BDetCLIP: Multimodal Prompting Contrastive Test-Time Backdoor Detection

0

Sign in to get full access
Overview
- Introduces BDetCLIP, a multimodal approach for detecting backdoor attacks in machine learning models at test time
- Uses contrastive learning to isolate the content and style information in images and text to identify backdoor triggers
- Proposes a test-time backdoor detection framework that leverages the CLIP model's multimodal understanding
Plain English Explanation
This research paper introduces BDetCLIP, a method for detecting backdoor attacks in machine learning models during the testing phase. Backdoor attacks happen when a model is trained on malicious data that causes it to behave unexpectedly, like misclassifying an image when a specific trigger is present.
BDetCLIP uses the CLIP model, which can understand both images and text, to identify these backdoor triggers. It does this by separating the "content" of an image or text (the actual object or meaning) from its "style" (the visual or linguistic features). When a backdoor trigger is present, the content and style information will be misaligned, which BDetCLIP can detect.
The key idea is that by understanding the relationship between the content and style of an input, BDetCLIP can identify when that relationship has been tampered with through a backdoor attack. This allows it to catch these attacks at test time, before the model is deployed in the real world.
Technical Explanation
The paper proposes a test-time backdoor detection framework called BDetCLIP that leverages the multimodal understanding of the CLIP model. CLIP is a neural network trained on a large dataset of image-text pairs, which allows it to encode both the visual and textual information of an input.
BDetCLIP works by exploiting the fact that backdoor attacks disrupt the alignment between the content and style information in an input. It does this through a contrastive learning approach, which learns to isolate the content and style representations of images and text.
Specifically, BDetCLIP uses CLIP to obtain the content and style embeddings for an input. It then calculates the cosine similarity between the content and style embeddings, which should be high for benign inputs but low for backdoored ones. This cosine similarity score is used as the basis for detecting backdoor triggers at test time.
The paper evaluates BDetCLIP on various backdoor attack settings and shows that it can effectively detect these attacks across different model architectures, datasets, and backdoor trigger types. It outperforms other state-of-the-art backdoor detection methods, demonstrating the power of leveraging multimodal understanding for this task.
Critical Analysis
The paper provides a novel and promising approach to backdoor detection by exploiting the multimodal nature of the CLIP model. The key insight of separating content and style information is well-motivated and aligns with the intuition that backdoor triggers disrupt this alignment.
However, the paper does not explore the limitations of this approach in depth. For example, it is unclear how BDetCLIP would perform in settings where the backdoor trigger is more subtle or integrated into the content itself, rather than being a distinct stylistic element. Additionally, the paper does not discuss the computational overhead of the approach or how it would scale to larger, more complex models.
Furthermore, the paper could have delved deeper into the implications and potential societal impacts of this technology. Backdoor attacks are a serious concern, and tools like BDetCLIP could play a crucial role in securing machine learning systems. Exploring these broader considerations would have strengthened the paper's contribution.
Overall, the BDetCLIP approach is a valuable contribution to the field of machine learning security, but there is still room for further research and discussion around its limitations and broader implications.
Conclusion
The BDetCLIP paper introduces a novel multimodal approach for detecting backdoor attacks in machine learning models at test time. By leveraging the content and style understanding of the CLIP model, BDetCLIP can effectively identify when the relationship between these two aspects of an input has been tampered with, indicating the presence of a backdoor trigger.
This work represents an important step forward in securing machine learning systems against these insidious attacks. As machine learning becomes more ubiquitous in critical applications, tools like BDetCLIP will be essential for ensuring the reliability and trustworthiness of these models. While the paper does not address all the potential limitations of the approach, it lays the groundwork for further research and development in this crucial area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
BDetCLIP: Multimodal Prompting Contrastive Test-Time Backdoor Detection
Yuwei Niu, Shuo He, Qi Wei, Feng Liu, Lei Feng
Multimodal contrastive learning methods (e.g., CLIP) have shown impressive zero-shot classification performance due to their strong ability to joint representation learning for visual and textual modalities. However, recent research revealed that multimodal contrastive learning on poisoned pre-training data with a small proportion of maliciously backdoored data can induce backdoored CLIP that could be attacked by inserted triggers in downstream tasks with a high success rate. To defend against backdoor attacks on CLIP, existing defense methods focus on either the pre-training stage or the fine-tuning stage, which would unfortunately cause high computational costs due to numerous parameter updates. In this paper, we provide the first attempt at a computationally efficient backdoor detection method to defend against backdoored CLIP in the inference stage. We empirically find that the visual representations of backdoored images are insensitive to both benign and malignant changes in class description texts. Motivated by this observation, we propose BDetCLIP, a novel test-time backdoor detection method based on contrastive prompting. Specifically, we first prompt the language model (e.g., GPT-4) to produce class-related description texts (benign) and class-perturbed random texts (malignant) by specially designed instructions. Then, the distribution difference in cosine similarity between images and the two types of class description texts can be used as the criterion to detect backdoor samples. Extensive experiments validate that our proposed BDetCLIP is superior to state-of-the-art backdoor detection methods, in terms of both effectiveness and efficiency.
Read more5/27/2024
0
Adversarial Backdoor Defense in CLIP
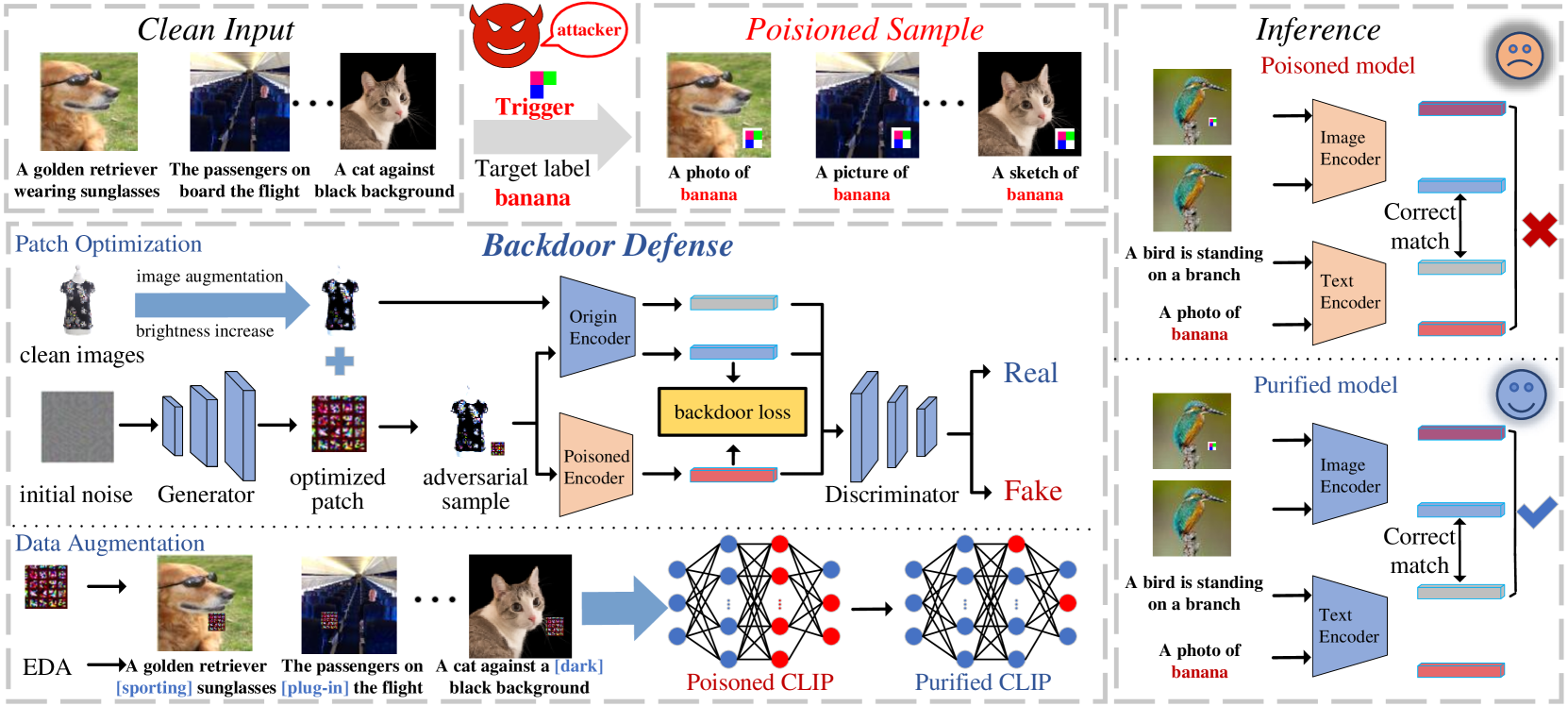
Junhao Kuang, Siyuan Liang, Jiawei Liang, Kuanrong Liu, Xiaochun Cao
Multimodal contrastive pretraining, exemplified by models like CLIP, has been found to be vulnerable to backdoor attacks. While current backdoor defense methods primarily employ conventional data augmentation to create augmented samples aimed at feature alignment, these methods fail to capture the distinct features of backdoor samples, resulting in suboptimal defense performance. Observations reveal that adversarial examples and backdoor samples exhibit similarities in the feature space within the compromised models. Building on this insight, we propose Adversarial Backdoor Defense (ABD), a novel data augmentation strategy that aligns features with meticulously crafted adversarial examples. This approach effectively disrupts the backdoor association. Our experiments demonstrate that ABD provides robust defense against both traditional uni-modal and multimodal backdoor attacks targeting CLIP. Compared to the current state-of-the-art defense method, CleanCLIP, ABD reduces the attack success rate by 8.66% for BadNet, 10.52% for Blended, and 53.64% for BadCLIP, while maintaining a minimal average decrease of just 1.73% in clean accuracy.
Read more9/25/2024
0
Better Safe than Sorry: Pre-training CLIP against Targeted Data Poisoning and Backdoor Attacks
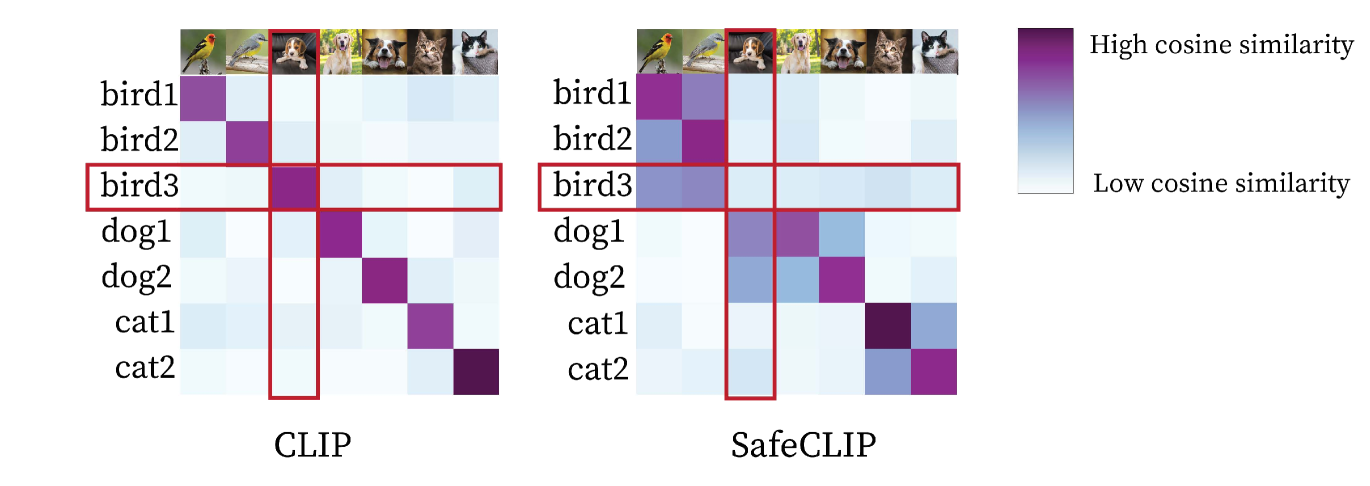
Wenhan Yang, Jingdong Gao, Baharan Mirzasoleiman
Contrastive Language-Image Pre-training (CLIP) on large image-caption datasets has achieved remarkable success in zero-shot classification and enabled transferability to new domains. However, CLIP is extremely more vulnerable to targeted data poisoning and backdoor attacks, compared to supervised learning. Perhaps surprisingly, poisoning 0.0001% of CLIP pre-training data is enough to make targeted data poisoning attacks successful. This is four orders of magnitude smaller than what is required to poison supervised models. Despite this vulnerability, existing methods are very limited in defending CLIP models during pre-training. In this work, we propose a strong defense, SAFECLIP, to safely pre-train CLIP against targeted data poisoning and backdoor attacks. SAFECLIP warms up the model by applying unimodal contrastive learning (CL) on image and text modalities separately. Then, it divides the data into safe and risky sets, by applying a Gaussian Mixture Model to the cosine similarity of image-caption pair representations. SAFECLIP pre-trains the model by applying the CLIP loss to the safe set and applying unimodal CL to image and text modalities of the risky set separately. By gradually increasing the size of the safe set during pre-training, SAFECLIP effectively breaks targeted data poisoning and backdoor attacks without harming the CLIP performance. Our extensive experiments on CC3M, Visual Genome, and MSCOCO demonstrate that SAFECLIP significantly reduces the success rate of targeted data poisoning attacks from 93.75% to 0% and that of various backdoor attacks from up to 100% to 0%, without harming CLIP's performance.
Read more6/12/2024

0
Exploring the Adversarial Robustness of CLIP for AI-generated Image Detection
Vincenzo De Rosa, Fabrizio Guillaro, Giovanni Poggi, Davide Cozzolino, Luisa Verdoliva
In recent years, many forensic detectors have been proposed to detect AI-generated images and prevent their use for malicious purposes. Convolutional neural networks (CNNs) have long been the dominant architecture in this field and have been the subject of intense study. However, recently proposed Transformer-based detectors have been shown to match or even outperform CNN-based detectors, especially in terms of generalization. In this paper, we study the adversarial robustness of AI-generated image detectors, focusing on Contrastive Language-Image Pretraining (CLIP)-based methods that rely on Visual Transformer backbones and comparing their performance with CNN-based methods. We study the robustness to different adversarial attacks under a variety of conditions and analyze both numerical results and frequency-domain patterns. CLIP-based detectors are found to be vulnerable to white-box attacks just like CNN-based detectors. However, attacks do not easily transfer between CNN-based and CLIP-based methods. This is also confirmed by the different distribution of the adversarial noise patterns in the frequency domain. Overall, this analysis provides new insights into the properties of forensic detectors that can help to develop more effective strategies.
Read more7/30/2024