Aligner: Efficient Alignment by Learning to Correct
2402.02416
0
0
⚙️
Abstract
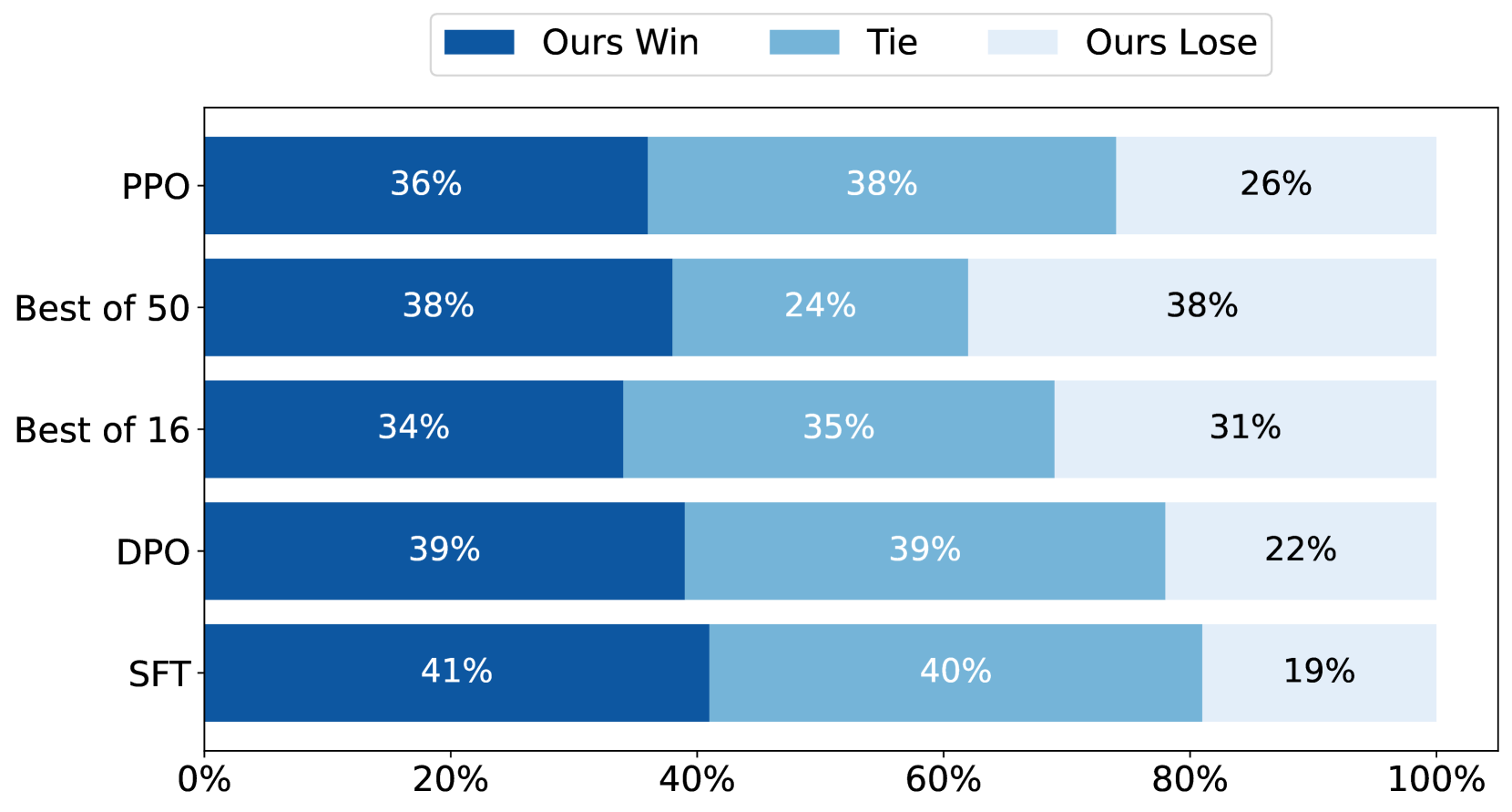
With the rapid development of large language models (LLMs) and ever-evolving practical requirements, finding an efficient and effective alignment method has never been more critical. However, the tension between the complexity of current alignment methods and the need for rapid iteration in deployment scenarios necessitates the development of a model-agnostic alignment approach that can operate under these constraints. In this paper, we introduce Aligner, a novel and simple alignment paradigm that learns the correctional residuals between preferred and dispreferred answers using a small model. Designed as a model-agnostic, plug-and-play module, Aligner can be directly applied to various open-source and API-based models with only one-off training, making it suitable for rapid iteration. Notably, Aligner can be applied to any powerful, large-scale upstream models. Moreover, it can even iteratively bootstrap the upstream models using corrected responses as synthetic human preference data, breaking through the model's performance ceiling. Our experiments demonstrate performance improvements by deploying the same Aligner model across 11 different LLMs, evaluated on the 3H dimensions (helpfulness, harmlessness, and honesty). Specifically, Aligner-7B has achieved an average improvement of 68.9% in helpfulness and 23.8% in harmlessness across the tested LLMs while also effectively reducing hallucination. In the Alpaca-Eval leaderboard, stacking Aligner-2B on GPT-4 Turbo improved its LC Win Rate from 55.0% to 58.3%, surpassing GPT-4 Omni's 57.5% Win Rate (community report).
Create account to get full access
Overview
- Introduces a new alignment method called "Aligner" to address the tension between complex alignment methods and the need for rapid deployment
- Aligner is a model-agnostic, plug-and-play module that learns the corrective residuals between preferred and dispreferred answers using a small model
- Can be applied to various open-source and API-based models with one-off training, enabling rapid iteration
- Can even iteratively bootstrap the upstream models using corrected responses as synthetic human preference data
Plain English Explanation
As large language models (LLMs) continue to advance rapidly, it has become critical to find efficient and effective methods to align them with human preferences. However, the complexity of current alignment methods and the need for quick deployment in real-world scenarios have created a challenge.
The paper introduces a new approach called Aligner that aims to address this issue. Aligner is a simple, model-agnostic, and plug-and-play module that can be easily applied to various LLMs. It works by learning the differences between the model's responses and the preferred responses, and then applying those corrections to the model's outputs.
One of the key advantages of Aligner is that it can be trained on a small model and then applied to much larger, more powerful LLMs. This makes it suitable for rapid iteration and deployment, as the same Aligner model can be used across multiple LLMs without the need for complex retraining.
Moreover, Aligner can even help improve the performance of the upstream LLMs by using the corrected responses as synthetic human preference data to further train the models. This can help break through the performance ceiling of the original models.
Technical Explanation
The paper introduces Aligner, a novel alignment method that learns the corrective residuals between preferred and dispreferred answers using a small model. Aligner is designed as a model-agnostic, plug-and-play module that can be directly applied to various open-source and API-based LLMs with only one-off training, making it suitable for rapid iteration.
The key idea behind Aligner is to learn a small model that captures the difference between the model's responses and the preferred responses. This corrective model can then be applied to the outputs of the larger, more powerful LLMs to align them with human preferences.
The paper demonstrates the effectiveness of Aligner through experiments on 11 different LLMs, evaluating the models on the 3H dimensions (helpfulness, harmlessness, and honesty). The results show that deploying the same Aligner model across these LLMs can lead to significant performance improvements, with an average increase of 68.9% in helpfulness and 23.8% in harmlessness.
Furthermore, the paper shows that Aligner can be used to iteratively bootstrap the upstream LLMs by using the corrected responses as synthetic human preference data. This approach helps the LLMs surpass their original performance ceilings, as demonstrated by the Alpaca-Eval leaderboard results.
Critical Analysis
The paper presents a promising approach to addressing the challenge of aligning LLMs with human preferences in a rapid and efficient manner. The Aligner model's ability to be applied across various LLMs with one-off training is a significant advantage, as it enables quick deployment and iteration.
However, the paper does not delve into the potential limitations or caveats of the Aligner approach. For example, it would be useful to understand how well Aligner performs on more diverse or specialized LLMs, or how it handles cases where the model's responses are significantly different from the preferred responses.
Additionally, the paper does not provide a deeper analysis of the corrective model's architecture or the training process. Understanding these details could shed light on the scalability and robustness of the Aligner approach.
Nonetheless, the paper's findings are promising and suggest that the Aligner approach could be a valuable contribution to the field of LLM alignment. Further research and exploration of the method's limitations and applicability to a wider range of scenarios would be valuable.
Conclusion
The paper introduces a novel alignment method called Aligner that addresses the tension between the complexity of current alignment methods and the need for rapid iteration in deployment scenarios. Aligner is a model-agnostic, plug-and-play module that can be easily applied to various LLMs, enabling quick deployment and iteration.
The key advantages of Aligner are its simplicity, versatility, and ability to iteratively bootstrap the upstream LLMs by using corrected responses as synthetic human preference data. The experiments demonstrate significant performance improvements across 11 different LLMs, highlighting the potential of this approach to advance the state of the art in LLM alignment.
While the paper provides a solid foundation, further research is needed to explore the method's limitations and its applicability to a wider range of scenarios. Nonetheless, the Aligner approach represents an important step forward in addressing the critical challenge of aligning LLMs with human preferences in an efficient and effective manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Aligners: Decoupling LLMs and Alignment
Lilian Ngweta, Mayank Agarwal, Subha Maity, Alex Gittens, Yuekai Sun, Mikhail Yurochkin
0
0
Large Language Models (LLMs) need to be aligned with human expectations to ensure their safety and utility in most applications. Alignment is challenging, costly, and needs to be repeated for every LLM and alignment criterion. We propose to decouple LLMs and alignment by training aligner models that can be used to align any LLM for a given criteria on an as-needed basis, thus also reducing the potential negative impacts of alignment on performance. Our recipe for training the aligner models solely relies on synthetic data generated with a (prompted) LLM and can be easily adjusted for a variety of alignment criteria. We use the same synthetic data to train inspectors, binary miss-alignment classification models to guide a squad of multiple aligners. Our empirical results demonstrate consistent improvements when applying aligner squad to various LLMs, including chat-aligned models, across several instruction-following and red-teaming datasets.
6/18/2024

Decoupled Alignment for Robust Plug-and-Play Adaptation
Haozheng Luo, Jiahao Yu, Wenxin Zhang, Jialong Li, Jerry Yao-Chieh Hu, Xinyu Xing, Han Liu
0
0
We introduce a low-resource safety enhancement method for aligning large language models (LLMs) without the need for supervised fine-tuning (SFT) or reinforcement learning from human feedback (RLHF). Our main idea is to exploit knowledge distillation to extract the alignment information from existing well-aligned LLMs and integrate it into unaligned LLMs in a plug-and-play fashion. Methodology, we employ delta debugging to identify the critical components of knowledge necessary for effective distillation. On the harmful question dataset, our method significantly enhances the average defense success rate by approximately 14.41%, reaching as high as 51.39%, in 17 unaligned pre-trained LLMs, without compromising performance.
6/7/2024
Linear Alignment: A Closed-form Solution for Aligning Human Preferences without Tuning and Feedback
Songyang Gao, Qiming Ge, Wei Shen, Shihan Dou, Junjie Ye, Xiao Wang, Rui Zheng, Yicheng Zou, Zhi Chen, Hang Yan, Qi Zhang, Dahua Lin
0
0
The success of AI assistants based on Language Models (LLMs) hinges on Reinforcement Learning from Human Feedback (RLHF) to comprehend and align with user intentions. However, traditional alignment algorithms, such as PPO, are hampered by complex annotation and training requirements. This reliance limits the applicability of RLHF and hinders the development of professional assistants tailored to diverse human preferences. In this work, we introduce textit{Linear Alignment}, a novel algorithm that aligns language models with human preferences in one single inference step, eliminating the reliance on data annotation and model training. Linear alignment incorporates a new parameterization for policy optimization under divergence constraints, which enables the extraction of optimal policy in a closed-form manner and facilitates the direct estimation of the aligned response. Extensive experiments on both general and personalized preference datasets demonstrate that linear alignment significantly enhances the performance and efficiency of LLM alignment across diverse scenarios. Our code and dataset is published on url{https://github.com/Wizardcoast/Linear_Alignment.git}.
5/7/2024

Efficient Model-agnostic Alignment via Bayesian Persuasion
Fengshuo Bai, Mingzhi Wang, Zhaowei Zhang, Boyuan Chen, Yinda Xu, Ying Wen, Yaodong Yang
0
0
With recent advancements in large language models (LLMs), alignment has emerged as an effective technique for keeping LLMs consensus with human intent. Current methods primarily involve direct training through Supervised Fine-tuning (SFT) or Reinforcement Learning from Human Feedback (RLHF), both of which require substantial computational resources and extensive ground truth data. This paper explores an efficient method for aligning black-box large models using smaller models, introducing a model-agnostic and lightweight Bayesian Persuasion Alignment framework. We formalize this problem as an optimization of the signaling strategy from the small model's perspective. In the persuasion process, the small model (Advisor) observes the information item (i.e., state) and persuades large models (Receiver) to elicit improved responses. The Receiver then generates a response based on the input, the signal from the Advisor, and its updated belief about the information item. Through training using our framework, we demonstrate that the Advisor can significantly enhance the performance of various Receivers across a range of tasks. We theoretically analyze our persuasion framework and provide an upper bound on the Advisor's regret, confirming its effectiveness in learning the optimal signaling strategy. Our Empirical results demonstrates that GPT-2 can significantly improve the performance of various models, achieving an average enhancement of 16.1% in mathematical reasoning ability and 13.7% in code generation. We hope our work can provide an initial step toward rethinking the alignment framework from the Bayesian Persuasion perspective.
5/30/2024