Adversarial Multi-Task Learning for Disentangling Timbre and Pitch in Singing Voice Synthesis

0
🐍
Sign in to get full access
Overview
- This paper explores the use of deep learning-based generative models to generate singing voices.
- Two approaches are compared: predicting parametric vocoder features and predicting mel-spectrograms for a neural vocoder.
- The paper proposes a multi-task learning model that leverages both approaches to generate more natural-sounding singing voices.
- A generative adversarial network framework is also applied to improve the quality of the generated singing voices.
Plain English Explanation
The researchers in this study were interested in using AI and machine learning to generate singing voices that sound more natural and realistic. They compared two different approaches that have been used in the past:
-
Predicting parametric vocoder features: This method uses explicit speech parameters that can be individually controlled, like pitch and timbre. The advantage is that each feature has a clear meaning, but the overall voice quality may be limited.
-
Predicting mel-spectrograms for a neural vocoder: This approach generates a spectrogram representation that can be fed into a neural network to produce the audio. The downside is that the pitch and timbre information gets entangled, making it harder to control.
The researchers developed a new model that combines both approaches - it predicts both the parametric vocoder features and the mel-spectrogram. By using the parametric features as auxiliary information, the model can more effectively separate the pitch and timbre components of the mel-spectrogram.
Additionally, the researchers used a generative adversarial network framework to further improve the quality of the generated singing voices in a multi-singer model. This helps ensure the voices sound more natural and human-like.
Technical Explanation
The key technical elements of the proposed model include:
-
Multi-task Learning: The model is trained to predict both the parametric vocoder features and the mel-spectrogram in a multi-task learning setup. This allows the model to leverage the advantages of both approaches - the explicit control of the parametric features and the flexibility of the mel-spectrogram.
-
Disentanglement of Timbre and Pitch: By using the parametric vocoder features as auxiliary information, the model can more effectively disentangle the timbre and pitch components of the mel-spectrogram. This improves the model's ability to control these important aspects of the singing voice.
-
Generative Adversarial Network (GAN): The researchers apply a GAN framework to the multi-singer singing voice synthesis task. The GAN's discriminator is trained to distinguish between real and generated singing voices, which pushes the generator model to produce more natural-sounding output.
-
Experimentation and Evaluation: The proposed model is evaluated through both objective and subjective measures, including acoustic features, Mel Cepstral Distortion, and perceptual listening tests. The results demonstrate that the multi-task learning approach with the GAN framework outperforms both the single-task parametric vocoder-based model and a conventional mel-spectrogram-based model.
Critical Analysis
The paper presents a well-designed and thorough study on improving singing voice synthesis using a multi-task learning approach and a GAN framework. Some potential areas for further research or discussion include:
-
Exploring the trade-offs between the level of control provided by the parametric features and the flexibility of the mel-spectrogram representation. The optimal balance may depend on the specific use case and desired capabilities.
-
Investigating the potential for self-supervised pitch augmentation or other techniques to further enhance the model's ability to generate diverse and expressive singing voices.
-
Considering the applicability of this approach to singer voice transformation tasks, where the goal is to modify the characteristics of an existing singing voice.
-
Addressing any potential biases or limitations in the training data or model architecture that could impact the diversity and inclusivity of the generated singing voices.
Overall, this research represents a promising step forward in the field of singing voice synthesis, demonstrating the value of combining multiple modeling approaches to achieve more natural and controllable results.
Conclusion
The proposed multi-task learning model with a GAN framework represents a significant advancement in the field of singing voice synthesis. By leveraging both parametric vocoder features and mel-spectrograms, the model can more effectively disentangle and control the timbre and pitch components of the generated singing voices, resulting in more natural-sounding output.
The successful application of this approach opens up new possibilities for realistic and expressive singing voice generation, with potential applications in music production, virtual assistants, and other areas where natural-sounding singing voices are desirable. As the field of deep learning-based audio generation continues to evolve, studies like this one will help push the boundaries of what is possible in terms of synthesizing human-like vocal performances.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🐍
0
Adversarial Multi-Task Learning for Disentangling Timbre and Pitch in Singing Voice Synthesis
Tae-Woo Kim, Min-Su Kang, Gyeong-Hoon Lee
Recently, deep learning-based generative models have been introduced to generate singing voices. One approach is to predict the parametric vocoder features consisting of explicit speech parameters. This approach has the advantage that the meaning of each feature is explicitly distinguished. Another approach is to predict mel-spectrograms for a neural vocoder. However, parametric vocoders have limitations of voice quality and the mel-spectrogram features are difficult to model because the timbre and pitch information are entangled. In this study, we propose a singing voice synthesis model with multi-task learning to use both approaches -- acoustic features for a parametric vocoder and mel-spectrograms for a neural vocoder. By using the parametric vocoder features as auxiliary features, the proposed model can efficiently disentangle and control the timbre and pitch components of the mel-spectrogram. Moreover, a generative adversarial network framework is applied to improve the quality of singing voices in a multi-singer model. Experimental results demonstrate that our proposed model can generate more natural singing voices than the single-task models, while performing better than the conventional parametric vocoder-based model.
Read more6/14/2024
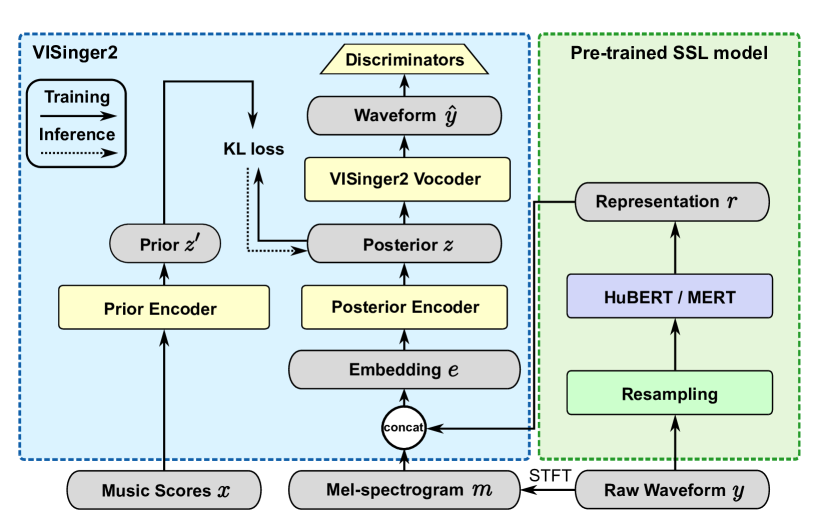
0
VISinger2+: End-to-End Singing Voice Synthesis Augmented by Self-Supervised Learning Representation
Yifeng Yu, Jiatong Shi, Yuning Wu, Shinji Watanabe
Singing Voice Synthesis (SVS) has witnessed significant advancements with the advent of deep learning techniques. However, a significant challenge in SVS is the scarcity of labeled singing voice data, which limits the effectiveness of supervised learning methods. In response to this challenge, this paper introduces a novel approach to enhance the quality of SVS by leveraging unlabeled data from pre-trained self-supervised learning models. Building upon the existing VISinger2 framework, this study integrates additional spectral feature information into the system to enhance its performance. The integration aims to harness the rich acoustic features from the pre-trained models, thereby enriching the synthesis and yielding a more natural and expressive singing voice. Experimental results in various corpora demonstrate the efficacy of this approach in improving the overall quality of synthesized singing voices in both objective and subjective metrics.
Read more6/14/2024

0
Multi-modal Adversarial Training for Zero-Shot Voice Cloning
John Janiczek, Dading Chong, Dongyang Dai, Arlo Faria, Chao Wang, Tao Wang, Yuzong Liu
A text-to-speech (TTS) model trained to reconstruct speech given text tends towards predictions that are close to the average characteristics of a dataset, failing to model the variations that make human speech sound natural. This problem is magnified for zero-shot voice cloning, a task that requires training data with high variance in speaking styles. We build off of recent works which have used Generative Advsarial Networks (GAN) by proposing a Transformer encoder-decoder architecture to conditionally discriminates between real and generated speech features. The discriminator is used in a training pipeline that improves both the acoustic and prosodic features of a TTS model. We introduce our novel adversarial training technique by applying it to a FastSpeech2 acoustic model and training on Libriheavy, a large multi-speaker dataset, for the task of zero-shot voice cloning. Our model achieves improvements over the baseline in terms of speech quality and speaker similarity. Audio examples from our system are available online.
Read more8/29/2024
🧪
0
Leveraging Diverse Semantic-based Audio Pretrained Models for Singing Voice Conversion
Xueyao Zhang, Zihao Fang, Yicheng Gu, Haopeng Chen, Lexiao Zou, Junan Zhang, Liumeng Xue, Zhizheng Wu
Singing Voice Conversion (SVC) is a technique that enables any singer to perform any song. To achieve this, it is essential to obtain speaker-agnostic representations from the source audio, which poses a significant challenge. A common solution involves utilizing a semantic-based audio pretrained model as a feature extractor. However, the degree to which the extracted features can meet the SVC requirements remains an open question. This includes their capability to accurately model melody and lyrics, the speaker-independency of their underlying acoustic information, and their robustness for in-the-wild acoustic environments. In this study, we investigate the knowledge within classical semantic-based pretrained models in much detail. We discover that the knowledge of different models is diverse and can be complementary for SVC. Based on the above, we design a Singing Voice Conversion framework based on Diverse Semantic-based Feature Fusion (DSFF-SVC). Experimental results demonstrate that DSFF-SVC can be generalized and improve various existing SVC models, particularly in challenging real-world conversion tasks. Our demo website is available at https://diversesemanticsvc.github.io/.
Read more9/17/2024