Adversarial DPO: Harnessing Harmful Data for Reducing Toxicity with Minimal Impact on Coherence and Evasiveness in Dialogue Agents

0
📊
Sign in to get full access
Overview
- This paper introduces a new training algorithm called Adversarial Direct Preference Optimization (ADPO) that aims to improve the safety and resilience of open-domain dialogue systems.
- The researchers build upon the Direct Preference Optimization (DPO) algorithm, which trains models to generate responses preferred by human evaluators.
- ADPO incorporates harmful text generated by the model itself to better align the model's output with safe and preferred responses, reducing the need for manually curated safety data.
- The researchers demonstrate that ADPO enhances the model's ability to avoid unsafe conversations while minimizing performance degradation compared to standard DPO.
Plain English Explanation
Open-domain dialogue systems, powered by large language models (LLMs), have made significant advances in recent years. However, a key challenge is the presence of toxicity and harmful content within these systems, which can negatively impact the user experience.
The Direct Preference Optimization (DPO) algorithm was developed to address this issue by training models to generate responses preferred by human evaluators. The researchers in this study build on DPO with a new approach called Adversarial DPO (ADPO).
ADPO works by having the model generate its own examples of harmful text using a "toxic control token." The model is then trained to assign higher probabilities to preferred responses and lower probabilities to these self-generated unsafe responses. This helps the model learn to avoid producing harmful content while maintaining its overall performance.
Compared to traditional DPO, the researchers found that ADPO offers a more stable training process and better resilience against unsafe conversations, all while minimizing any degradation in the model's capabilities.
Technical Explanation
The researchers start by noting the limitations of existing approaches to improving the safety of open-domain dialogue systems, such as the need for manually curated safety data or the potential for performance degradation.
To address these challenges, the researchers introduce the Adversarial Direct Preference Optimization (ADPO) algorithm. ADPO builds upon the DPO framework, which trains language models to generate responses preferred by human evaluators.
The key innovation in ADPO is the incorporation of harmful text generated by the model itself, using a "toxic control token." During training, the model learns to assign higher probability distributions to preferred responses and lower distributions to its own unsafe responses. This approach reduces the need for manually created safety data, as the model can leverage its internal knowledge of harmful content.
The researchers demonstrate that ADPO enhances the model's resilience against unsafe conversations while minimizing performance degradation compared to standard DPO. They also show that ADPO offers a more stable training procedure, addressing some of the challenges associated with the traditional DPO algorithm.
Critical Analysis
The researchers acknowledge that their approach, while effective, still relies on the model's ability to generate realistic examples of harmful content. This could be a limitation, as the model may not always be able to capture the full spectrum of potential toxicity.
Additionally, the researchers note that the ADPO algorithm could potentially lead to biases or unintended consequences if the model's understanding of "preferred" responses is skewed or incomplete. Further research is needed to understand the long-term implications of this approach.
It would also be interesting to see how ADPO compares to other safety-focused techniques, such as the robust DPO approach or the development of specialized toxicity predictors. A more comprehensive evaluation across different datasets and metrics could provide valuable insights.
Conclusion
The Adversarial Direct Preference Optimization (ADPO) algorithm introduced in this paper represents a significant step forward in improving the safety and resilience of open-domain dialogue systems. By incorporating the model's own generation of harmful content into the training process, ADPO reduces the reliance on manually curated safety data while enhancing the model's ability to avoid unsafe conversations.
While the approach has limitations and requires further research, the researchers have demonstrated the potential of ADPO to address a critical challenge in the field of open-domain dialogue systems. As the development of large language models continues to advance, innovative techniques like ADPO will be crucial in ensuring these systems are safe, responsible, and beneficial to users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Adversarial DPO: Harnessing Harmful Data for Reducing Toxicity with Minimal Impact on Coherence and Evasiveness in Dialogue Agents
San Kim, Gary Geunbae Lee
Recent advancements in open-domain dialogue systems have been propelled by the emergence of high-quality large language models (LLMs) and various effective training methodologies. Nevertheless, the presence of toxicity within these models presents a significant challenge that can potentially diminish the user experience. In this study, we introduce an innovative training algorithm, an improvement upon direct preference optimization (DPO), called adversarial DPO (ADPO). The ADPO algorithm is designed to train models to assign higher probability distributions to preferred responses and lower distributions to unsafe responses, which are self-generated using the toxic control token. We demonstrate that ADPO enhances the model's resilience against harmful conversations while minimizing performance degradation. Furthermore, we illustrate that ADPO offers a more stable training procedure compared to the traditional DPO. To the best of our knowledge, this is the first adaptation of the DPO algorithm that directly incorporates harmful data into the generative model, thereby reducing the need to artificially create safe dialogue data.
Read more5/22/2024
📈
0
DeTox: Toxic Subspace Projection for Model Editing
Rheeya Uppaal, Apratim Dey, Yiting He, Yiqiao Zhong, Junjie Hu
Recent alignment algorithms such as direct preference optimization (DPO) have been developed to improve the safety of large language models (LLMs) by training these models to match human behaviors exemplified by preference data. However, these methods are both computationally intensive and lacking in controllability and transparency, making them prone to jailbreaking and inhibiting their widespread use. Furthermore, these tuning-based methods require large-scale preference data for training and are susceptible to noisy preference data. In this paper, we introduce a tuning-free alignment alternative (DeTox) and demonstrate its effectiveness under the use case of toxicity reduction. Grounded on theory from factor analysis, DeTox is a sample-efficient model editing approach that identifies a toxic subspace in the model parameter space and reduces model toxicity by projecting away the detected subspace. The toxic sub-space is identified by extracting preference data embeddings from the language model, and removing non-toxic information from these embeddings. We show that DeTox is more sample-efficient than DPO, further showcasing greater robustness to noisy data. Finally, we establish both theoretical and empirical connections between DeTox and DPO, showing that DeTox can be interpreted as a denoised version of a single DPO step.
Read more5/30/2024

0
Direct Preference Optimization with an Offset
Afra Amini, Tim Vieira, Ryan Cotterell
Direct preference optimization (DPO) is a successful fine-tuning strategy for aligning large language models with human preferences without the need to train a reward model or employ reinforcement learning. DPO, as originally formulated, relies on binary preference data and fine-tunes a language model to increase the likelihood of a preferred response over a dispreferred response. However, not all preference pairs are equal. Sometimes, the preferred response is only slightly better than the dispreferred one. In other cases, the preference is much stronger. For instance, if a response contains harmful or toxic content, the annotator will have a strong preference for that response. In this paper, we propose a generalization of DPO, termed DPO with an offset (ODPO), that does not treat every preference pair equally during fine-tuning. Intuitively, ODPO requires the difference between the likelihood of the preferred and dispreferred response to be greater than an offset value. The offset is determined based on the extent to which one response is preferred over another. Our experiments on various tasks suggest that ODPO significantly outperforms DPO in aligning language models, especially when the number of preference pairs is limited.
Read more6/7/2024
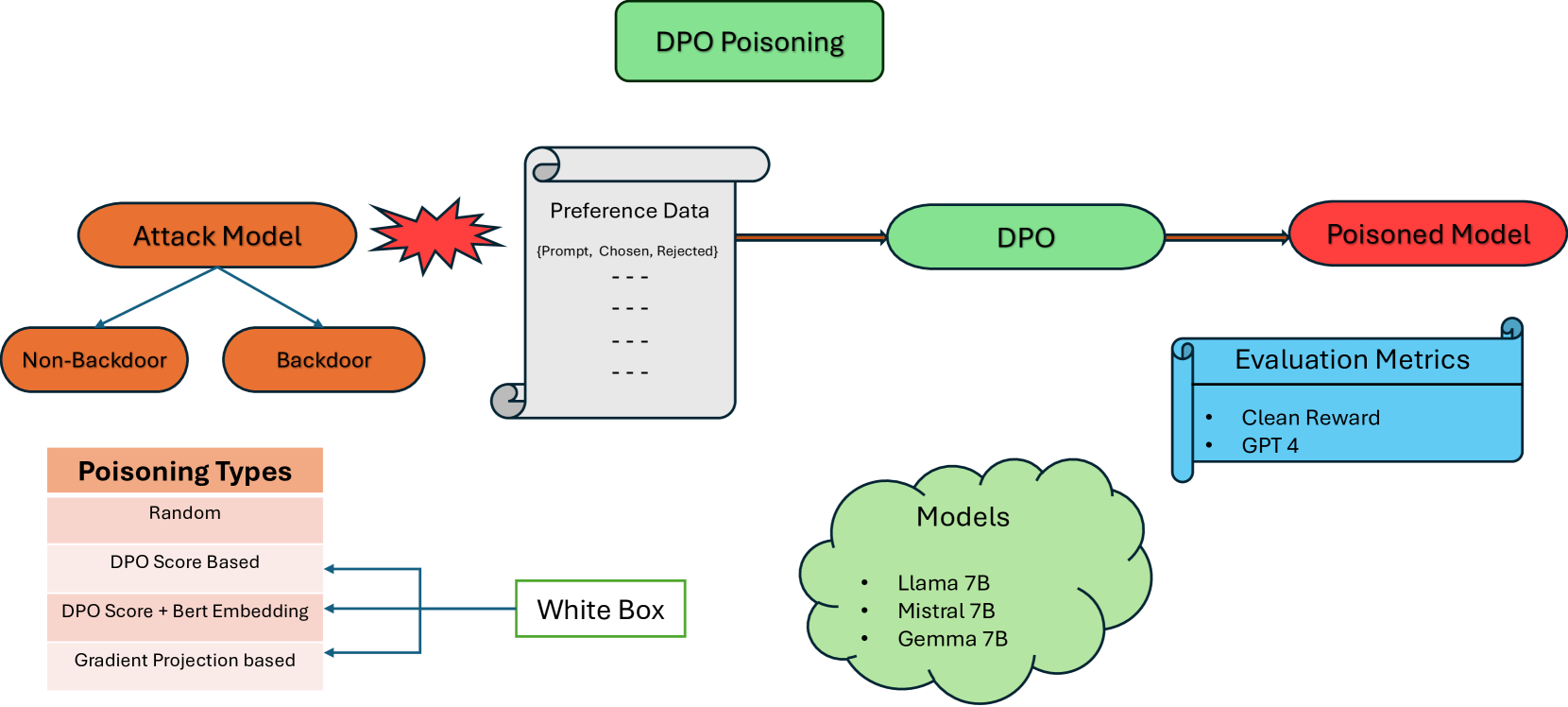
0
Is poisoning a real threat to LLM alignment? Maybe more so than you think
Pankayaraj Pathmanathan, Souradip Chakraborty, Xiangyu Liu, Yongyuan Liang, Furong Huang
Recent advancements in Reinforcement Learning with Human Feedback (RLHF) have significantly impacted the alignment of Large Language Models (LLMs). The sensitivity of reinforcement learning algorithms such as Proximal Policy Optimization (PPO) has led to new line work on Direct Policy Optimization (DPO), which treats RLHF in a supervised learning framework. The increased practical use of these RLHF methods warrants an analysis of their vulnerabilities. In this work, we investigate the vulnerabilities of DPO to poisoning attacks under different scenarios and compare the effectiveness of preference poisoning, a first of its kind. We comprehensively analyze DPO's vulnerabilities under different types of attacks, i.e., backdoor and non-backdoor attacks, and different poisoning methods across a wide array of language models, i.e., LLama 7B, Mistral 7B, and Gemma 7B. We find that unlike PPO-based methods, which, when it comes to backdoor attacks, require at least 4% of the data to be poisoned to elicit harmful behavior, we exploit the true vulnerabilities of DPO more simply so we can poison the model with only as much as 0.5% of the data. We further investigate the potential reasons behind the vulnerability and how well this vulnerability translates into backdoor vs non-backdoor attacks.
Read more6/21/2024