFECLIP warms up the model by applying unimodal contrastive learning (CL) on image and text modalities separately. Then, it divides the data into safe and risky sets, by applying a Gaussian Mixture Model to the cosine similarity of image-caption pair representations. SAFECLIP pre-trains the model by applying the CLIP loss to the safe set and applying unimodal CL to image and text modalities of the risky set separately. By gradually increasing the size of the safe set during pre-training, SAFECLIP effectively breaks targeted data poisoning and backdoor attacks without harming the CLIP performance. Our extensive experiments on CC3M, Visual Genome, and MSCOCO demonstrate that SAFECLIP significantly reduces the success rate of targeted data poisoning attacks from 93.75% to 0% and that of various backdoor attacks from up to 100% to 0%, without harming CLIP's performance.
Create account to get full access
Overview
- This paper examines techniques to protect vision-language models like CLIP against targeted data poisoning and backdoor attacks.
- The researchers present a novel pre-training method that can make CLIP more robust against these types of adversarial threats.
- Their approach involves pre-training CLIP to avoid learning associations with "NSFW" (not safe for work) concepts, which can be exploited by attackers.
Plain English Explanation
Machine learning models like CLIP, which can understand and generate text based on visual inputs, have become increasingly powerful and useful. However, these models can also be vulnerable to targeted attacks, where an adversary tries to manipulate the model's behavior in harmful ways.
One type of attack is called "data poisoning," where the attacker introduces malicious data into the model's training process. Another is a "backdoor" attack, where the attacker injects a hidden trigger into the model that can be exploited later. These attacks can cause the model to make incorrect or biased predictions, which can be dangerous in real-world applications.
To address these threats, the researchers in this paper developed a new pre-training technique for CLIP. Their key insight is that by training CLIP to avoid learning associations with "NSFW" concepts, they can make it more robust against targeted data poisoning and backdoor attacks. The rationale is that these types of attacks often rely on exploiting the model's sensitivity to certain types of content, so by reducing this sensitivity, the model becomes less vulnerable.
The researchers demonstrate that their pre-training approach can significantly improve CLIP's performance on adversarial benchmarks, without compromising its accuracy on standard tasks. This suggests that their technique could be a valuable tool for making vision-language models more secure and reliable in real-world applications.
Technical Explanation
The paper introduces a novel pre-training method called "Safe CLIP" that aims to make CLIP more robust against targeted data poisoning and backdoor attacks. The key idea is to pre-train CLIP to avoid learning associations with "NSFW" (not safe for work) concepts, which can be exploited by attackers to manipulate the model's behavior.
The researchers first construct a dataset of NSFW images and captions, which they use to fine-tune CLIP in a contrastive learning setup. This encourages CLIP to learn representations that distinguish NSFW content from non-NSFW content. They then assess the effectiveness of this approach using a range of adversarial benchmarks, including targeted data poisoning and backdoor attacks.
Their experiments show that Safe CLIP significantly outperforms the standard CLIP model on these adversarial tasks, while maintaining competitive performance on standard vision-language benchmarks. The authors attribute this improved robustness to CLIP's reduced sensitivity to the types of visual and textual features that are often exploited in targeted attacks.
The paper also presents a comprehensive analysis of the learned representations in Safe CLIP, shedding light on the mechanisms underlying its improved resilience to adversarial threats. Additionally, the researchers investigate the trade-offs between robustness and standard task performance, and discuss potential limitations and future research directions.
Critical Analysis
The paper presents a well-designed and thorough investigation into techniques for improving the robustness of vision-language models like CLIP. The researchers' approach of pre-training CLIP to avoid NSFW concepts is a creative and promising solution to the problem of targeted data poisoning and backdoor attacks.
One potential limitation of the study is the reliance on a specific definition of "NSFW" content, which may not capture all the ways that attackers could try to exploit a model's vulnerabilities. The researchers acknowledge this and suggest that exploring more diverse types of "sensitive" content could be an area for future research.
Additionally, while the paper demonstrates impressive improvements in adversarial robustness, it would be valuable to further investigate the practical implications and limitations of this approach. For example, how well does it generalize to different application domains, and how does it compare to other potential defenses against these types of attacks?
Overall, this paper makes a valuable contribution to the important problem of securing vision-language models against adversarial threats. The researchers' creative approach and rigorous analysis set a strong foundation for future work in this area.
Conclusion
This paper presents a novel pre-training technique called "Safe CLIP" that can make CLIP, a powerful vision-language model, more robust against targeted data poisoning and backdoor attacks. By training CLIP to avoid learning associations with "NSFW" concepts, the researchers were able to significantly improve its performance on a range of adversarial benchmarks, without compromising its accuracy on standard tasks.
The insights and techniques developed in this paper could have important implications for the broader field of machine learning security, as vision-language models become increasingly widely deployed in real-world applications. By making these models more resilient to targeted attacks, the research helps pave the way for their safe and reliable use in high-stakes domains.
Overall, this paper serves as a valuable contribution to the ongoing efforts to develop more secure and trustworthy artificial intelligence systems. Its combination of technical rigor and practical relevance make it an important resource for both researchers and practitioners in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
Safe-CLIP: Removing NSFW Concepts from Vision-and-Language Models
Samuele Poppi, Tobia Poppi, Federico Cocchi, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara
0
0
Large-scale vision-and-language models, such as CLIP, are typically trained on web-scale data, which can introduce inappropriate content and lead to the development of unsafe and biased behavior. This, in turn, hampers their applicability in sensitive and trustworthy contexts and could raise significant concerns in their adoption. Our research introduces a novel approach to enhancing the safety of vision-and-language models by diminishing their sensitivity to NSFW (not safe for work) inputs. In particular, our methodology seeks to sever toxic linguistic and visual concepts, unlearning the linkage between unsafe linguistic or visual items and unsafe regions of the embedding space. We show how this can be done by fine-tuning a CLIP model on synthetic data obtained from a large language model trained to convert between safe and unsafe sentences, and a text-to-image generator. We conduct extensive experiments on the resulting embedding space for cross-modal retrieval, text-to-image, and image-to-text generation, where we show that our model can be remarkably employed with pre-trained generative models. Our source code and trained models are available at: https://github.com/aimagelab/safe-clip.
4/15/2024

BDetCLIP: Multimodal Prompting Contrastive Test-Time Backdoor Detection
Yuwei Niu, Shuo He, Qi Wei, Feng Liu, Lei Feng
0
0
Multimodal contrastive learning methods (e.g., CLIP) have shown impressive zero-shot classification performance due to their strong ability to joint representation learning for visual and textual modalities. However, recent research revealed that multimodal contrastive learning on poisoned pre-training data with a small proportion of maliciously backdoored data can induce backdoored CLIP that could be attacked by inserted triggers in downstream tasks with a high success rate. To defend against backdoor attacks on CLIP, existing defense methods focus on either the pre-training stage or the fine-tuning stage, which would unfortunately cause high computational costs due to numerous parameter updates. In this paper, we provide the first attempt at a computationally efficient backdoor detection method to defend against backdoored CLIP in the inference stage. We empirically find that the visual representations of backdoored images are insensitive to both benign and malignant changes in class description texts. Motivated by this observation, we propose BDetCLIP, a novel test-time backdoor detection method based on contrastive prompting. Specifically, we first prompt the language model (e.g., GPT-4) to produce class-related description texts (benign) and class-perturbed random texts (malignant) by specially designed instructions. Then, the distribution difference in cosine similarity between images and the two types of class description texts can be used as the criterion to detect backdoor samples. Extensive experiments validate that our proposed BDetCLIP is superior to state-of-the-art backdoor detection methods, in terms of both effectiveness and efficiency.
5/27/2024
Fooling Contrastive Language-Image Pre-trained Models with CLIPMasterPrints
Matthias Freiberger, Peter Kun, Christian Igel, Anders Sundnes L{o}vlie, Sebastian Risi
0
0
Models leveraging both visual and textual data such as Contrastive Language-Image Pre-training (CLIP), are the backbone of many recent advances in artificial intelligence. In this work, we show that despite their versatility, such models are vulnerable to what we refer to as fooling master images. Fooling master images are capable of maximizing the confidence score of a CLIP model for a significant number of widely varying prompts, while being either unrecognizable or unrelated to the attacked prompts for humans. The existence of such images is problematic as it could be used by bad actors to maliciously interfere with CLIP-trained image retrieval models in production with comparably small effort as a single image can attack many different prompts. We demonstrate how fooling master images for CLIP (CLIPMasterPrints) can be mined using stochastic gradient descent, projected gradient descent, or blackbox optimization. Contrary to many common adversarial attacks, the blackbox optimization approach allows us to mine CLIPMasterPrints even when the weights of the model are not accessible. We investigate the properties of the mined images, and find that images trained on a small number of image captions generalize to a much larger number of semantically related captions. We evaluate possible mitigation strategies, where we increase the robustness of the model and introduce an approach to automatically detect CLIPMasterPrints to sanitize the input of vulnerable models. Finally, we find that vulnerability to CLIPMasterPrints is related to a modality gap in contrastive pre-trained multi-modal networks. Code available at https://github.com/matfrei/CLIPMasterPrints.
4/15/2024

RankCLIP: Ranking-Consistent Language-Image Pretraining
Yiming Zhang, Zhuokai Zhao, Zhaorun Chen, Zhili Feng, Zenghui Ding, Yining Sun
0
0
Self-supervised contrastive learning models, such as CLIP, have set new benchmarks for vision-language models in many downstream tasks. However, their dependency on rigid one-to-one mappings overlooks the complex and often multifaceted relationships between and within texts and images. To this end, we introduce RANKCLIP, a novel pretraining method that extends beyond the rigid one-to-one matching framework of CLIP and its variants. By extending the traditional pair-wise loss to list-wise, and leveraging both in-modal and cross-modal ranking consistency, RANKCLIP improves the alignment process, enabling it to capture the nuanced many-to-many relationships between and within each modality. Through comprehensive experiments, we demonstrate the effectiveness of RANKCLIP in various downstream tasks, notably achieving significant gains in zero-shot classifications over state-of-the-art methods, underscoring the importance of this enhanced learning process.
6/21/2024