An AI Architecture with the Capability to Explain Recognition Results

0
Sign in to get full access
Overview
- Presents an AI architecture with the capability to explain its recognition results
- Focuses on developing an explainable AI system that can provide clear justifications for its decisions
- Explores techniques like Support Vector Machines and Multilayer Perceptrons to build an interpretable model
Plain English Explanation
This research paper aims to create an AI system that can not only recognize patterns and make decisions, but also explain how it arrived at those conclusions. The key idea is to develop an "explainable AI" model that can provide clear, human-understandable justifications for its actions.
The researchers explore techniques like Support Vector Machines and Multilayer Perceptrons to build an interpretable model. The goal is to create an AI architecture that can not only make accurate predictions, but also explain its reasoning in a way that makes sense to people.
This type of "explainable AI" is important because it can help build trust and understanding between humans and AI systems. When an AI can explain its decision-making process, it becomes more transparent and accountable. This can be especially useful in high-stakes applications like healthcare, finance, or criminal justice, where the reasoning behind AI-powered decisions needs to be clearly understood.
Explainable AI engineering is an active area of research, as researchers explore ways to make AI models more interpretable and explainable. This paper contributes to this effort by proposing a specific architectural approach and demonstrating its potential.
Technical Explanation
The researchers propose an AI architecture that combines a recognition model (e.g., a Support Vector Machine or Multilayer Perceptron) with an explanation module. The recognition model is trained to perform a specific task, such as image classification or object detection. The explanation module then analyzes the inputs and outputs of the recognition model to generate a human-readable explanation of the model's decision-making process.
To achieve this, the researchers use a thermodynamics-inspired approach to extract salient features from the recognition model's intermediate layers. These features are then used to generate natural language explanations that describe the reasoning behind the model's predictions.
The researchers evaluate their approach on several benchmark datasets and demonstrate that the explanations generated by their system are both accurate and understandable to human users. They also show that the explanations can be used to improve the model's performance, as the process of generating explanations can help identify areas where the model is making incorrect or suboptimal decisions.
Critical Analysis
The researchers acknowledge several limitations of their work, including the fact that their approach currently only supports relatively simple recognition tasks. They also note that generating high-quality natural language explanations remains a challenging problem, and that further research is needed to improve the explanatory capabilities of their system.
One potential concern is that the reliance on thermodynamics-inspired techniques to extract salient features may not be the most appropriate or effective approach for all types of recognition models. The researchers could explore alternative feature extraction and explanation generation methods to see if they can achieve even better performance and more intuitive explanations.
Additionally, the researchers could consider integrating their approach with other explainable AI techniques to create a more comprehensive and robust explainable AI system. This could involve combining their model-specific explanations with more global, interpretable representations of the AI's decision-making process.
Conclusion
This research paper presents a promising approach to building explainable AI systems that can not only make accurate predictions, but also provide clear and understandable justifications for their decisions. By combining recognition models with an explanation module, the researchers demonstrate a way to make AI systems more transparent and accountable, which could be particularly valuable in high-stakes applications.
While the current implementation has some limitations, the overall concept of "explainable AI" is an important area of research that could help bridge the gap between AI and human understanding. As the field of explainable AI engineering continues to evolve, this work represents a valuable contribution to the ongoing efforts to make AI systems more interpretable and trustworthy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An AI Architecture with the Capability to Explain Recognition Results
Paul Whitten, Francis Wolff, Chris Papachristou
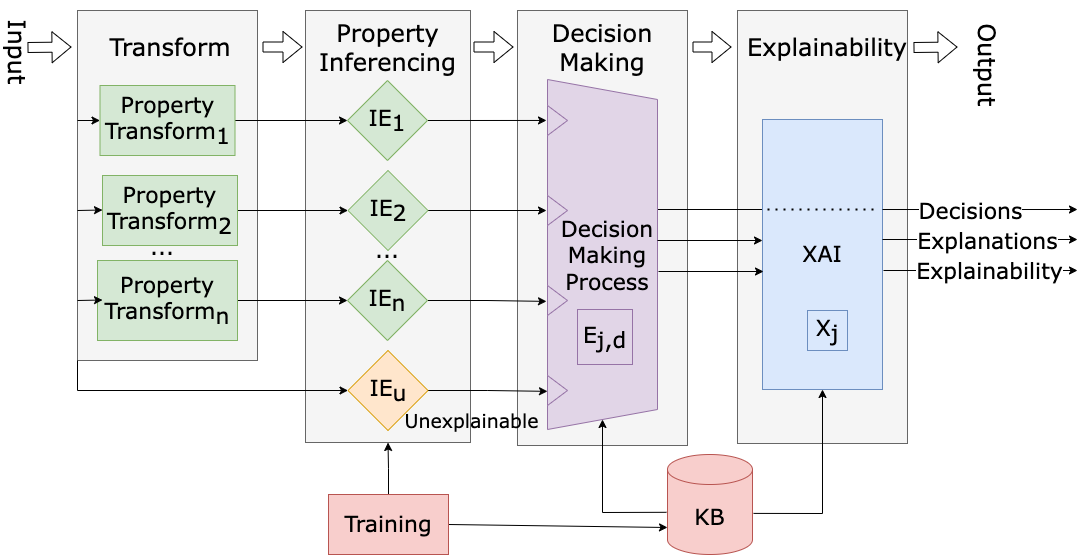
Explainability is needed to establish confidence in machine learning results. Some explainable methods take a post hoc approach to explain the weights of machine learning models, others highlight areas of the input contributing to decisions. These methods do not adequately explain decisions, in plain terms. Explainable property-based systems have been shown to provide explanations in plain terms, however, they have not performed as well as leading unexplainable machine learning methods. This research focuses on the importance of metrics to explainability and contributes two methods yielding performance gains. The first method introduces a combination of explainable and unexplainable flows, proposing a metric to characterize explainability of a decision. The second method compares classic metrics for estimating the effectiveness of neural networks in the system, posing a new metric as the leading performer. Results from the new methods and examples from handwritten datasets are presented.
Read more7/4/2024
🧪
0
Towards a Unified Framework for Evaluating Explanations
Juan D. Pinto, Luc Paquette
The challenge of creating interpretable models has been taken up by two main research communities: ML researchers primarily focused on lower-level explainability methods that suit the needs of engineers, and HCI researchers who have more heavily emphasized user-centered approaches often based on participatory design methods. This paper reviews how these communities have evaluated interpretability, identifying overlaps and semantic misalignments. We propose moving towards a unified framework of evaluation criteria and lay the groundwork for such a framework by articulating the relationships between existing criteria. We argue that explanations serve as mediators between models and stakeholders, whether for intrinsically interpretable models or opaque black-box models analyzed via post-hoc techniques. We further argue that useful explanations require both faithfulness and intelligibility. Explanation plausibility is a prerequisite for intelligibility, while stability is a prerequisite for explanation faithfulness. We illustrate these criteria, as well as specific evaluation methods, using examples from an ongoing study of an interpretable neural network for predicting a particular learner behavior.
Read more7/16/2024
❗
0
What Makes a Good Explanation?: A Harmonized View of Properties of Explanations
Zixi Chen, Varshini Subhash, Marton Havasi, Weiwei Pan, Finale Doshi-Velez
Interpretability provides a means for humans to verify aspects of machine learning (ML) models and empower human+ML teaming in situations where the task cannot be fully automated. Different contexts require explanations with different properties. For example, the kind of explanation required to determine if an early cardiac arrest warning system is ready to be integrated into a care setting is very different from the type of explanation required for a loan applicant to help determine the actions they might need to take to make their application successful. Unfortunately, there is a lack of standardization when it comes to properties of explanations: different papers may use the same term to mean different quantities, and different terms to mean the same quantity. This lack of a standardized terminology and categorization of the properties of ML explanations prevents us from both rigorously comparing interpretable machine learning methods and identifying what properties are needed in what contexts. In this work, we survey properties defined in interpretable machine learning papers, synthesize them based on what they actually measure, and describe the trade-offs between different formulations of these properties. In doing so, we enable more informed selection of task-appropriate formulations of explanation properties as well as standardization for future work in interpretable machine learning.
Read more7/15/2024

0
The future of human-centric eXplainable Artificial Intelligence (XAI) is not post-hoc explanations
Vinitra Swamy, Jibril Frej, Tanja Kaser
Explainable Artificial Intelligence (XAI) plays a crucial role in enabling human understanding and trust in deep learning systems. As models get larger, more ubiquitous, and pervasive in aspects of daily life, explainability is necessary to minimize adverse effects of model mistakes. Unfortunately, current approaches in human-centric XAI (e.g. predictive tasks in healthcare, education, or personalized ads) tend to rely on a single post-hoc explainer, whereas recent work has identified systematic disagreement between post-hoc explainers when applied to the same instances of underlying black-box models. In this paper, we therefore present a call for action to address the limitations of current state-of-the-art explainers. We propose a shift from post-hoc explainability to designing interpretable neural network architectures. We identify five needs of human-centric XAI (real-time, accurate, actionable, human-interpretable, and consistent) and propose two schemes for interpretable-by-design neural network workflows (adaptive routing with InterpretCC and temporal diagnostics with I2MD). We postulate that the future of human-centric XAI is neither in explaining black-boxes nor in reverting to traditional, interpretable models, but in neural networks that are intrinsically interpretable.
Read more5/29/2024