AEMIM: Adversarial Examples Meet Masked Image Modeling

0

Sign in to get full access
Overview
- Presents a new approach called Adversarial Examples Meet Masked Image Modeling (AEMIM) that combines adversarial examples and masked image modeling for improved image classification.
- Leverages the strengths of both adversarial training and masked image modeling to enhance the robustness and performance of deep learning models.
- Demonstrates the effectiveness of AEMIM on multiple image classification datasets and tasks, including clean image classification, adversarial robustness, and transfer learning.
Plain English Explanation
The paper introduces a new method called AEMIM that combines two powerful techniques in deep learning: adversarial training and masked image modeling. Adversarial training helps models become more robust to adversarial attacks, which are small, imperceptible changes to an image that can cause a model to make incorrect predictions. Masked image modeling, on the other hand, is a way to pre-train models to learn rich representations of images by having the model try to predict the missing parts of partially obscured images.
By bringing these two approaches together, the researchers show that AEMIM can achieve better performance on clean image classification, better robustness against adversarial attacks, and better transfer learning capabilities compared to using just adversarial training or just masked image modeling alone. The key insight is that the two techniques complement each other - adversarial training makes the model more resilient, while masked image modeling helps the model learn more powerful and transferable visual representations.
Technical Explanation
The AEMIM approach works by first pre-training a model using masked image modeling, where the model is trained to predict the missing parts of partially obscured images. This helps the model learn rich and transferable visual representations. Then, the model is further fine-tuned using adversarial training, where the model is exposed to adversarial examples during training to improve its robustness.
The researchers evaluated AEMIM on various image classification tasks, including clean image classification, adversarial robustness, and transfer learning. They found that AEMIM outperformed models trained with just adversarial training or just masked image modeling, demonstrating the benefits of combining these two techniques.
Critical Analysis
The paper provides a promising approach to improving the robustness and performance of deep learning models for image classification. However, the researchers acknowledge that AEMIM may not be as effective for certain types of adversarial attacks, such as those that target specific semantic information in the image. Additionally, the computational and resource requirements of the combined training approach may be higher than using just one technique.
Further research could explore ways to make the AEMIM approach more efficient, as well as investigate its performance on a wider range of adversarial attacks and image classification tasks. It would also be valuable to understand the specific mechanisms by which the combination of adversarial training and masked image modeling leads to the observed improvements, which could inform the development of even more effective model training techniques.
Conclusion
The AEMIM approach presented in this paper represents an important step forward in enhancing the robustness and performance of deep learning models for image classification. By integrating adversarial training and masked image modeling, the researchers have demonstrated a powerful way to leverage the complementary strengths of these two techniques. As AI systems become increasingly ubiquitous, advances like AEMIM will be crucial in ensuring that these systems are reliable, trustworthy, and capable of handling a wide range of real-world challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AEMIM: Adversarial Examples Meet Masked Image Modeling
Wenzhao Xiang, Chang Liu, Hang Su, Hongyang Yu
Masked image modeling (MIM) has gained significant traction for its remarkable prowess in representation learning. As an alternative to the traditional approach, the reconstruction from corrupted images has recently emerged as a promising pretext task. However, the regular corrupted images are generated using generic generators, often lacking relevance to the specific reconstruction task involved in pre-training. Hence, reconstruction from regular corrupted images cannot ensure the difficulty of the pretext task, potentially leading to a performance decline. Moreover, generating corrupted images might introduce an extra generator, resulting in a notable computational burden. To address these issues, we propose to incorporate adversarial examples into masked image modeling, as the new reconstruction targets. Adversarial examples, generated online using only the trained models, can directly aim to disrupt tasks associated with pre-training. Therefore, the incorporation not only elevates the level of challenge in reconstruction but also enhances efficiency, contributing to the acquisition of superior representations by the model. In particular, we introduce a novel auxiliary pretext task that reconstructs the adversarial examples corresponding to the original images. We also devise an innovative adversarial attack to craft more suitable adversarial examples for MIM pre-training. It is noted that our method is not restricted to specific model architectures and MIM strategies, rendering it an adaptable plug-in capable of enhancing all MIM methods. Experimental findings substantiate the remarkable capability of our approach in amplifying the generalization and robustness of existing MIM methods. Notably, our method surpasses the performance of baselines on various tasks, including ImageNet, its variants, and other downstream tasks.
Read more7/17/2024
0
Masked Image Modeling: A Survey
Vlad Hondru, Florinel Alin Croitoru, Shervin Minaee, Radu Tudor Ionescu, Nicu Sebe
In this work, we survey recent studies on masked image modeling (MIM), an approach that emerged as a powerful self-supervised learning technique in computer vision. The MIM task involves masking some information, e.g. pixels, patches, or even latent representations, and training a model, usually an autoencoder, to predicting the missing information by using the context available in the visible part of the input. We identify and formalize two categories of approaches on how to implement MIM as a pretext task, one based on reconstruction and one based on contrastive learning. Then, we construct a taxonomy and review the most prominent papers in recent years. We complement the manually constructed taxonomy with a dendrogram obtained by applying a hierarchical clustering algorithm. We further identify relevant clusters via manually inspecting the resulting dendrogram. Our review also includes datasets that are commonly used in MIM research. We aggregate the performance results of various masked image modeling methods on the most popular datasets, to facilitate the comparison of competing methods. Finally, we identify research gaps and propose several interesting directions of future work.
Read more8/14/2024
0
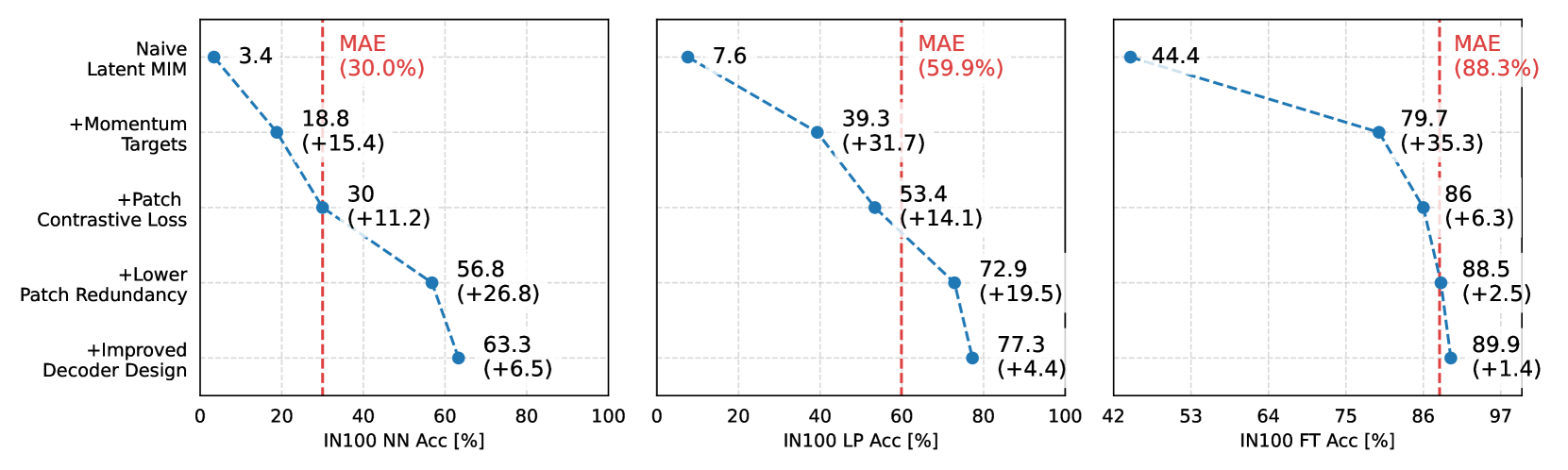
Towards Latent Masked Image Modeling for Self-Supervised Visual Representation Learning
Yibing Wei, Abhinav Gupta, Pedro Morgado
Masked Image Modeling (MIM) has emerged as a promising method for deriving visual representations from unlabeled image data by predicting missing pixels from masked portions of images. It excels in region-aware learning and provides strong initializations for various tasks, but struggles to capture high-level semantics without further supervised fine-tuning, likely due to the low-level nature of its pixel reconstruction objective. A promising yet unrealized framework is learning representations through masked reconstruction in latent space, combining the locality of MIM with the high-level targets. However, this approach poses significant training challenges as the reconstruction targets are learned in conjunction with the model, potentially leading to trivial or suboptimal solutions.Our study is among the first to thoroughly analyze and address the challenges of such framework, which we refer to as Latent MIM. Through a series of carefully designed experiments and extensive analysis, we identify the source of these challenges, including representation collapsing for joint online/target optimization, learning objectives, the high region correlation in latent space and decoding conditioning. By sequentially addressing these issues, we demonstrate that Latent MIM can indeed learn high-level representations while retaining the benefits of MIM models.
Read more7/23/2024

0
MIMIR: Masked Image Modeling for Mutual Information-based Adversarial Robustness
Xiaoyun Xu, Shujian Yu, Zhuoran Liu, Stjepan Picek
Vision Transformers (ViTs) achieve excellent performance in various tasks, but they are also vulnerable to adversarial attacks. Building robust ViTs is highly dependent on dedicated Adversarial Training (AT) strategies. However, current ViTs' adversarial training only employs well-established training approaches from convolutional neural network (CNN) training, where pre-training provides the basis for AT fine-tuning with the additional help of tailored data augmentations. In this paper, we take a closer look at the adversarial robustness of ViTs by providing a novel theoretical Mutual Information (MI) analysis in its autoencoder-based self-supervised pre-training. Specifically, we show that MI between the adversarial example and its latent representation in ViT-based autoencoders should be constrained by utilizing the MI bounds. Based on this finding, we propose a masked autoencoder-based pre-training method, MIMIR, that employs an MI penalty to facilitate the adversarial training of ViTs. Extensive experiments show that MIMIR outperforms state-of-the-art adversarially trained ViTs on benchmark datasets with higher natural and robust accuracy, indicating that ViTs can substantially benefit from exploiting MI. In addition, we consider two adaptive attacks by assuming that the adversary is aware of the MIMIR design, which further verifies the provided robustness.
Read more8/19/2024