AI-coupled HPC Workflow Applications, Middleware and Performance

0

Sign in to get full access
Overview
- This paper explores the intersection of AI, high-performance computing (HPC), and workflow applications, discussing the challenges and opportunities in this space.
- It examines the various execution motifs (patterns) that arise when integrating AI and HPC, and the implications for middleware and performance.
- The paper also covers topics like hybrid quantum-classical scientific computing, HPC alongside user-space Kubernetes, and scaling AI sustainably.
Plain English Explanation
The paper discusses the challenges and potential solutions for combining artificial intelligence (AI) with high-performance computing (HPC) systems. HPC is used for complex, resource-intensive computations, while AI is increasingly being applied to a wide range of problems. The authors explore how these two technologies can be integrated, focusing on the different ways in which AI and HPC workflows can be combined, known as "execution motifs".
This is an important topic because as AI becomes more prevalent, there is a growing need to harness the power of HPC systems to accelerate AI-driven workloads. However, there are significant technical hurdles to overcome, such as optimizing the performance of AI models running on HPC hardware and integrating AI seamlessly into industrial workflows.
The paper explores these challenges and proposes various solutions, including new middleware and architectural approaches. By better understanding the interplay between AI and HPC, researchers and developers can create more efficient and effective systems that leverage the strengths of both technologies.
Technical Explanation
The paper identifies several key "execution motifs" that arise when integrating AI and HPC workflows. These include:
- Offloading: Using HPC resources to accelerate the compute-intensive portions of an AI model, while keeping the control logic on a separate, less powerful system.
- Co-processing: Tightly coupling AI and HPC components, where they work together in a more integrated fashion to solve a problem.
- Hybrid: Combining AI and HPC in a more complex workflow, where different stages of the process utilize the respective strengths of each technology.
The authors then discuss the implications of these execution motifs for middleware and system performance. They explore how factors like data movement, resource management, and task scheduling need to be rethought to support these new AI-HPC workflows effectively.
The paper also touches on related topics, such as the integration of HPC and user-space Kubernetes and the challenges of scaling AI in a sustainable manner. These areas are important for enabling the widespread adoption and effective use of AI-HPC systems.
Critical Analysis
The paper provides a comprehensive overview of the challenges and opportunities in the intersection of AI and HPC, but it also acknowledges several limitations and areas for further research.
One key limitation is that the execution motifs described are relatively high-level and may not capture the full complexity of real-world AI-HPC workflows. In practice, there may be more nuanced ways in which these technologies are combined, and the paper does not delve deeply into specific use cases or application domains.
Additionally, the paper does not address some of the broader societal and ethical implications of AI-HPC integration, such as the potential for increased computational power to be used for surveillance, manipulation, or other harmful purposes. This is an important consideration as AI becomes more pervasive in industry and government.
Overall, the paper provides a solid foundation for understanding the technical challenges and opportunities in this space, but further research and discussion are needed to fully address the complex issues surrounding the integration of AI and HPC.
Conclusion
This paper offers a valuable perspective on the evolving relationship between artificial intelligence and high-performance computing. By identifying the key execution motifs that arise when these technologies are combined, the authors highlight the need for new middleware, architectures, and performance optimization strategies to support AI-HPC workflows effectively.
As AI continues to become more prevalent in a wide range of applications, the ability to leverage the power of HPC systems will be crucial for unlocking the full potential of these technologies. The insights and recommendations provided in this paper can help guide researchers, developers, and system architects as they work to bridge the gap between AI and HPC, paving the way for more efficient, scalable, and capable AI-driven solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AI-coupled HPC Workflow Applications, Middleware and Performance
Wes Brewer, Ana Gainaru, Fr'ed'eric Suter, Feiyi Wang, Murali Emani, Shantenu Jha
AI integration is revolutionizing the landscape of HPC simulations, enhancing the importance, use, and performance of AI-driven HPC workflows. This paper surveys the diverse and rapidly evolving field of AI-driven HPC and provides a common conceptual basis for understanding AI-driven HPC workflows. Specifically, we use insights from different modes of coupling AI into HPC workflows to propose six execution motifs most commonly found in scientific applications. The proposed set of execution motifs is by definition incomplete and evolving. However, they allow us to analyze the primary performance challenges underpinning AI-driven HPC workflows. We close with a listing of open challenges, research issues, and suggested areas of investigation including the the need for specific benchmarks that will help evaluate and improve the execution of AI-driven HPC workflows.
Read more6/21/2024

0
Employing Artificial Intelligence to Steer Exascale Workflows with Colmena
Logan Ward, J. Gregory Pauloski, Valerie Hayot-Sasson, Yadu Babuji, Alexander Brace, Ryan Chard, Kyle Chard, Rajeev Thakur, Ian Foster
Computational workflows are a common class of application on supercomputers, yet the loosely coupled and heterogeneous nature of workflows often fails to take full advantage of their capabilities. We created Colmena to leverage the massive parallelism of a supercomputer by using Artificial Intelligence (AI) to learn from and adapt a workflow as it executes. Colmena allows scientists to define how their application should respond to events (e.g., task completion) as a series of cooperative agents. In this paper, we describe the design of Colmena, the challenges we overcame while deploying applications on exascale systems, and the science workflows we have enhanced through interweaving AI. The scaling challenges we discuss include developing steering strategies that maximize node utilization, introducing data fabrics that reduce communication overhead of data-intensive tasks, and implementing workflow tasks that cache costly operations between invocations. These innovations coupled with a variety of application patterns accessible through our agent-based steering model have enabled science advances in chemistry, biophysics, and materials science using different types of AI. Our vision is that Colmena will spur creative solutions that harness AI across many domains of scientific computing.
Read more8/27/2024

0
Towards an Integrated Performance Framework for Fire Science and Management Workflows
H. Ahmed, R. Shende, I. Perez, D. Crawl, S. Purawat, I. Altintas
Reliable performance metrics are necessary prerequisites to building large-scale end-to-end integrated workflows for collaborative scientific research, particularly within context of use-inspired decision making platforms with many concurrent users and when computing real-time and urgent results using large data. This work is a building block for the National Data Platform, which leverages multiple use-cases including the WIFIRE Data and Model Commons for wildfire behavior modeling and the EarthScope Consortium for collaborative geophysical research. This paper presents an artificial intelligence and machine learning (AI/ML) approach to performance assessment and optimization of scientific workflows. An associated early AI/ML framework spanning performance data collection, prediction and optimization is applied to wildfire science applications within the WIFIRE BurnPro3D (BP3D) platform for proactive fire management and mitigation.
Read more8/1/2024
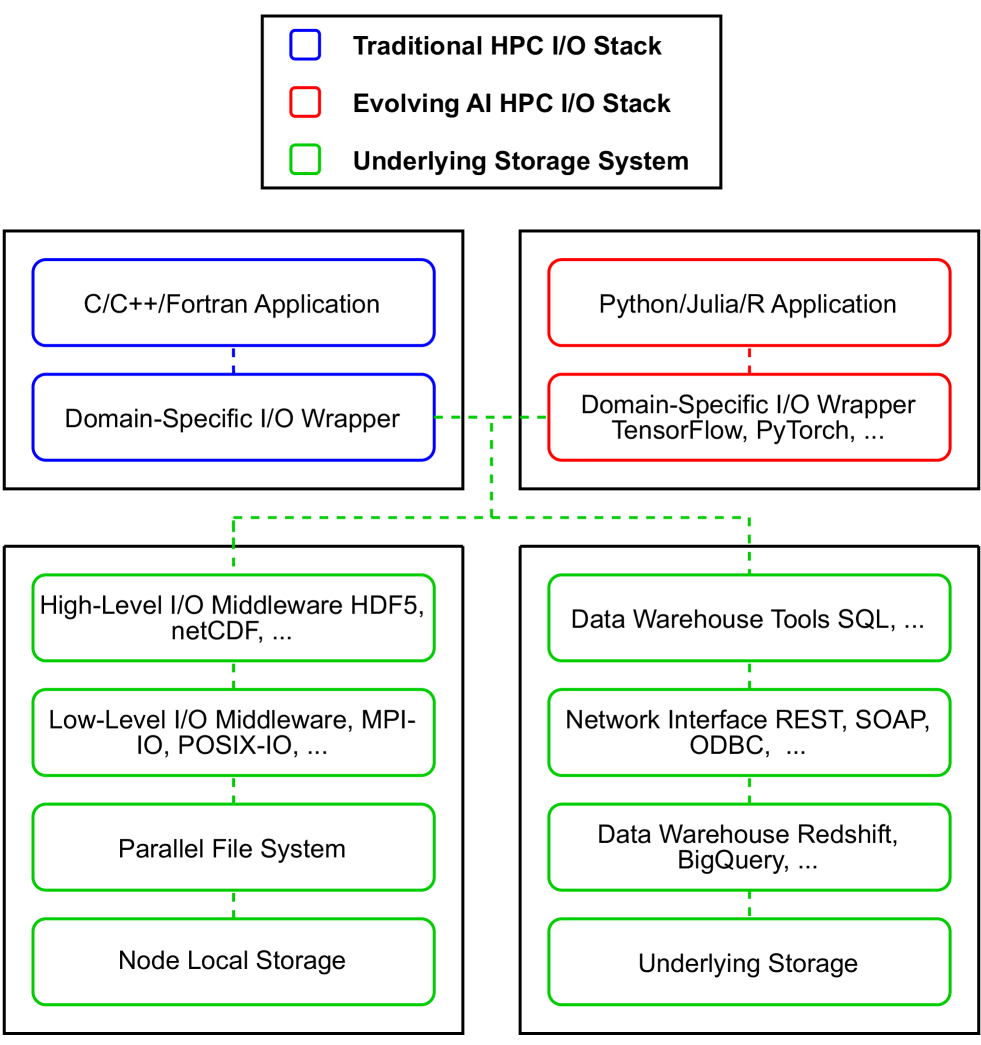
0
I/O in Machine Learning Applications on HPC Systems: A 360-degree Survey
Noah Lewis, Jean Luca Bez, Suren Byna
High-Performance Computing (HPC) systems excel in managing distributed workloads, and the growing interest in Artificial Intelligence (AI) has resulted in a surge in demand for faster methods of Machine Learning (ML) model training and inference. In the past, research on HPC I/O focused on optimizing the underlying storage system for modeling and simulation applications and checkpointing the results, causing writes to be the dominant I/O operation. These applications typically access large portions of the data written by simulations or experiments. ML workloads, in contrast, perform small I/O reads spread across a large number of random files. This shift of I/O access patterns poses several challenges to HPC storage systems. In this paper, we survey I/O in ML applications on HPC systems, and target literature within a 6-year time window from 2019 to 2024. We provide an overview of the common phases of ML, review available profilers and benchmarks, examine the I/O patterns encountered during ML training, explore I/O optimizations utilized in modern ML frameworks and proposed in recent literature, and lastly, present gaps requiring further R&D. We seek to summarize the common practices used in accessing data by ML applications and expose research gaps that could spawn further R&D.
Read more4/17/2024