Multi-modal Adversarial Training for Zero-Shot Voice Cloning

0

Sign in to get full access
Overview
- The paper presents a novel multi-modal adversarial training approach for zero-shot voice cloning.
- The method aims to generate high-quality synthetic speech that matches the target speaker's voice, even without any samples from that speaker.
- The training process involves adversarial learning between a speech generator and a multi-modal discriminator that examines both audio and visual features.
Plain English Explanation
The researchers have developed a new way to create synthetic speech that sounds just like a specific person, even if no audio recordings of that person's voice are available. This is called "zero-shot voice cloning."
The key idea is to use a [object Object] approach. This means the system learns by competing with itself - one part tries to generate realistic-sounding speech, while another part tries to identify whether the speech is real or fake.
Importantly, the discriminator not only listens to the audio, but also examines visual features like the speaker's lip movements. By using both audio and visual cues, the system can better learn the unique characteristics of the target speaker's voice.
Through this adversarial training process, the speech generator becomes increasingly skilled at producing synthetic speech that matches the target speaker, even without any of their actual voice recordings.
Technical Explanation
The paper proposes a [object Object] framework for zero-shot voice cloning. The key components are:
- Speech Generator: A neural network that generates synthetic speech given text input and a target speaker embedding.
- Multi-modal Discriminator: A network that takes both the generated audio and corresponding video (lip movements) to determine if the speech is real or fake.
During training, the speech generator and multi-modal discriminator engage in an adversarial game. The generator tries to fool the discriminator by producing synthetic speech that matches the target speaker, while the discriminator aims to accurately distinguish real from fake speech.
By jointly optimizing the generator and discriminator using this [object Object] process, the system is able to generate high-quality synthetic speech that closely resembles the target speaker's voice, even without any of their actual speech samples.
Critical Analysis
The paper presents a promising approach for zero-shot voice cloning, but a few potential limitations are worth noting:
- The method relies on having access to videos of the target speaker, which may not always be available in practice. Further research could explore ways to relax this requirement.
- The evaluation is limited to a relatively small set of target speakers. Scaling the approach to work with a wider range of speakers may present additional challenges.
- While the generated speech quality is impressive, there could still be subtle differences compared to the real voice. Continued improvements in the adversarial training process may help further bridge this gap.
Overall, this work makes an important contribution to the field of zero-shot voice cloning, but there are still opportunities for refinement and expansion of the techniques.
Conclusion
This paper introduces a multi-modal adversarial training approach for generating synthetic speech that closely matches a target speaker's voice, even without any samples of that speaker's actual voice. By jointly optimizing a speech generator and a discriminator that examines both audio and visual cues, the system is able to produce high-quality zero-shot voice clones.
While the method has some limitations, it represents a significant step forward in the field of voice cloning and could have important applications in areas like personalized text-to-speech, voice assistants, and audio dubbing. Continued research in this direction has the potential to further improve the fidelity and versatility of synthetic speech generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-modal Adversarial Training for Zero-Shot Voice Cloning
John Janiczek, Dading Chong, Dongyang Dai, Arlo Faria, Chao Wang, Tao Wang, Yuzong Liu
A text-to-speech (TTS) model trained to reconstruct speech given text tends towards predictions that are close to the average characteristics of a dataset, failing to model the variations that make human speech sound natural. This problem is magnified for zero-shot voice cloning, a task that requires training data with high variance in speaking styles. We build off of recent works which have used Generative Advsarial Networks (GAN) by proposing a Transformer encoder-decoder architecture to conditionally discriminates between real and generated speech features. The discriminator is used in a training pipeline that improves both the acoustic and prosodic features of a TTS model. We introduce our novel adversarial training technique by applying it to a FastSpeech2 acoustic model and training on Libriheavy, a large multi-speaker dataset, for the task of zero-shot voice cloning. Our model achieves improvements over the baseline in terms of speech quality and speaker similarity. Audio examples from our system are available online.
Read more8/29/2024
0
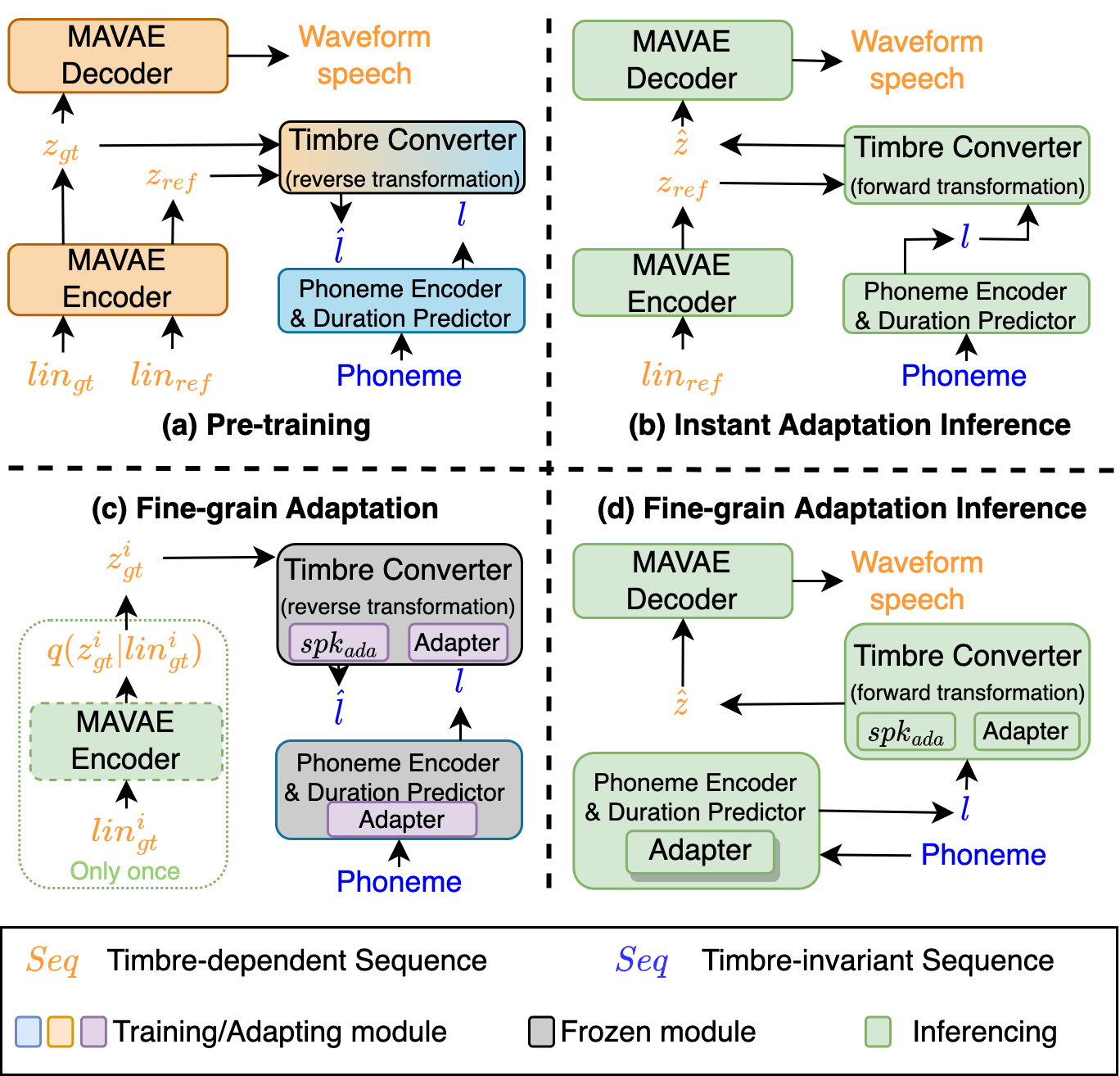
USAT: A Universal Speaker-Adaptive Text-to-Speech Approach
Wenbin Wang, Yang Song, Sanjay Jha
Conventional text-to-speech (TTS) research has predominantly focused on enhancing the quality of synthesized speech for speakers in the training dataset. The challenge of synthesizing lifelike speech for unseen, out-of-dataset speakers, especially those with limited reference data, remains a significant and unresolved problem. While zero-shot or few-shot speaker-adaptive TTS approaches have been explored, they have many limitations. Zero-shot approaches tend to suffer from insufficient generalization performance to reproduce the voice of speakers with heavy accents. While few-shot methods can reproduce highly varying accents, they bring a significant storage burden and the risk of overfitting and catastrophic forgetting. In addition, prior approaches only provide either zero-shot or few-shot adaptation, constraining their utility across varied real-world scenarios with different demands. Besides, most current evaluations of speaker-adaptive TTS are conducted only on datasets of native speakers, inadvertently neglecting a vast portion of non-native speakers with diverse accents. Our proposed framework unifies both zero-shot and few-shot speaker adaptation strategies, which we term as instant and fine-grained adaptations based on their merits. To alleviate the insufficient generalization performance observed in zero-shot speaker adaptation, we designed two innovative discriminators and introduced a memory mechanism for the speech decoder. To prevent catastrophic forgetting and reduce storage implications for few-shot speaker adaptation, we designed two adapters and a unique adaptation procedure.
Read more4/30/2024

0
Improving Language Model-Based Zero-Shot Text-to-Speech Synthesis with Multi-Scale Acoustic Prompts
Shun Lei, Yixuan Zhou, Liyang Chen, Dan Luo, Zhiyong Wu, Xixin Wu, Shiyin Kang, Tao Jiang, Yahui Zhou, Yuxing Han, Helen Meng
Zero-shot text-to-speech (TTS) synthesis aims to clone any unseen speaker's voice without adaptation parameters. By quantizing speech waveform into discrete acoustic tokens and modeling these tokens with the language model, recent language model-based TTS models show zero-shot speaker adaptation capabilities with only a 3-second acoustic prompt of an unseen speaker. However, they are limited by the length of the acoustic prompt, which makes it difficult to clone personal speaking style. In this paper, we propose a novel zero-shot TTS model with the multi-scale acoustic prompts based on a neural codec language model VALL-E. A speaker-aware text encoder is proposed to learn the personal speaking style at the phoneme-level from the style prompt consisting of multiple sentences. Following that, a VALL-E based acoustic decoder is utilized to model the timbre from the timbre prompt at the frame-level and generate speech. The experimental results show that our proposed method outperforms baselines in terms of naturalness and speaker similarity, and can achieve better performance by scaling out to a longer style prompt.
Read more4/10/2024
0
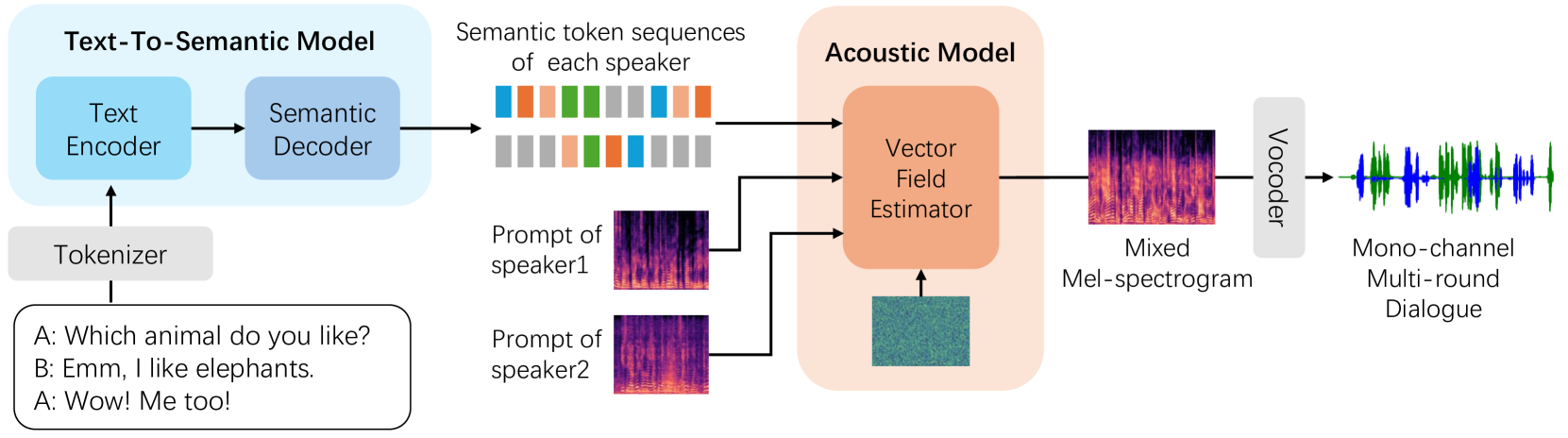
CoVoMix: Advancing Zero-Shot Speech Generation for Human-like Multi-talker Conversations
Leying Zhang, Yao Qian, Long Zhou, Shujie Liu, Dongmei Wang, Xiaofei Wang, Midia Yousefi, Yanmin Qian, Jinyu Li, Lei He, Sheng Zhao, Michael Zeng
Recent advancements in zero-shot text-to-speech (TTS) modeling have led to significant strides in generating high-fidelity and diverse speech. However, dialogue generation, along with achieving human-like naturalness in speech, continues to be a challenge. In this paper, we introduce CoVoMix: Conversational Voice Mixture Generation, a novel model for zero-shot, human-like, multi-speaker, multi-round dialogue speech generation. CoVoMix first converts dialogue text into multiple streams of discrete tokens, with each token stream representing semantic information for individual talkers. These token streams are then fed into a flow-matching based acoustic model to generate mixed mel-spectrograms. Finally, the speech waveforms are produced using a HiFi-GAN model. Furthermore, we devise a comprehensive set of metrics for measuring the effectiveness of dialogue modeling and generation. Our experimental results show that CoVoMix can generate dialogues that are not only human-like in their naturalness and coherence but also involve multiple talkers engaging in multiple rounds of conversation. This is exemplified by instances generated in a single channel where one speaker's utterance is seamlessly mixed with another's interjections or laughter, indicating the latter's role as an attentive listener. Audio samples are available at https://aka.ms/covomix.
Read more5/30/2024