AGILE: A Novel Framework of LLM Agents
2405.14751
0
0
🌿
Abstract
We introduce a novel framework of LLM agents named AGILE (AGent that Interacts and Learns from Environments) designed to perform complex conversational tasks with users, leveraging LLMs, memory, tools, and interactions with experts. The agent's abilities include not only conversation but also reflection, utilization of tools, and consultation with experts. We formulate the construction of such an LLM agent as a reinforcement learning problem, in which the LLM serves as the policy model. We fine-tune the LLM using labeled data of actions and the PPO algorithm. We focus on question answering and release a dataset for agents called ProductQA, comprising challenging questions in online shopping. Our extensive experiments on ProductQA and MedMCQA show that AGILE agents based on 13B and 7B LLMs trained with PPO can outperform GPT-4 agents. Our ablation study highlights the indispensability of memory, tools, consultation, reflection, and reinforcement learning in achieving the agent's strong performance.
Create account to get full access
Overview
- The researchers introduce a novel framework called AGILE (AGent that Interacts and Learns from Environments) for large language model (LLM) agents designed to perform complex conversational tasks.
- The AGILE agents leverage LLMs, memory, tools, and interactions with experts to engage in not only conversation, but also reflection, tool utilization, and expert consultation.
- The researchers formulate the construction of AGILE agents as a reinforcement learning problem, using the LLM as the policy model.
- The agents are fine-tuned on labeled data of actions using the Proximal Policy Optimization (PPO) algorithm.
- The researchers focus on question answering and release a dataset called ProductQA, which contains challenging questions in online shopping.
- Experiments on ProductQA and MedMCQA show that AGILE agents based on 13B and 7B LLMs trained with PPO can outperform GPT-4 agents.
- An ablation study highlights the importance of memory, tools, consultation, reflection, and reinforcement learning in achieving the agents' strong performance.
Plain English Explanation
The researchers have developed a new type of AI agent, called AGILE, that can engage in complex conversations and tasks. AGILE agents use large language models (LLMs), which are AI systems trained on vast amounts of text data to understand and generate human-like language. These LLM-based agents are discussed in more detail in this overview of large language model-based game agents.
What makes AGILE agents unique is their ability to not only converse, but also reflect on their own actions, use various tools, and even consult with experts to help them complete tasks. This aligns with the growing interest in developing more generalizable AI agents that can operate in diverse environments, as discussed in this paper on text-based educational environments.
The researchers treat the process of building these AGILE agents as a reinforcement learning problem. This means the agents are trained using a reward-based system, where they learn to take actions that lead to the best outcomes. The use of reinforcement learning with LLMs in multi-agent settings is an active area of research, as explored in this survey.
To test the AGILE agents, the researchers created a dataset called ProductQA, which contains challenging questions about online shopping. They found that AGILE agents trained on this dataset and using PPO (a reinforcement learning algorithm) were able to outperform the powerful GPT-4 language model. The idea of using LLMs as "policy teachers" to train other agents is discussed in this paper.
The key to the AGILE agents' success seems to be their ability to remember past interactions, use tools, consult experts, and reflect on their own actions - capabilities that are often lacking in more traditional language models. This survey provides an overview of the various ways LLM-based multi-agent systems are being developed.
Technical Explanation
The researchers introduce the AGILE (AGent that Interacts and Learns from Environments) framework, which is designed to enable large language model (LLM) agents to perform complex conversational tasks. The AGILE agents leverage LLMs, memory, tools, and interactions with experts to engage in not only conversation, but also reflection, tool utilization, and expert consultation.
The researchers formulate the construction of AGILE agents as a reinforcement learning problem, where the LLM serves as the policy model. The agents are fine-tuned using labeled data of actions and the Proximal Policy Optimization (PPO) algorithm.
To evaluate the AGILE agents, the researchers focus on the task of question answering and release a new dataset called ProductQA, which contains challenging questions in the domain of online shopping. They also test the agents on the MedMCQA dataset.
The experimental results show that AGILE agents based on 13B and 7B LLMs trained with PPO can outperform the powerful GPT-4 language model on both the ProductQA and MedMCQA datasets. The researchers also conduct an ablation study, which highlights the importance of memory, tools, consultation, reflection, and reinforcement learning in achieving the agents' strong performance.
Critical Analysis
The AGILE framework represents an interesting and ambitious approach to developing more capable conversational AI agents. By incorporating memory, tools, expert consultation, and reflection capabilities, the researchers are attempting to address some of the key limitations of traditional language models, which often struggle with tasks that require reasoning, planning, and interaction with external resources.
However, the paper does not provide a detailed discussion of the specific architectural choices and implementation details of the AGILE agents. This makes it challenging to fully assess the technical merits and potential limitations of the approach. It would be helpful to have more information on how the different components (e.g., memory, tools, expert consultation) are integrated and how the reinforcement learning process is designed and optimized.
Additionally, the researchers' focus on question answering, while valuable, may not fully capture the breadth of conversational abilities that users might expect from a truly advanced AI agent. It would be interesting to see how the AGILE agents perform on a wider range of conversational tasks, such as open-ended dialogue, task completion, and multi-turn interactions.
The survey of LLM-based game agents and the paper on generalizable agents in text-based educational environments provide some context for the broader challenges and opportunities in developing more capable conversational AI systems, which could help inform future iterations of the AGILE framework.
Conclusion
The AGILE framework represents an important step forward in the development of more capable conversational AI agents. By incorporating memory, tools, expert consultation, and reflection capabilities, the researchers have demonstrated that LLM-based agents can outperform powerful language models like GPT-4 on challenging question-answering tasks.
While the technical details of the AGILE agents are not fully disclosed, the overall approach and experimental results suggest that this type of multi-faceted, reinforcement learning-based agent architecture could be a fruitful direction for future research in conversational AI. As the field of LLM-based multi-agent systems continues to evolve, the AGILE framework and its underlying principles could serve as a valuable reference for others working to develop more capable and versatile AI assistants.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Survey on Large Language Model-Based Game Agents
Sihao Hu, Tiansheng Huang, Fatih Ilhan, Selim Tekin, Gaowen Liu, Ramana Kompella, Ling Liu
0
0
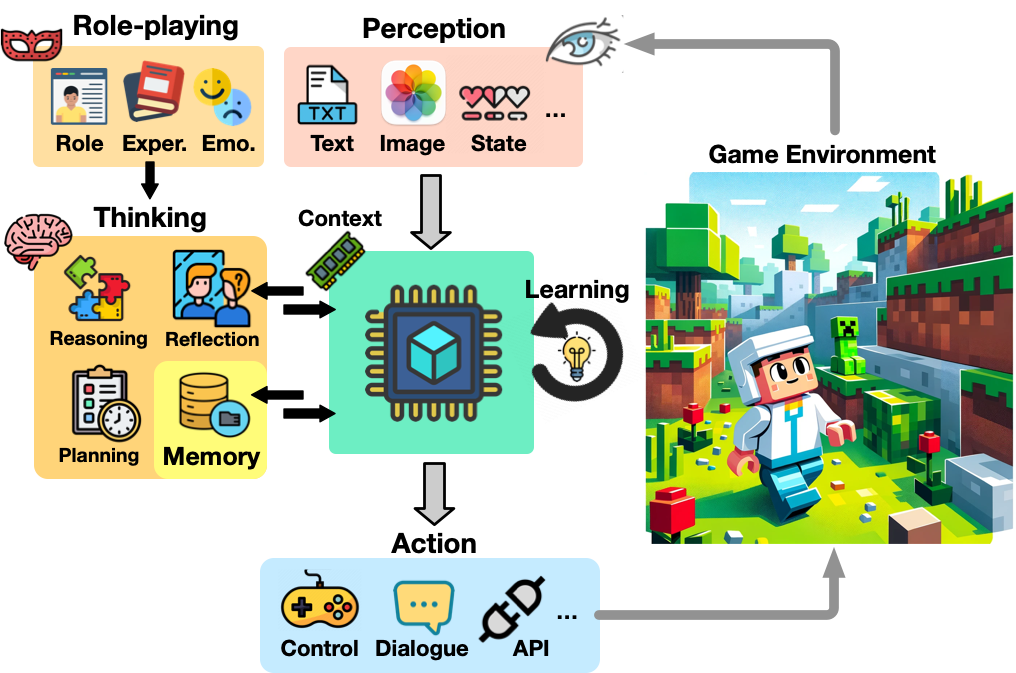
The development of game agents holds a critical role in advancing towards Artificial General Intelligence (AGI). The progress of LLMs and their multimodal counterparts (MLLMs) offers an unprecedented opportunity to evolve and empower game agents with human-like decision-making capabilities in complex computer game environments. This paper provides a comprehensive overview of LLM-based game agents from a holistic viewpoint. First, we introduce the conceptual architecture of LLM-based game agents, centered around six essential functional components: perception, memory, thinking, role-playing, action, and learning. Second, we survey existing representative LLM-based game agents documented in the literature with respect to methodologies and adaptation agility across six genres of games, including adventure, communication, competition, cooperation, simulation, and crafting & exploration games. Finally, we present an outlook of future research and development directions in this burgeoning field. A curated list of relevant papers is maintained and made accessible at: https://github.com/git-disl/awesome-LLM-game-agent-papers.
4/3/2024

Towards Generalizable Agents in Text-Based Educational Environments: A Study of Integrating RL with LLMs
Bahar Radmehr, Adish Singla, Tanja Kaser
0
0
There has been a growing interest in developing learner models to enhance learning and teaching experiences in educational environments. However, existing works have primarily focused on structured environments relying on meticulously crafted representations of tasks, thereby limiting the agent's ability to generalize skills across tasks. In this paper, we aim to enhance the generalization capabilities of agents in open-ended text-based learning environments by integrating Reinforcement Learning (RL) with Large Language Models (LLMs). We investigate three types of agents: (i) RL-based agents that utilize natural language for state and action representations to find the best interaction strategy, (ii) LLM-based agents that leverage the model's general knowledge and reasoning through prompting, and (iii) hybrid LLM-assisted RL agents that combine these two strategies to improve agents' performance and generalization. To support the development and evaluation of these agents, we introduce PharmaSimText, a novel benchmark derived from the PharmaSim virtual pharmacy environment designed for practicing diagnostic conversations. Our results show that RL-based agents excel in task completion but lack in asking quality diagnostic questions. In contrast, LLM-based agents perform better in asking diagnostic questions but fall short of completing the task. Finally, hybrid LLM-assisted RL agents enable us to overcome these limitations, highlighting the potential of combining RL and LLMs to develop high-performing agents for open-ended learning environments.
5/1/2024
Experiential Co-Learning of Software-Developing Agents
Chen Qian, Yufan Dang, Jiahao Li, Wei Liu, Zihao Xie, Yifei Wang, Weize Chen, Cheng Yang, Xin Cong, Xiaoyin Che, Zhiyuan Liu, Maosong Sun
0
0
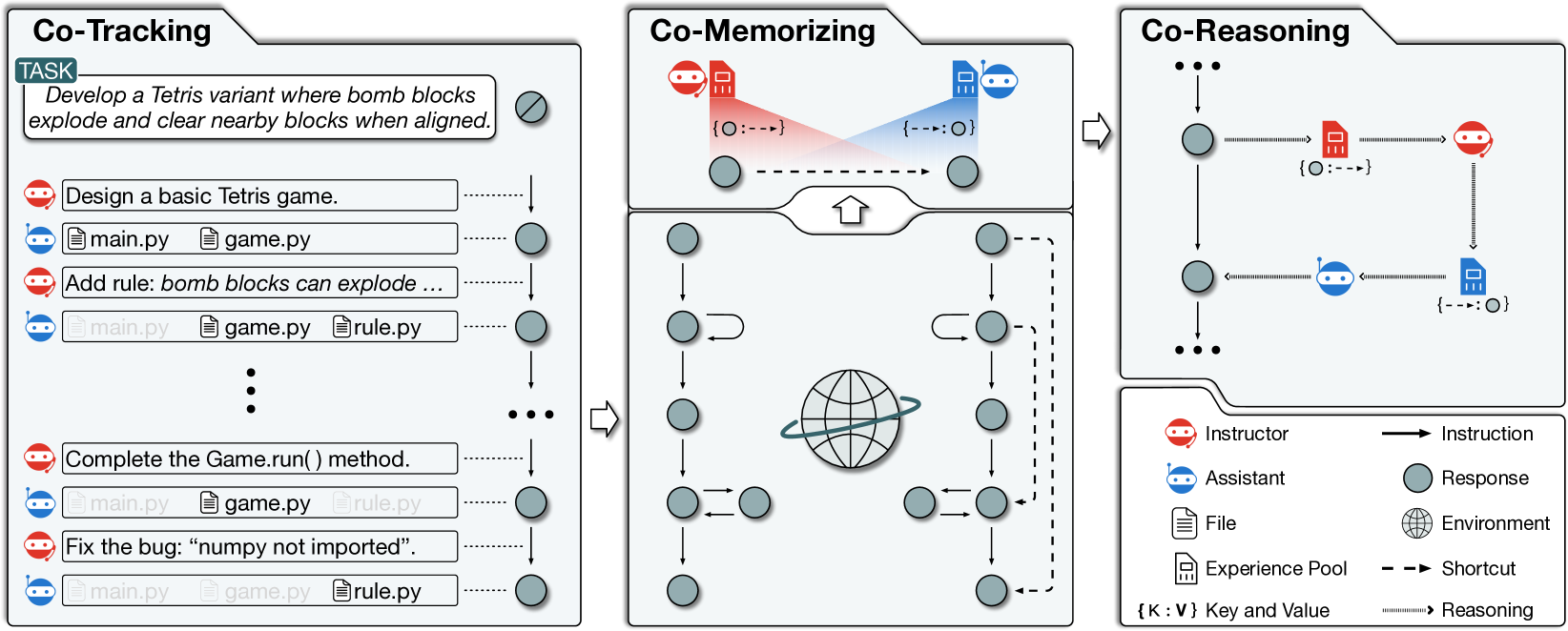
Recent advancements in large language models (LLMs) have brought significant changes to various domains, especially through LLM-driven autonomous agents. A representative scenario is in software development, where LLM agents demonstrate efficient collaboration, task division, and assurance of software quality, markedly reducing the need for manual involvement. However, these agents frequently perform a variety of tasks independently, without benefiting from past experiences, which leads to repeated mistakes and inefficient attempts in multi-step task execution. To this end, we introduce Experiential Co-Learning, a novel LLM-agent learning framework in which instructor and assistant agents gather shortcut-oriented experiences from their historical trajectories and use these past experiences for future task execution. The extensive experiments demonstrate that the framework enables agents to tackle unseen software-developing tasks more effectively. We anticipate that our insights will guide LLM agents towards enhanced autonomy and contribute to their evolutionary growth in cooperative learning. The code and data are available at https://github.com/OpenBMB/ChatDev.
6/6/2024
From Words to Actions: Unveiling the Theoretical Underpinnings of LLM-Driven Autonomous Systems
Jianliang He, Siyu Chen, Fengzhuo Zhang, Zhuoran Yang
0
0
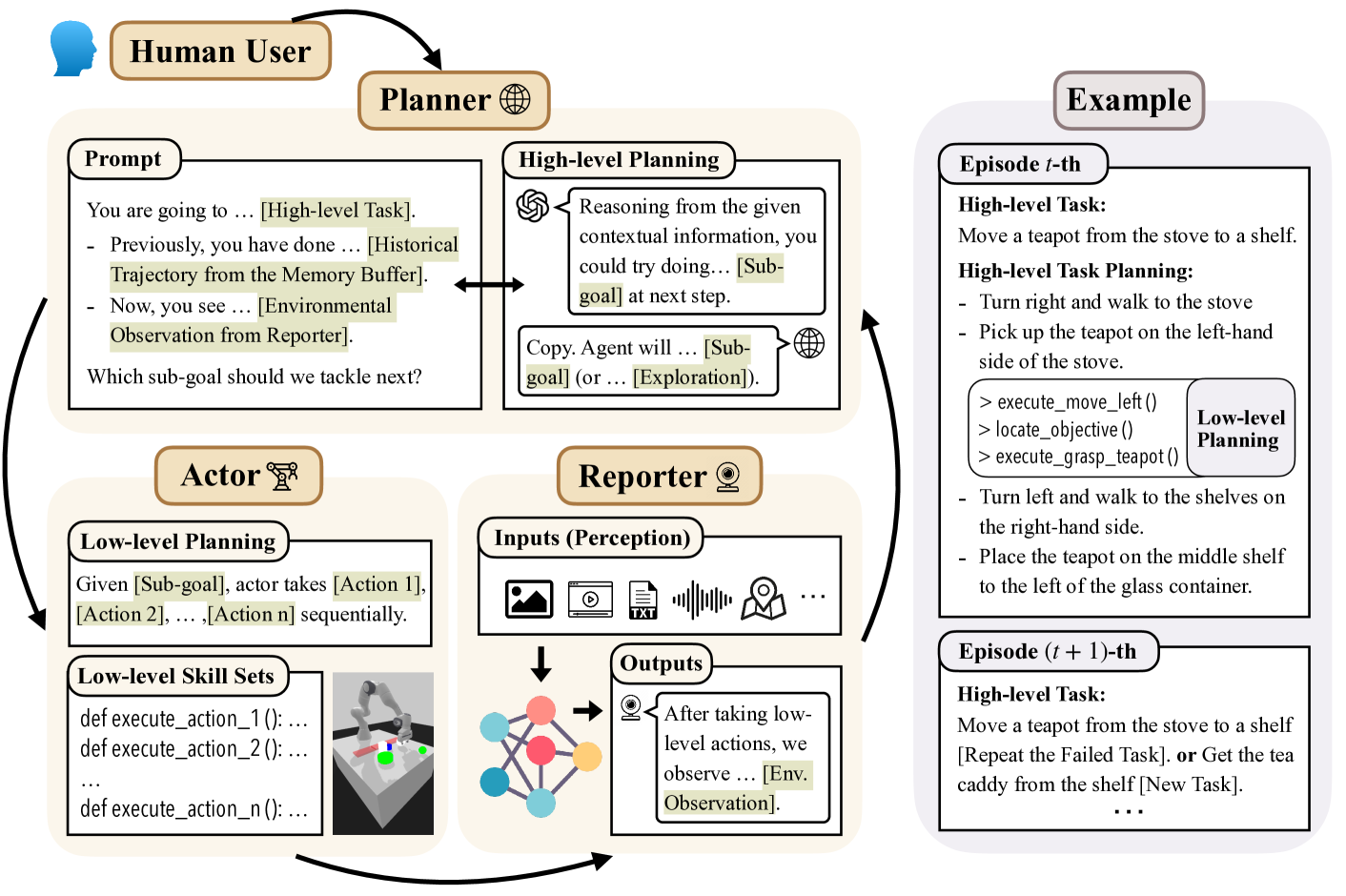
In this work, from a theoretical lens, we aim to understand why large language model (LLM) empowered agents are able to solve decision-making problems in the physical world. To this end, consider a hierarchical reinforcement learning (RL) model where the LLM Planner and the Actor perform high-level task planning and low-level execution, respectively. Under this model, the LLM Planner navigates a partially observable Markov decision process (POMDP) by iteratively generating language-based subgoals via prompting. Under proper assumptions on the pretraining data, we prove that the pretrained LLM Planner effectively performs Bayesian aggregated imitation learning (BAIL) through in-context learning. Additionally, we highlight the necessity for exploration beyond the subgoals derived from BAIL by proving that naively executing the subgoals returned by LLM leads to a linear regret. As a remedy, we introduce an $epsilon$-greedy exploration strategy to BAIL, which is proven to incur sublinear regret when the pretraining error is small. Finally, we extend our theoretical framework to include scenarios where the LLM Planner serves as a world model for inferring the transition model of the environment and to multi-agent settings, enabling coordination among multiple Actors.
5/31/2024