Affirmative safety: An approach to risk management for high-risk AI

0
🤖
Sign in to get full access
Overview
- Prominent AI experts have suggested that companies developing high-risk AI systems should be required to demonstrate the safety of their systems before deployment.
- This paper aims to expand on this idea and explore the implications for risk management.
- The authors propose that entities developing or deploying high-risk AI systems should be required to present evidence of "affirmative safety" - a proactive case that their activities keep risks below acceptable thresholds.
Plain English Explanation
The paper discusses the idea that companies developing powerful AI systems should have to prove these systems are safe before being allowed to create or use them. The authors want to explore what this would look like in practice. They suggest that companies should have to provide evidence that their AI systems and practices keep risks at an acceptable level. This is called an "affirmative safety case."
To illustrate what an affirmative safety case might include, the paper looks at different types of technical evidence and operational evidence that companies could provide. Technical evidence could show things like how the AI system behaves, what's going on inside it, and how it was developed. Operational evidence could demonstrate the company's security practices, safety culture, and emergency response plans.
The goal is to contribute to ongoing discussions about the security risks of advanced AI and explore regulatory approaches to address these risks, such as the NIST AI Risk Management Framework.
Technical Explanation
The paper begins by highlighting the global security risks from AI that have been acknowledged by AI experts and world governments. It then briefly describes principles of risk management from other high-risk fields, such as nuclear safety.
The core proposal is a risk management approach for advanced AI in which model developers must provide evidence that their activities keep certain risks below regulator-set thresholds. This "affirmative safety case" would include both technical and operational evidence.
On the technical side, the paper discusses three types of evidence:
- Behavioral evidence - data on the outputs and behaviors of the AI system
- Cognitive evidence - insights into the internal workings and decision-making processes of the AI system
- Developmental evidence - information about the AI system's training process and how it was developed
On the operational side, the paper suggests examples of organizational practices that could contribute to an affirmative safety case, such as information security practices, a strong safety culture, and robust emergency response capacity.
Finally, the paper compares this approach to the NIST AI Risk Management Framework.
Critical Analysis
The paper provides a thoughtful and comprehensive framework for how companies could demonstrate the safety of their high-risk AI systems before deployment. The authors acknowledge that this is a complex challenge, but outline concrete technical and operational evidence that could be part of an affirmative safety case.
One potential limitation is that the paper does not delve into the practical challenges of implementing such a framework, such as how to define acceptable risk thresholds or how to ensure the validity and transparency of the evidence provided by companies. There may also be questions about how this approach would interface with existing AI governance and regulatory structures.
Additionally, the paper does not address potential tensions between the desire for rigorous safety validation and the pace of AI innovation and development. Striking the right balance will be crucial.
Overall, the authors make a compelling case for the need to proactively manage the risks of advanced AI systems, and their proposed framework represents a valuable contribution to this important discussion.
Conclusion
This paper puts forth a novel approach for ensuring the safety of high-risk AI systems before they are developed or deployed. By requiring companies to present an "affirmative safety case" that demonstrates their activities keep risks below acceptable thresholds, the authors aim to address the global security threats posed by advanced AI.
The technical and operational evidence outlined in the paper provides a useful roadmap for how such safety cases could be constructed. While challenges around implementation and balancing safety with innovation remain, the authors' framework represents an important step forward in managing the extreme risks of AI amid rapid progress in the field.
Overall, this research contributes to the vital ongoing discussions around AI risk management and strategies for ensuring the safe development and deployment of powerful AI systems that will have significant implications for global security.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
0
Affirmative safety: An approach to risk management for high-risk AI
Akash R. Wasil, Joshua Clymer, David Krueger, Emily Dardaman, Simeon Campos, Evan R. Murphy
Prominent AI experts have suggested that companies developing high-risk AI systems should be required to show that such systems are safe before they can be developed or deployed. The goal of this paper is to expand on this idea and explore its implications for risk management. We argue that entities developing or deploying high-risk AI systems should be required to present evidence of affirmative safety: a proactive case that their activities keep risks below acceptable thresholds. We begin the paper by highlighting global security risks from AI that have been acknowledged by AI experts and world governments. Next, we briefly describe principles of risk management from other high-risk fields (e.g., nuclear safety). Then, we propose a risk management approach for advanced AI in which model developers must provide evidence that their activities keep certain risks below regulator-set thresholds. As a first step toward understanding what affirmative safety cases should include, we illustrate how certain kinds of technical evidence and operational evidence can support an affirmative safety case. In the technical section, we discuss behavioral evidence (evidence about model outputs), cognitive evidence (evidence about model internals), and developmental evidence (evidence about the training process). In the operational section, we offer examples of organizational practices that could contribute to affirmative safety cases: information security practices, safety culture, and emergency response capacity. Finally, we briefly compare our approach to the NIST AI Risk Management Framework. Overall, we hope our work contributes to ongoing discussions about national and global security risks posed by AI and regulatory approaches to address these risks.
Read more6/26/2024
2
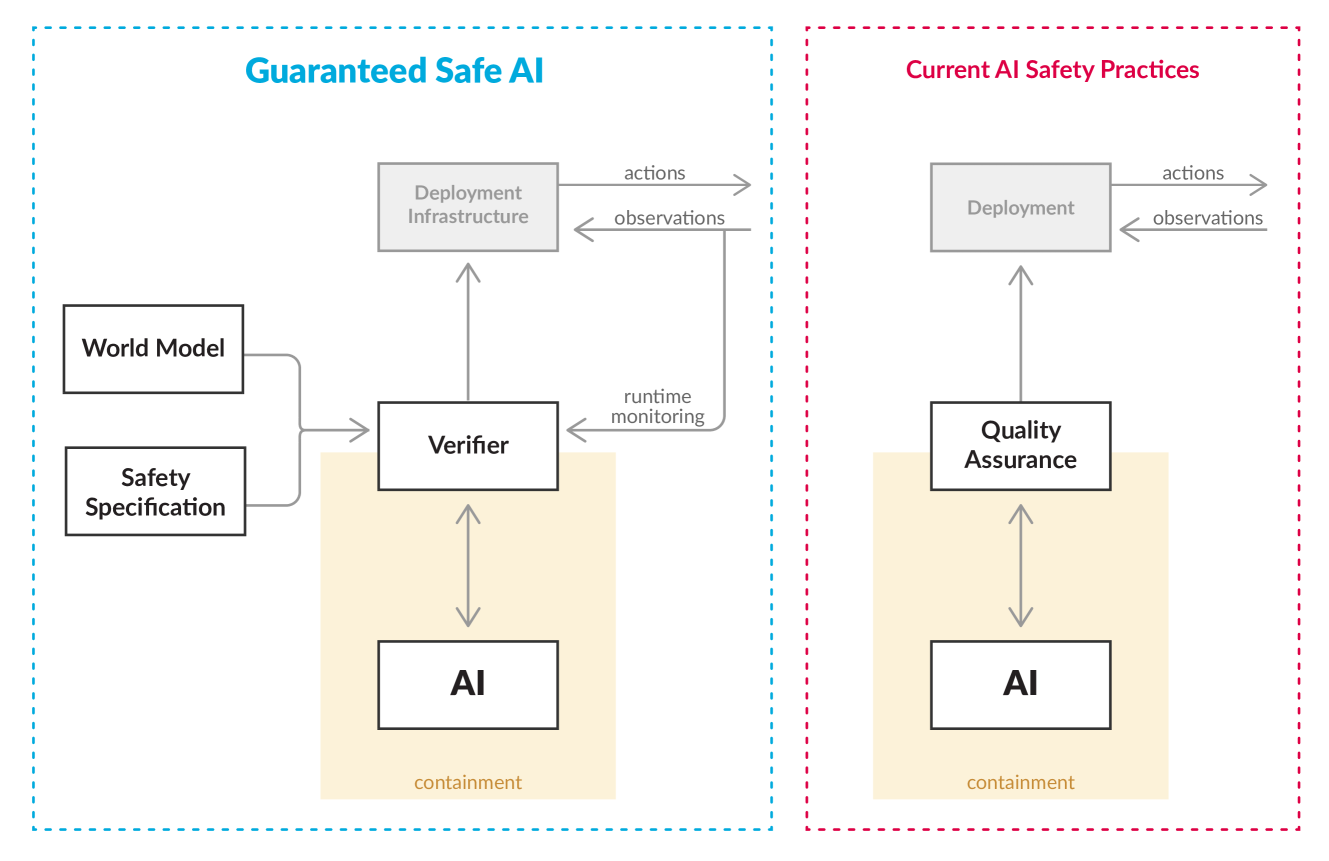
Towards Guaranteed Safe AI: A Framework for Ensuring Robust and Reliable AI Systems
David davidad Dalrymple, Joar Skalse, Yoshua Bengio, Stuart Russell, Max Tegmark, Sanjit Seshia, Steve Omohundro, Christian Szegedy, Ben Goldhaber, Nora Ammann, Alessandro Abate, Joe Halpern, Clark Barrett, Ding Zhao, Tan Zhi-Xuan, Jeannette Wing, Joshua Tenenbaum
Ensuring that AI systems reliably and robustly avoid harmful or dangerous behaviours is a crucial challenge, especially for AI systems with a high degree of autonomy and general intelligence, or systems used in safety-critical contexts. In this paper, we will introduce and define a family of approaches to AI safety, which we will refer to as guaranteed safe (GS) AI. The core feature of these approaches is that they aim to produce AI systems which are equipped with high-assurance quantitative safety guarantees. This is achieved by the interplay of three core components: a world model (which provides a mathematical description of how the AI system affects the outside world), a safety specification (which is a mathematical description of what effects are acceptable), and a verifier (which provides an auditable proof certificate that the AI satisfies the safety specification relative to the world model). We outline a number of approaches for creating each of these three core components, describe the main technical challenges, and suggest a number of potential solutions to them. We also argue for the necessity of this approach to AI safety, and for the inadequacy of the main alternative approaches.
Read more7/9/2024
🤖
0
Mapping Technical Safety Research at AI Companies: A literature review and incentives analysis
Oscar Delaney, Oliver Guest, Zoe Williams
As AI systems become more advanced, concerns about large-scale risks from misuse or accidents have grown. This report analyzes the technical research into safe AI development being conducted by three leading AI companies: Anthropic, Google DeepMind, and OpenAI. We define safe AI development as developing AI systems that are unlikely to pose large-scale misuse or accident risks. This encompasses a range of technical approaches aimed at ensuring AI systems behave as intended and do not cause unintended harm, even as they are made more capable and autonomous. We analyzed all papers published by the three companies from January 2022 to July 2024 that were relevant to safe AI development, and categorized the 80 included papers into nine safety approaches. Additionally, we noted two categories representing nascent approaches explored by academia and civil society, but not currently represented in any research papers by these leading AI companies. Our analysis reveals where corporate attention is concentrated and where potential gaps lie. Some AI research may stay unpublished for good reasons, such as to not inform adversaries about the details of security techniques they would need to overcome to misuse AI systems. Therefore, we also considered the incentives that AI companies have to research each approach, regardless of how much work they have published on the topic. We identified three categories where there are currently no or few papers and where we do not expect AI companies to become much more incentivized to pursue this research in the future. These are model organisms of misalignment, multi-agent safety, and safety by design. Our findings provide an indication that these approaches may be slow to progress without funding or efforts from government, civil society, philanthropists, or academia.
Read more9/26/2024
🤖
0
Holistic Safety and Responsibility Evaluations of Advanced AI Models
Laura Weidinger, Joslyn Barnhart, Jenny Brennan, Christina Butterfield, Susie Young, Will Hawkins, Lisa Anne Hendricks, Ramona Comanescu, Oscar Chang, Mikel Rodriguez, Jennifer Beroshi, Dawn Bloxwich, Lev Proleev, Jilin Chen, Sebastian Farquhar, Lewis Ho, Iason Gabriel, Allan Dafoe, William Isaac
Safety and responsibility evaluations of advanced AI models are a critical but developing field of research and practice. In the development of Google DeepMind's advanced AI models, we innovated on and applied a broad set of approaches to safety evaluation. In this report, we summarise and share elements of our evolving approach as well as lessons learned for a broad audience. Key lessons learned include: First, theoretical underpinnings and frameworks are invaluable to organise the breadth of risk domains, modalities, forms, metrics, and goals. Second, theory and practice of safety evaluation development each benefit from collaboration to clarify goals, methods and challenges, and facilitate the transfer of insights between different stakeholders and disciplines. Third, similar key methods, lessons, and institutions apply across the range of concerns in responsibility and safety - including established and emerging harms. For this reason it is important that a wide range of actors working on safety evaluation and safety research communities work together to develop, refine and implement novel evaluation approaches and best practices, rather than operating in silos. The report concludes with outlining the clear need to rapidly advance the science of evaluations, to integrate new evaluations into the development and governance of AI, to establish scientifically-grounded norms and standards, and to promote a robust evaluation ecosystem.
Read more4/23/2024