AIMDiT: Modality Augmentation and Interaction via Multimodal Dimension Transformation for Emotion Recognition in Conversations

0
👁️
Sign in to get full access
Overview
- Emotion Recognition in Conversations (ERC) is a task in natural language processing that aims to recognize the emotional state of speakers in conversations.
- Current research focuses on modeling context, but there is a lack of investigation into effective multimodal fusion methods.
- The paper proposes a novel framework called AIMDiT to solve the problem of multimodal fusion of deep features.
Plain English Explanation
The paper focuses on a task called Emotion Recognition in Conversations (ERC), which is about identifying the emotional state of people in conversations. While current research mainly looks at how to use the context around the conversation to understand the emotions, the paper says there isn't enough work on effective ways to combine information from different sources, like text and audio.
To address this, the paper introduces a new framework called AIMDiT. This framework has two key parts:
- Modality Augmentation Network: This part takes the different types of information (like text and audio) and transforms them in a way that helps them work better together.
- Modality Interaction Network: This part takes the transformed information from the different sources and combines them in a way that helps to understand the emotions better.
The researchers tested this framework on a public dataset and found that it performed better than other state-of-the-art models, improving the accuracy by 2.34% and the weighted F1-score by 2.87%.
Technical Explanation
The paper proposes a novel framework called AIMDiT to address the problem of multimodal fusion in Emotion Recognition in Conversations (ERC). The framework consists of two key components:
-
Modality Augmentation Network: This network performs rich representation learning through dimension transformation of different modalities and a parameter-efficient inception block. This helps to enhance the deep features extracted from the different modalities.
-
Modality Interaction Network: This network performs interaction fusion of the extracted inter-modal features and intra-modal features. This allows the model to effectively combine the information from the different modalities to better recognize the emotions.
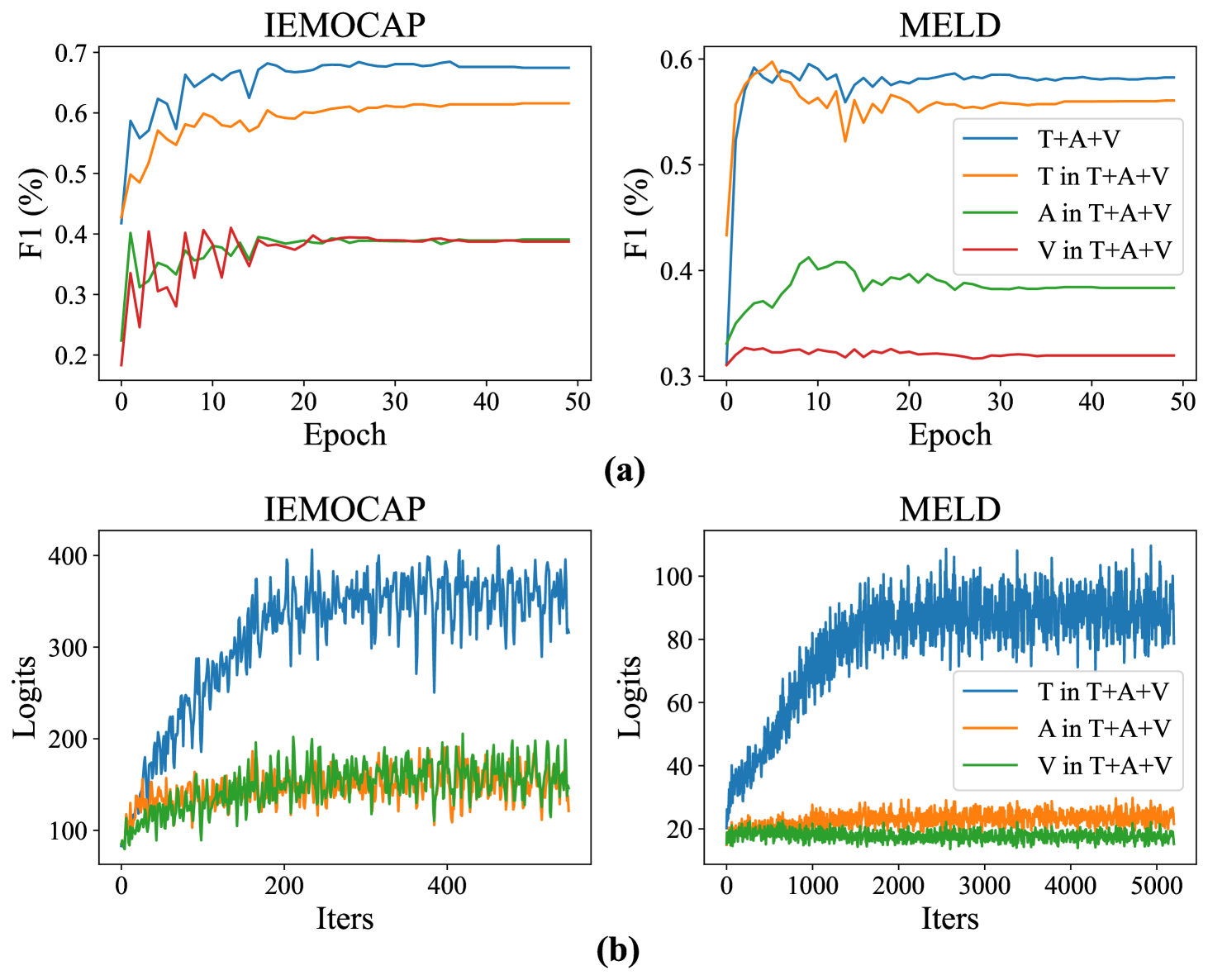
The researchers evaluated their AIMDiT framework on the public MELD dataset. The results show that their approach outperforms state-of-the-art models, achieving 2.34% and 2.87% improvements in Acc-7 and w-F1 metrics, respectively.
Critical Analysis
The paper presents a promising approach to the problem of multimodal fusion in Emotion Recognition in Conversations (ERC). The proposed AIMDiT framework addresses the lack of research in this area, as pointed out by the authors.
However, the paper does not discuss any potential limitations or caveats of the proposed approach. For example, it would be helpful to know how the framework performs on more diverse or noisy datasets, or how it compares to other multimodal fusion methods beyond the state-of-the-art models mentioned.
Additionally, the paper does not explore the potential trade-offs or challenges that may arise from the Modality Augmentation and Modality Interaction components, such as increased model complexity or sensitivity to noisy input data.
Further research could also investigate the dynamic selection of modalities based on their relevance to the task, which may lead to more efficient and robust multimodal fusion.
Conclusion
The paper presents a novel framework called AIMDiT that addresses the problem of multimodal fusion in Emotion Recognition in Conversations (ERC). The framework consists of two key components: the Modality Augmentation Network and the Modality Interaction Network. Experimental results show that the AIMDiT framework outperforms state-of-the-art models on the MELD dataset.
This research contributes to the ongoing efforts in the field of multimodal emotion recognition, which has important applications in areas like human-computer interaction and mental health monitoring. While the paper demonstrates the potential of the AIMDiT framework, further research is needed to address its limitations and explore additional ways to effectively combine information from multiple modalities for this task.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
AIMDiT: Modality Augmentation and Interaction via Multimodal Dimension Transformation for Emotion Recognition in Conversations
Sheng Wu, Jiaxing Liu, Longbiao Wang, Dongxiao He, Xiaobao Wang, Jianwu Dang
Emotion Recognition in Conversations (ERC) is a popular task in natural language processing, which aims to recognize the emotional state of the speaker in conversations. While current research primarily emphasizes contextual modeling, there exists a dearth of investigation into effective multimodal fusion methods. We propose a novel framework called AIMDiT to solve the problem of multimodal fusion of deep features. Specifically, we design a Modality Augmentation Network which performs rich representation learning through dimension transformation of different modalities and parameter-efficient inception block. On the other hand, the Modality Interaction Network performs interaction fusion of extracted inter-modal features and intra-modal features. Experiments conducted using our AIMDiT framework on the public benchmark dataset MELD reveal 2.34% and 2.87% improvements in terms of the Acc-7 and w-F1 metrics compared to the state-of-the-art (SOTA) models.
Read more7/2/2024
0
Ada2I: Enhancing Modality Balance for Multimodal Conversational Emotion Recognition
Cam-Van Thi Nguyen, The-Son Le, Anh-Tuan Mai, Duc-Trong Le
Multimodal Emotion Recognition in Conversations (ERC) is a typical multimodal learning task in exploiting various data modalities concurrently. Prior studies on effective multimodal ERC encounter challenges in addressing modality imbalances and optimizing learning across modalities. Dealing with these problems, we present a novel framework named Ada2I, which consists of two inseparable modules namely Adaptive Feature Weighting (AFW) and Adaptive Modality Weighting (AMW) for feature-level and modality-level balancing respectively via leveraging both Inter- and Intra-modal interactions. Additionally, we introduce a refined disparity ratio as part of our training optimization strategy, a simple yet effective measure to assess the overall discrepancy of the model's learning process when handling multiple modalities simultaneously. Experimental results validate the effectiveness of Ada2I with state-of-the-art performance compared to baselines on three benchmark datasets, particularly in addressing modality imbalances.
Read more8/26/2024

0
DIM: Dynamic Integration of Multimodal Entity Linking with Large Language Model
Shezheng Song, Shasha Li, Jie Yu, Shan Zhao, Xiaopeng Li, Jun Ma, Xiaodong Liu, Zhuo Li, Xiaoguang Mao
Our study delves into Multimodal Entity Linking, aligning the mention in multimodal information with entities in knowledge base. Existing methods are still facing challenges like ambiguous entity representations and limited image information utilization. Thus, we propose dynamic entity extraction using ChatGPT, which dynamically extracts entities and enhances datasets. We also propose a method: Dynamically Integrate Multimodal information with knowledge base (DIM), employing the capability of the Large Language Model (LLM) for visual understanding. The LLM, such as BLIP-2, extracts information relevant to entities in the image, which can facilitate improved extraction of entity features and linking them with the dynamic entity representations provided by ChatGPT. The experiments demonstrate that our proposed DIM method outperforms the majority of existing methods on the three original datasets, and achieves state-of-the-art (SOTA) on the dynamically enhanced datasets (Wiki+, Rich+, Diverse+). For reproducibility, our code and collected datasets are released on url{https://github.com/season1blue/DIM}.
Read more7/18/2024
0
Unimodal Multi-Task Fusion for Emotional Mimicry Intensity Prediction
Tobias Hallmen, Fabian Deuser, Norbert Oswald, Elisabeth Andr'e
In this research, we introduce a novel methodology for assessing Emotional Mimicry Intensity (EMI) as part of the 6th Workshop and Competition on Affective Behavior Analysis in-the-wild. Our methodology utilises the Wav2Vec 2.0 architecture, which has been pre-trained on an extensive podcast dataset, to capture a wide array of audio features that include both linguistic and paralinguistic components. We refine our feature extraction process by employing a fusion technique that combines individual features with a global mean vector, thereby embedding a broader contextual understanding into our analysis. A key aspect of our approach is the multi-task fusion strategy that not only leverages these features but also incorporates a pre-trained Valence-Arousal-Dominance (VAD) model. This integration is designed to refine emotion intensity prediction by concurrently processing multiple emotional dimensions, thereby embedding a richer contextual understanding into our framework. For the temporal analysis of audio data, our feature fusion process utilises a Long Short-Term Memory (LSTM) network. This approach, which relies solely on the provided audio data, shows marked advancements over the existing baseline, offering a more comprehensive understanding of emotional mimicry in naturalistic settings, achieving the second place in the EMI challenge.
Read more6/18/2024