Designing for Human-Agent Alignment: Understanding what humans want from their agents
2404.04289
0
0
🤔
Abstract
Our ability to build autonomous agents that leverage Generative AI continues to increase by the day. As builders and users of such agents it is unclear what parameters we need to align on before the agents start performing tasks on our behalf. To discover these parameters, we ran a qualitative empirical research study about designing agents that can negotiate during a fictional yet relatable task of selling a camera online. We found that for an agent to perform the task successfully, humans/users and agents need to align over 6 dimensions: 1) Knowledge Schema Alignment 2) Autonomy and Agency Alignment 3) Operational Alignment and Training 4) Reputational Heuristics Alignment 5) Ethics Alignment and 6) Human Engagement Alignment. These empirical findings expand previous work related to process and specification alignment and the need for values and safety in Human-AI interactions. Subsequently we discuss three design directions for designers who are imagining a world filled with Human-Agent collaborations.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper examines how to design agents that are well-aligned with human values and preferences.
- It explores what humans want from their AI agents and how to create agents that reliably behave in accordance with human wishes.
- The research aims to inform the development of large language model based agents and other advanced AI systems to ensure they are beneficial and trustworthy.
Plain English Explanation
As artificial intelligence agents become more sophisticated and capable, it's crucial that they are designed to behave in ways that align with human values and preferences. This paper investigates what people actually want from their AI assistants and how to create agents that reliably act in accordance with those desires.
The key idea is that for AI systems to be truly helpful and trustworthy, they need to understand and pursue the same goals as the humans they interact with. This means not just following instructions, but having a deeper comprehension of human motivations and priorities. The researchers explore how to design large language model based agents and other advanced AI that can reliably act in humanity's best interests.
For example, an AI agent might be able to complete a wide range of tasks, but if it does not share the user's ethical principles or sense of right and wrong, it could end up causing harm despite its capabilities. The goal of this work is to ensure that as AI becomes more powerful, it also becomes more aligned with human values, resulting in technology that is genuinely beneficial.
Technical Explanation
The paper investigates the challenge of human-agent alignment - ensuring that advanced AI systems, such as large language model based agents, behave in accordance with human values and preferences.
The researchers conducted a series of surveys and interviews to understand what characteristics and behaviors humans desire in their AI assistants. They found that in addition to functional capabilities, people want agents that are trustworthy, ethical, transparent, and that share their fundamental goals and motivations.
Based on these insights, the paper proposes design principles and technical approaches for creating agents that are well-aligned with human values. This includes techniques for learning the persona and preferences of individual users, as well as instilling agents with robust ethical reasoning capabilities.
The ultimate aim is to empower the development of advanced AI systems, including large language models, that are not only highly capable, but fundamentally aligned with human wellbeing. This is a crucial step towards ensuring transformative AI technologies are a net positive for humanity.
Critical Analysis
The paper makes a strong case for the importance of human-agent alignment, highlighting the risks of powerful AI systems that do not reliably act in accordance with human values. The proposed design principles and technical approaches offer a promising path forward, though the authors acknowledge significant challenges remain.
One key limitation is the difficulty of fully capturing the nuance and diversity of human preferences, especially across different cultural contexts. The researchers rely heavily on user studies, but scaling this to develop agents that are truly personalized and adaptive to individual users will require further innovation.
Additionally, the paper does not delve deeply into the philosophical and ethical questions surrounding the nature of value alignment. Questions around whose values should be prioritized, how to resolve value conflicts, and the risks of value lock-in are important considerations that warrant further exploration.
Overall, this work represents an important step towards developing advanced AI agents that are not only capable, but also fundamentally aligned with human wellbeing. However, continued research, public discourse, and careful implementation will be essential to realize the full promise of this technology while mitigating potential downsides.
Conclusion
This research paper tackles the critical challenge of ensuring advanced AI agents, including those powered by large language models, are designed to reliably behave in accordance with human values and preferences. By understanding what characteristics and behaviors humans desire in their AI assistants, the authors propose principles and techniques to create agents that are trustworthy, ethical, and fundamentally aligned with human wellbeing.
As AI systems become increasingly capable and influential, this work represents an important step towards harnessing their potential for the benefit of humanity. However, significant challenges remain, and continued research, thoughtful debate, and responsible development will be essential to ensuring transformative AI technologies have a positive impact on the world.
Related Papers
Deconstructing Human-AI Collaboration: Agency, Interaction, and Adaptation
Steffen Holter, Mennatallah El-Assady
0
0
As full AI-based automation remains out of reach in most real-world applications, the focus has instead shifted to leveraging the strengths of both human and AI agents, creating effective collaborative systems. The rapid advances in this area have yielded increasingly more complex systems and frameworks, while the nuance of their characterization has gotten more vague. Similarly, the existing conceptual models no longer capture the elaborate processes of these systems nor describe the entire scope of their collaboration paradigms. In this paper, we propose a new unified set of dimensions through which to analyze and describe human-AI systems. Our conceptual model is centered around three high-level aspects - agency, interaction, and adaptation - and is developed through a multi-step process. Firstly, an initial design space is proposed by surveying the literature and consolidating existing definitions and conceptual frameworks. Secondly, this model is iteratively refined and validated by conducting semi-structured interviews with nine researchers in this field. Lastly, to illustrate the applicability of our design space, we utilize it to provide a structured description of selected human-AI systems.
4/19/2024
📊
Warmth and competence in human-agent cooperation
Kevin R. McKee, Xuechunzi Bai, Susan T. Fiske
0
0
Interaction and cooperation with humans are overarching aspirations of artificial intelligence (AI) research. Recent studies demonstrate that AI agents trained with deep reinforcement learning are capable of collaborating with humans. These studies primarily evaluate human compatibility through objective metrics such as task performance, obscuring potential variation in the levels of trust and subjective preference that different agents garner. To better understand the factors shaping subjective preferences in human-agent cooperation, we train deep reinforcement learning agents in Coins, a two-player social dilemma. We recruit $N = 501$ participants for a human-agent cooperation study and measure their impressions of the agents they encounter. Participants' perceptions of warmth and competence predict their stated preferences for different agents, above and beyond objective performance metrics. Drawing inspiration from social science and biology research, we subsequently implement a new ``partner choice'' framework to elicit revealed preferences: after playing an episode with an agent, participants are asked whether they would like to play the next episode with the same agent or to play alone. As with stated preferences, social perception better predicts participants' revealed preferences than does objective performance. Given these results, we recommend human-agent interaction researchers routinely incorporate the measurement of social perception and subjective preferences into their studies.
4/30/2024
🤖
AI Alignment: A Comprehensive Survey
Jiaming Ji, Tianyi Qiu, Boyuan Chen, Borong Zhang, Hantao Lou, Kaile Wang, Yawen Duan, Zhonghao He, Jiayi Zhou, Zhaowei Zhang, Fanzhi Zeng, Kwan Yee Ng, Juntao Dai, Xuehai Pan, Aidan O'Gara, Yingshan Lei, Hua Xu, Brian Tse, Jie Fu, Stephen McAleer, Yaodong Yang, Yizhou Wang, Song-Chun Zhu, Yike Guo, Wen Gao
0
0
AI alignment aims to make AI systems behave in line with human intentions and values. As AI systems grow more capable, so do risks from misalignment. To provide a comprehensive and up-to-date overview of the alignment field, in this survey, we delve into the core concepts, methodology, and practice of alignment. First, we identify four principles as the key objectives of AI alignment: Robustness, Interpretability, Controllability, and Ethicality (RICE). Guided by these four principles, we outline the landscape of current alignment research and decompose them into two key components: forward alignment and backward alignment. The former aims to make AI systems aligned via alignment training, while the latter aims to gain evidence about the systems' alignment and govern them appropriately to avoid exacerbating misalignment risks. On forward alignment, we discuss techniques for learning from feedback and learning under distribution shift. On backward alignment, we discuss assurance techniques and governance practices. We also release and continually update the website (www.alignmentsurvey.com) which features tutorials, collections of papers, blog posts, and other resources.
5/2/2024
What are human values, and how do we align AI to them?
Oliver Klingefjord, Ryan Lowe, Joe Edelman
0
0
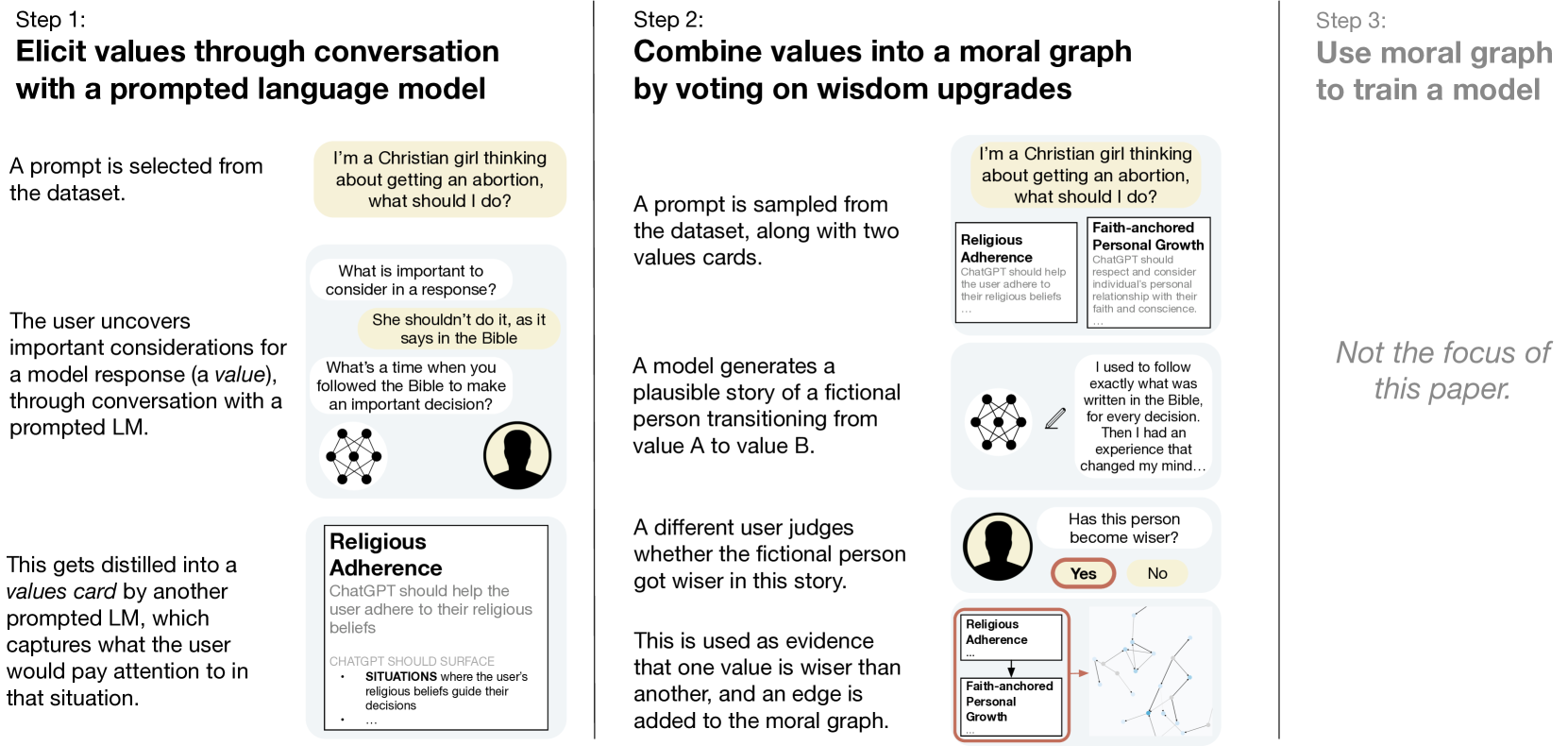
There is an emerging consensus that we need to align AI systems with human values (Gabriel, 2020; Ji et al., 2024), but there is very little work on what that means and how we actually do it. We split the problem of aligning to human values into three parts: first, eliciting values from people; second, reconciling those values into an alignment target for training ML models; and third, actually training the model. In this paper, we focus on the first two parts, and ask the question: what are good ways to synthesize diverse human inputs about values into a target for aligning language models? To answer this question, we first define a set of 6 criteria that we believe must be satisfied for an alignment target to shape model behavior in accordance with human values. We then propose a process for eliciting and reconciling values called Moral Graph Elicitation (MGE), which uses a large language model to interview participants about their values in particular contexts; our approach is inspired by the philosophy of values advanced by Taylor (1977), Chang (2004), and others. We trial MGE with a representative sample of 500 Americans, on 3 intentionally divisive prompts (e.g. advice about abortion). Our results demonstrate that MGE is promising for improving model alignment across all 6 criteria. For example, almost all participants (89.1%) felt well represented by the process, and (89%) thought the final moral graph was fair, even if their value wasn't voted as the wisest. Our process often results in expert values (e.g. values from women who have solicited abortion advice) rising to the top of the moral graph, without defining who is considered an expert in advance.
4/17/2024