Algorithms for learning value-aligned policies considering admissibility relaxation

0

Sign in to get full access
Overview
- This paper presents algorithms for learning value-aligned policies while considering admissibility relaxation.
- The goal is to develop AI systems that learn policies aligned with human values, while also being flexible and able to handle edge cases.
- The authors explore techniques that balance value alignment and admissibility, a key concept in reinforcement learning.
Plain English Explanation
The researchers in this paper are working on a challenging problem: how to create AI systems that not only do what we want them to do, but also do it in a way that aligns with our values. This is important as we develop more powerful AI that will have a growing impact on the world.
The key idea is to relax the concept of "admissibility" - that is, allowing the AI system to sometimes take actions that may not be strictly "optimal" according to its training, but that better align with human values. This could help the system handle tricky edge cases where following the rules strictly might lead to undesirable outcomes.
For example, imagine an AI system designed to play chess. The standard way to train it would be to focus solely on winning the game. But what if there was a situation where the "best" chess move would involve sacrificing a piece in a way that seems unfair or unsportsmanlike? By relaxing the admissibility constraint, the system could instead make a slightly "suboptimal" move that is more in keeping with the spirit of the game and sportsmanship.
The authors explore different algorithms and techniques to achieve this balance between value alignment and admissibility. Their work has important implications for the development of AI systems that are not just powerful, but also reliably beneficial to humans and society.
Technical Explanation
The paper introduces several algorithms for learning value-aligned policies while considering admissibility relaxation. This builds on prior work in AlignIQL, Quantifying Misalignment, and ROMA-IQSS, which have explored the challenge of aligning AI systems with human values.
The key innovation here is the focus on admissibility relaxation. Traditionally, reinforcement learning algorithms aim to learn an "admissible" policy - one that is optimal according to the reward function. However, this can lead to sub-optimal behavior in edge cases where following the rules strictly goes against human values.
The authors propose several algorithms that learn policies that balance value alignment and admissibility. This includes techniques like ALI, which assess the alignment of a policy with human values, and Value-Augmented Sampling, which modifies the sampling process to prioritize more valuable actions.
Through experiments, the authors demonstrate that their algorithms can learn policies that are both value-aligned and more flexible/admissible than traditional approaches. This has important implications for the development of AI systems that are not just powerful, but also reliably beneficial to humans.
Critical Analysis
The paper presents a valuable contribution to the challenge of value alignment in AI systems. By incorporating admissibility relaxation, the authors address an important limitation of prior work that focused solely on optimizing for value alignment.
That said, the paper does not fully resolve the challenge of value alignment. The authors acknowledge that their techniques still rely on a pre-defined reward function, which may not fully capture the nuance of human values. There is also the risk of unintended consequences, where the relaxation of admissibility leads the AI system to take actions that are misaligned in unexpected ways.
Additionally, the experiments in the paper are relatively limited in scope. While the results are promising, more research is needed to understand how these algorithms would scale and perform in real-world, complex environments.
Future work could explore ways to learn the reward function itself in a more organic, human-centric way, rather than relying on a predefined function. Techniques like inverse reward design or amplified oversight may be promising avenues to explore.
Overall, this paper represents an important step forward in the quest to develop AI systems that are both powerful and reliably beneficial to humanity. By considering admissibility relaxation, the authors have opened up new directions for research in this critical area.
Conclusion
This paper presents a novel approach to learning value-aligned policies in AI systems, with a focus on balancing value alignment and admissibility. By relaxing the strict admissibility constraint, the authors demonstrate that it is possible to develop more flexible and adaptable AI systems that can better handle edge cases and align with human values.
The techniques introduced in this paper, such as the use of alignment assessment and value-augmented sampling, have significant implications for the future development of AI. As we continue to create more powerful and influential AI systems, it will be crucial to ensure that they are not only capable, but also fundamentally aligned with human values and interests.
While challenges remain, this paper represents an important step forward in the quest to develop AI that is truly beneficial to humanity. By continuing to explore innovative approaches to value alignment, researchers can help ensure that the AI systems of the future are not just powerful, but also reliably good.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Algorithms for learning value-aligned policies considering admissibility relaxation
Andr'es Holgado-S'anchez, Joaqu'in Arias, Holger Billhardt, Sascha Ossowski
The emerging field of emph{value awareness engineering} claims that software agents and systems should be value-aware, i.e. they must make decisions in accordance with human values. In this context, such agents must be capable of explicitly reasoning as to how far different courses of action are aligned with these values. For this purpose, values are often modelled as preferences over states or actions, which are then aggregated to determine the sequences of actions that are maximally aligned with a certain value. Recently, additional value admissibility constraints at this level have been considered as well. However, often relaxed versions of these constraints are needed, and this increases considerably the complexity of computing value-aligned policies. To obtain efficient algorithms that make value-aligned decisions considering admissibility relaxation, we propose the use of learning techniques, in particular, we have used constrained reinforcement learning algorithms. In this paper, we present two algorithms, $epsilontext{-}ADQL$ for strategies based on local alignment and its extension $epsilontext{-}CADQL$ for a sequence of decisions. We have validated their efficiency in a water distribution problem in a drought scenario.
Read more6/10/2024

0
Towards Adapting Reinforcement Learning Agents to New Tasks: Insights from Q-Values
Ashwin Ramaswamy, Ransalu Senanayake
While contemporary reinforcement learning research and applications have embraced policy gradient methods as the panacea of solving learning problems, value-based methods can still be useful in many domains as long as we can wrangle with how to exploit them in a sample efficient way. In this paper, we explore the chaotic nature of DQNs in reinforcement learning, while understanding how the information that they retain when trained can be repurposed for adapting a model to different tasks. We start by designing a simple experiment in which we are able to observe the Q-values for each state and action in an environment. Then we train in eight different ways to explore how these training algorithms affect the way that accurate Q-values are learned (or not learned). We tested the adaptability of each trained model when retrained to accomplish a slightly modified task. We then scaled our setup to test the larger problem of an autonomous vehicle at an unprotected intersection. We observed that the model is able to adapt to new tasks quicker when the base model's Q-value estimates are closer to the true Q-values. The results provide some insights and guidelines into what algorithms are useful for sample efficient task adaptation.
Read more7/16/2024
🛠️
0
AlignIQL: Policy Alignment in Implicit Q-Learning through Constrained Optimization
Longxiang He, Li Shen, Junbo Tan, Xueqian Wang
Implicit Q-learning (IQL) serves as a strong baseline for offline RL, which learns the value function using only dataset actions through quantile regression. However, it is unclear how to recover the implicit policy from the learned implicit Q-function and why IQL can utilize weighted regression for policy extraction. IDQL reinterprets IQL as an actor-critic method and gets weights of implicit policy, however, this weight only holds for the optimal value function. In this work, we introduce a different way to solve the implicit policy-finding problem (IPF) by formulating this problem as an optimization problem. Based on this optimization problem, we further propose two practical algorithms AlignIQL and AlignIQL-hard, which inherit the advantages of decoupling actor from critic in IQL and provide insights into why IQL can use weighted regression for policy extraction. Compared with IQL and IDQL, we find our method keeps the simplicity of IQL and solves the implicit policy-finding problem. Experimental results on D4RL datasets show that our method achieves competitive or superior results compared with other SOTA offline RL methods. Especially in complex sparse reward tasks like Antmaze and Adroit, our method outperforms IQL and IDQL by a significant margin.
Read more5/29/2024
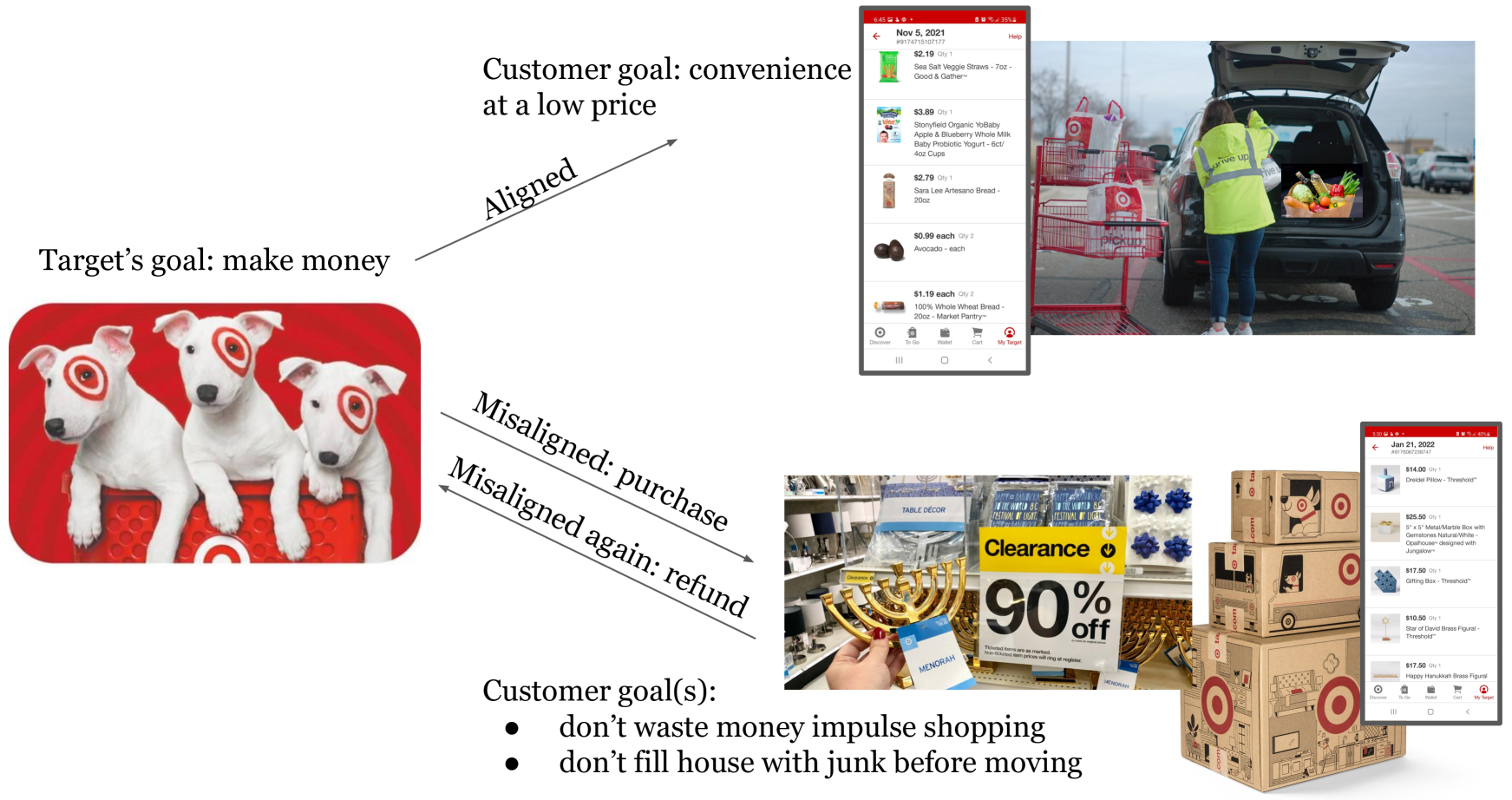
0
Quantifying Misalignment Between Agents
Aidan Kierans, Avijit Ghosh, Hananel Hazan, Shiri Dori-Hacohen
Existing work on the alignment problem has focused mainly on (1) qualitative descriptions of the alignment problem; (2) attempting to align AI actions with human interests by focusing on value specification and learning; and/or (3) focusing on a single agent or on humanity as a monolith. Recent sociotechnical approaches highlight the need to understand complex misalignment among multiple human and AI agents. We address this gap by adapting a computational social science model of human contention to the alignment problem. Our model quantifies misalignment in large, diverse agent groups with potentially conflicting goals across various problem areas. Misalignment scores in our framework depend on the observed agent population, the domain in question, and conflict between agents' weighted preferences. Through simulations, we demonstrate how our model captures intuitive aspects of misalignment across different scenarios. We then apply our model to two case studies, including an autonomous vehicle setting, showcasing its practical utility. Our approach offers enhanced explanatory power for complex sociotechnical environments and could inform the design of more aligned AI systems in real-world applications.
Read more9/10/2024