MIMIC: Masked Image Modeling with Image Correspondences
2306.15128
0
0

Abstract
Dense pixel-specific representation learning at scale has been bottlenecked due to the unavailability of large-scale multi-view datasets. Current methods for building effective pretraining datasets heavily rely on annotated 3D meshes, point clouds, and camera parameters from simulated environments, preventing them from building datasets from real-world data sources where such metadata is lacking. We propose a pretraining dataset-curation approach that does not require any additional annotations. Our method allows us to generate multi-view datasets from both real-world videos and simulated environments at scale. Specifically, we experiment with two scales: MIMIC-1M with 1.3M and MIMIC-3M with 3.1M multi-view image pairs. We train multiple models with different masked image modeling objectives to showcase the following findings: Representations trained on our automatically generated MIMIC-3M outperform those learned from expensive crowdsourced datasets (ImageNet-1K) and those learned from synthetic environments (MULTIVIEW-HABITAT) on two dense geometric tasks: depth estimation on NYUv2 (1.7%), and surface normals estimation on Taskonomy (2.05%). For dense tasks which also require object understanding, we outperform MULTIVIEW-HABITAT, on semantic segmentation on ADE20K (3.89%), pose estimation on MSCOCO (9.4%), and reduce the gap with models pre-trained on the object-centric expensive ImageNet-1K. We outperform even when the representations are frozen, and when downstream training data is limited to few-shot. Larger dataset (MIMIC-3M) significantly improves performance, which is promising since our curation method can arbitrarily scale to produce even larger datasets. MIMIC code, dataset, and pretrained models are open-sourced at https://github.com/RAIVNLab/MIMIC.
Create account to get full access
Overview
- The paper proposes a new masked image modeling approach called MIMIC (Masked Image Modeling with Image Correspondences)
- MIMIC leverages image correspondences, such as image pairs from the same scene, to improve the performance of masked image modeling
- The authors demonstrate that MIMIC outperforms existing state-of-the-art masked image modeling approaches on various benchmarks
Plain English Explanation
The researchers have developed a new way to train AI models to understand and generate images, called MIMIC. Traditional approaches to this task, known as masked image modeling, involve hiding parts of an image and asking the model to predict what's missing. MIMIC takes this a step further by also using pairs of related images, like photos of the same scene from slightly different angles.
By incorporating this additional "correspondence" information, MIMIC is able to learn more effectively about the visual world. It can better understand how different parts of an image fit together and relate to each other. The researchers show that MIMIC outperforms other state-of-the-art masked image modeling techniques on a variety of benchmarks, meaning it is better at tasks like filling in missing parts of images.
This is an important advance because masked image modeling is a fundamental approach for training AI systems to work with visual data, with applications in areas like computer vision, image generation, and image editing. By making these models more powerful and data-efficient, MIMIC could enable AI to better understand and interact with the visual world around us.
Technical Explanation
The key innovation in MIMIC is the use of image correspondences to augment the standard masked image modeling objective. In addition to predicting the missing pixels in a masked image, the model is also tasked with aligning the predicted image with a corresponding image that depicts the same scene from a different viewpoint.
This correspondence-based objective encourages the model to learn a more holistic and consistent representation of the image, as it must not only predict the missing pixels accurately, but also ensure that the predicted image aligns with the related image. The authors demonstrate that this multi-task learning approach, combining masked image modeling with correspondence prediction, leads to significant performance gains compared to previous masked image modeling approaches.
The MIMIC architecture builds upon the Morphing Tokens framework, which uses a transformer-based model to progressively refine the prediction of the masked image. MIMIC extends this by adding a correspondence prediction module that aligns the predicted image with the corresponding image.
The authors evaluate MIMIC on a range of downstream tasks, including image classification, object detection, and semantic segmentation. They show that MIMIC outperforms CtxMIM, a state-of-the-art masked image modeling approach, by a significant margin, demonstrating the value of incorporating image correspondences into the training process.
Critical Analysis
The MIMIC paper presents a compelling approach to improving masked image modeling by leveraging image correspondences. The authors provide a thorough evaluation, demonstrating the effectiveness of their method across a variety of benchmarks.
One potential limitation of the MIMIC approach is the requirement for paired images that depict the same scene. In some real-world scenarios, such corresponding image pairs may not be readily available. The authors acknowledge this and suggest that future work could explore ways to generate or simulate such correspondences from single images.
Additionally, the paper does not extensively explore the interpretability of the learned representations or the model's ability to generalize to novel image distributions. Further research could investigate these aspects to gain a deeper understanding of the model's inner workings and limitations.
Overall, MIMIC represents a significant contribution to the field of masked image modeling, providing a novel and effective way to leverage additional supervisory signals for improved performance. As AI systems continue to play a more prominent role in visual understanding and generation, advancements like MIMIC will be crucial in advancing the capabilities of these models.
Conclusion
The MIMIC paper presents a novel masked image modeling approach that incorporates image correspondences to improve the performance of these self-supervised learning systems. By aligning the predicted image with a related image of the same scene, MIMIC is able to learn more robust and holistic representations of visual data.
The authors demonstrate the effectiveness of MIMIC across a range of benchmarks, showcasing its potential to enhance various computer vision tasks. As masked image modeling continues to be a foundational technique in self-supervised learning for visual AI, the MIMIC approach provides a promising direction for further advancing the state-of-the-art in this field.
Overall, the MIMIC paper makes a significant contribution to the ongoing efforts to develop more powerful and data-efficient AI systems for understanding and interacting with the visual world around us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Scaling Efficient Masked Autoencoder Learning on Large Remote Sensing Dataset
Fengxiang Wang, Hongzhen Wang, Di Wang, Zonghao Guo, Zhenyu Zhong, Long Lan, Jing Zhang, Zhiyuan Liu, Maosong Sun
0
0
Masked Image Modeling (MIM) has emerged as a pivotal approach for developing foundational visual models in the field of remote sensing (RS). However, current RS datasets are limited in volume and diversity, which significantly constrains the capacity of MIM methods to learn generalizable representations. In this study, we introduce textbf{RS-4M}, a large-scale dataset designed to enable highly efficient MIM training on RS images. RS-4M comprises 4 million optical images encompassing abundant and fine-grained RS visual tasks, including object-level detection and pixel-level segmentation. Compared to natural images, RS images often contain massive redundant background pixels, which limits the training efficiency of the conventional MIM models. To address this, we propose an efficient MIM method, termed textbf{SelectiveMAE}, which dynamically encodes and reconstructs a subset of patch tokens selected based on their semantic richness. SelectiveMAE roots in a progressive semantic token selection module, which evolves from reconstructing semantically analogical tokens to encoding complementary semantic dependencies. This approach transforms conventional MIM training into a progressive feature learning process, enabling SelectiveMAE to efficiently learn robust representations of RS images. Extensive experiments show that SelectiveMAE significantly boosts training efficiency by 2.2-2.7 times and enhances the classification, detection, and segmentation performance of the baseline MIM model.The dataset, source code, and trained models will be released.
6/19/2024

SemanticMIM: Marring Masked Image Modeling with Semantics Compression for General Visual Representation
Yike Yuan, Huanzhang Dou, Fengjun Guo, Xi Li
0
0
This paper represents a neat yet effective framework, named SemanticMIM, to integrate the advantages of masked image modeling (MIM) and contrastive learning (CL) for general visual representation. We conduct a thorough comparative analysis between CL and MIM, revealing that their complementary advantages fundamentally stem from two distinct phases, i.e., compression and reconstruction. Specifically, SemanticMIM leverages a proxy architecture that customizes interaction between image and mask tokens, bridging these two phases to achieve general visual representation with the property of abundant semantic and positional awareness. Through extensive qualitative and quantitative evaluations, we demonstrate that SemanticMIM effectively amalgamates the benefits of CL and MIM, leading to significant enhancement of performance and feature linear separability. SemanticMIM also offers notable interpretability through attention response visualization. Codes are available at https://github.com/yyk-wew/SemanticMIM.
6/18/2024
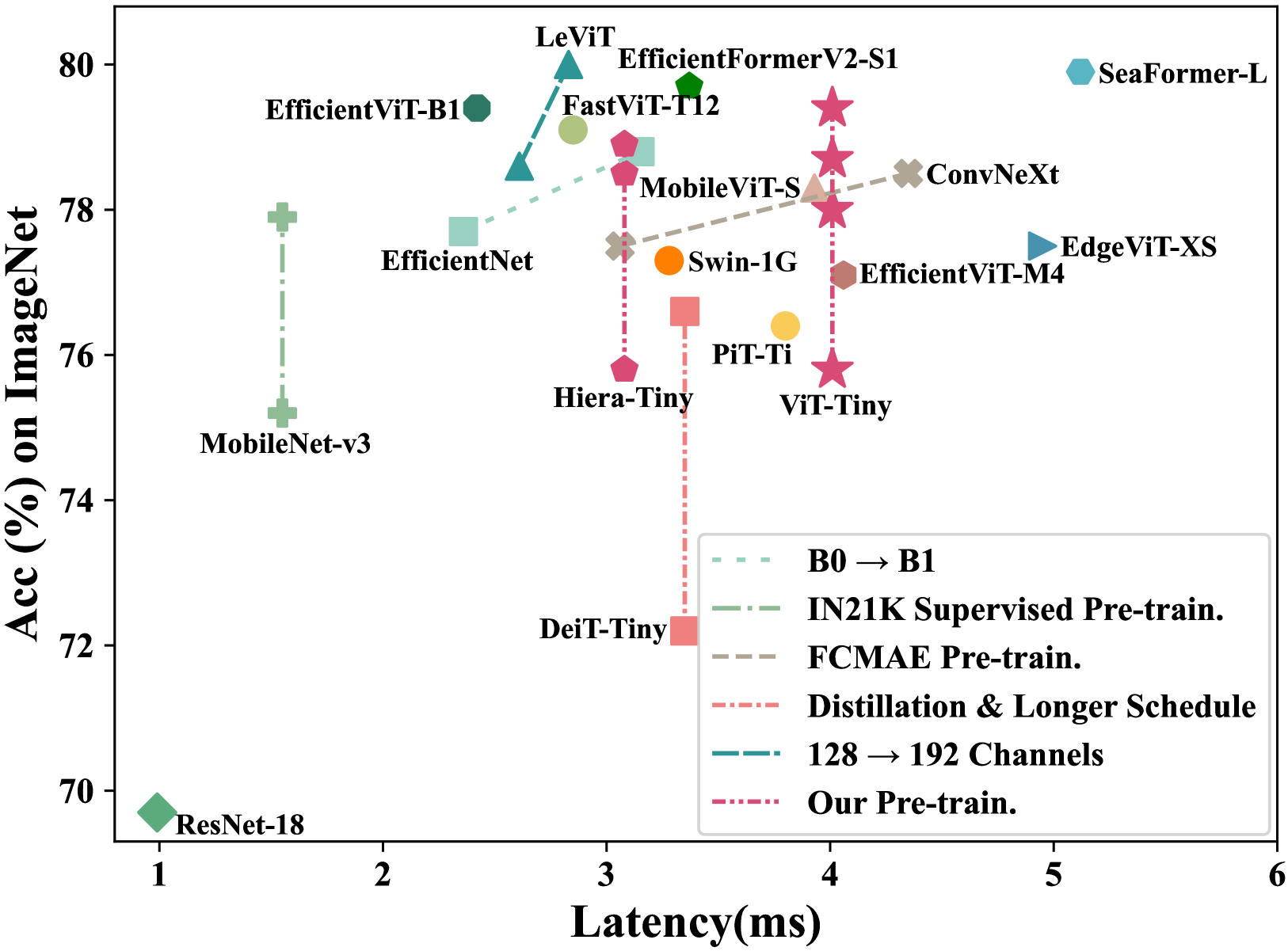
Observation, Analysis, and Solution: Exploring Strong Lightweight Vision Transformers via Masked Image Modeling Pre-Training
Jin Gao, Shubo Lin, Shaoru Wang, Yutong Kou, Zeming Li, Liang Li, Congxuan Zhang, Xiaoqin Zhang, Yizheng Wang, Weiming Hu
0
0
Masked image modeling (MIM) pre-training for large-scale vision transformers (ViTs) has enabled promising downstream performance on top of the learned self-supervised ViT features. In this paper, we question if the textit{extremely simple} lightweight ViTs' fine-tuning performance can also benefit from this pre-training paradigm, which is considerably less studied yet in contrast to the well-established lightweight architecture design methodology. We use an observation-analysis-solution flow for our study. We first systematically observe different behaviors among the evaluated pre-training methods with respect to the downstream fine-tuning data scales. Furthermore, we analyze the layer representation similarities and attention maps across the obtained models, which clearly show the inferior learning of MIM pre-training on higher layers, leading to unsatisfactory transfer performance on data-insufficient downstream tasks. This finding is naturally a guide to designing our distillation strategies during pre-training to solve the above deterioration problem. Extensive experiments have demonstrated the effectiveness of our approach. Our pre-training with distillation on pure lightweight ViTs with vanilla/hierarchical design ($5.7M$/$6.5M$) can achieve $79.4%$/$78.9%$ top-1 accuracy on ImageNet-1K. It also enables SOTA performance on the ADE20K segmentation task ($42.8%$ mIoU) and LaSOT tracking task ($66.1%$ AUC) in the lightweight regime. The latter even surpasses all the current SOTA lightweight CPU-realtime trackers.
5/28/2024
🖼️
Pre-training with Random Orthogonal Projection Image Modeling
Maryam Haghighat, Peyman Moghadam, Shaheer Mohamed, Piotr Koniusz
0
0
Masked Image Modeling (MIM) is a powerful self-supervised strategy for visual pre-training without the use of labels. MIM applies random crops to input images, processes them with an encoder, and then recovers the masked inputs with a decoder, which encourages the network to capture and learn structural information about objects and scenes. The intermediate feature representations obtained from MIM are suitable for fine-tuning on downstream tasks. In this paper, we propose an Image Modeling framework based on random orthogonal projection instead of binary masking as in MIM. Our proposed Random Orthogonal Projection Image Modeling (ROPIM) reduces spatially-wise token information under guaranteed bound on the noise variance and can be considered as masking entire spatial image area under locally varying masking degrees. Since ROPIM uses a random subspace for the projection that realizes the masking step, the readily available complement of the subspace can be used during unmasking to promote recovery of removed information. In this paper, we show that using random orthogonal projection leads to superior performance compared to crop-based masking. We demonstrate state-of-the-art results on several popular benchmarks.
4/23/2024