Aligning Individual and Collective Objectives in Multi-Agent Cooperation
2402.12416
0
0

Abstract
Among the research topics in multi-agent learning, mixed-motive cooperation is one of the most prominent challenges, primarily due to the mismatch between individual and collective goals. The cutting-edge research is focused on incorporating domain knowledge into rewards and introducing additional mechanisms to incentivize cooperation. However, these approaches often face shortcomings such as the effort on manual design and the absence of theoretical groundings. To close this gap, we model the mixed-motive game as a differentiable game for the ease of illuminating the learning dynamics towards cooperation. More detailed, we introduce a novel optimization method named textbf{textit{A}}ltruistic textbf{textit{G}}radient textbf{textit{A}}djustment (textbf{textit{AgA}}) that employs gradient adjustments to progressively align individual and collective objectives. Furthermore, we theoretically prove that AgA effectively attracts gradients to stable fixed points of the collective objective while considering individual interests, and we validate these claims with empirical evidence. We evaluate the effectiveness of our algorithm AgA through benchmark environments for testing mixed-motive collaboration with small-scale agents such as the two-player public good game and the sequential social dilemma games, Cleanup and Harvest, as well as our self-developed large-scale environment in the game StarCraft II.
Create account to get full access
Overview
- The paper explores how to align individual and collective objectives in multi-agent cooperation scenarios
- It proposes new methods to incentivize agents to work towards the common good while still satisfying their own interests
- The research has applications in areas like cooperative task execution in multi-agent systems, group-aware coordination in multi-agent reinforcement learning, and n-agent ad-hoc teamwork
Plain English Explanation
The paper looks at the challenge of getting a group of AI agents to work together effectively towards a shared goal, while also ensuring that each agent's individual interests are met. This can be tricky, as an agent might be tempted to prioritize its own needs over the group's objectives.
The researchers propose new techniques to incentivize the agents to contribute to the collective good, while still allowing them to satisfy their own motivations. For example, the agents could be rewarded not just for achieving the overall team goal, but also for how well they coordinate and support each other along the way.
By aligning the individual and collective objectives in this way, the hope is that the agents will be more willing to make beneficial compromises and cooperate more seamlessly. This could lead to improved performance on tasks that require tight coordination between multiple AI systems, like self-driving car fleets or robot swarms working together.
Technical Explanation
The paper formalizes the multi-agent cooperation problem as a Markov game, where each agent has its own reward function that may not be perfectly aligned with the group's objective. The authors propose a new training framework called Collective Reward Shaping (CRS) that modifies the individual reward functions to incentivize cooperative behavior.
CRS works by decomposing the group's overall reward into two components - an individual reward for each agent based on their own actions, and a collective reward that captures the team's performance. The individual rewards are then adjusted using a shaped reward function that balances these two objectives.
The authors evaluate CRS on several benchmark multi-agent environments, including a networking scenario where AI agents must optimize a shared generative model. They show that CRS leads to significantly improved cooperation and task performance compared to standard approaches that only consider the group's objective.
Critical Analysis
The paper provides a promising framework for aligning individual and collective goals in multi-agent systems. However, some key limitations and open questions remain:
- The shaped reward function used in CRS requires careful tuning of hyperparameters to balance the individual and collective components. More robust methods for automatically determining these weights would be valuable.
- The experiments are conducted in relatively simple, synthetic environments. Extending the approach to more complex, real-world multi-agent problems like coordination in autonomous vehicle fleets is an important next step.
- The paper does not address how to handle agents with fundamentally misaligned objectives that may actively work against the group's goals. Developing methods to identify and mitigate such adversarial behavior would be an interesting direction for future research.
Overall, this work makes a valuable contribution to the challenge of multi-agent cooperation, but there is still significant room for improvement and further exploration.
Conclusion
This paper proposes a new framework called Collective Reward Shaping (CRS) to better align individual and collective objectives in multi-agent cooperation scenarios. CRS modifies the individual agent reward functions to incentivize cooperative behavior that benefits the group as a whole.
The results demonstrate that CRS can lead to improved coordination and task performance compared to standard approaches. This work has important implications for developing AI systems that can work together seamlessly, with applications in areas like multi-agent robotics, autonomous vehicle fleets, and distributed machine learning.
While this paper represents a promising step forward, there are still some limitations and open challenges that require further research. Ongoing work in this area will help unlock the full potential of cooperative multi-agent systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
Cooperation Dynamics in Multi-Agent Systems: Exploring Game-Theoretic Scenarios with Mean-Field Equilibria
Vaigarai Sathi, Sabahat Shaik, Jaswanth Nidamanuri
0
0
Cooperation is fundamental in Multi-Agent Systems (MAS) and Multi-Agent Reinforcement Learning (MARL), often requiring agents to balance individual gains with collective rewards. In this regard, this paper aims to investigate strategies to invoke cooperation in game-theoretic scenarios, namely the Iterated Prisoner's Dilemma, where agents must optimize both individual and group outcomes. Existing cooperative strategies are analyzed for their effectiveness in promoting group-oriented behavior in repeated games. Modifications are proposed where encouraging group rewards will also result in a higher individual gain, addressing real-world dilemmas seen in distributed systems. The study extends to scenarios with exponentially growing agent populations ($N longrightarrow +infty$), where traditional computation and equilibrium determination are challenging. Leveraging mean-field game theory, equilibrium solutions and reward structures are established for infinitely large agent sets in repeated games. Finally, practical insights are offered through simulations using the Multi Agent-Posthumous Credit Assignment trainer, and the paper explores adapting simulation algorithms to create scenarios favoring cooperation for group rewards. These practical implementations bridge theoretical concepts with real-world applications.
5/6/2024
📉
Cognitive Insights and Stable Coalition Matching for Fostering Multi-Agent Cooperation
Jiaqi Shao, Tianjun Yuan, Tao Lin, Xuanyu Cao, Bing Luo
0
0
Cognitive abilities, such as Theory of Mind (ToM), play a vital role in facilitating cooperation in human social interactions. However, our study reveals that agents with higher ToM abilities may not necessarily exhibit better cooperative behavior compared to those with lower ToM abilities. To address this challenge, we propose a novel matching coalition mechanism that leverages the strengths of agents with different ToM levels by explicitly considering belief alignment and specialized abilities when forming coalitions. Our proposed matching algorithm seeks to find stable coalitions that maximize the potential for cooperative behavior and ensure long-term viability. By incorporating cognitive insights into the design of multi-agent systems, our work demonstrates the potential of leveraging ToM to create more sophisticated and human-like coordination strategies that foster cooperation and improve overall system performance.
5/29/2024

N-Agent Ad Hoc Teamwork
Caroline Wang, Arrasy Rahman, Ishan Durugkar, Elad Liebman, Peter Stone
0
0
Current approaches to learning cooperative behaviors in multi-agent settings assume relatively restrictive settings. In standard fully cooperative multi-agent reinforcement learning, the learning algorithm controls textit{all} agents in the scenario, while in ad hoc teamwork, the learning algorithm usually assumes control over only a $textit{single}$ agent in the scenario. However, many cooperative settings in the real world are much less restrictive. For example, in an autonomous driving scenario, a company might train its cars with the same learning algorithm, yet once on the road, these cars must cooperate with cars from another company. Towards generalizing the class of scenarios that cooperative learning methods can address, we introduce $N$-agent ad hoc teamwork, in which a set of autonomous agents must interact and cooperate with dynamically varying numbers and types of teammates at evaluation time. This paper formalizes the problem, and proposes the $textit{Policy Optimization with Agent Modelling}$ (POAM) algorithm. POAM is a policy gradient, multi-agent reinforcement learning approach to the NAHT problem, that enables adaptation to diverse teammate behaviors by learning representations of teammate behaviors. Empirical evaluation on StarCraft II tasks shows that POAM improves cooperative task returns compared to baseline approaches, and enables out-of-distribution generalization to unseen teammates.
4/17/2024
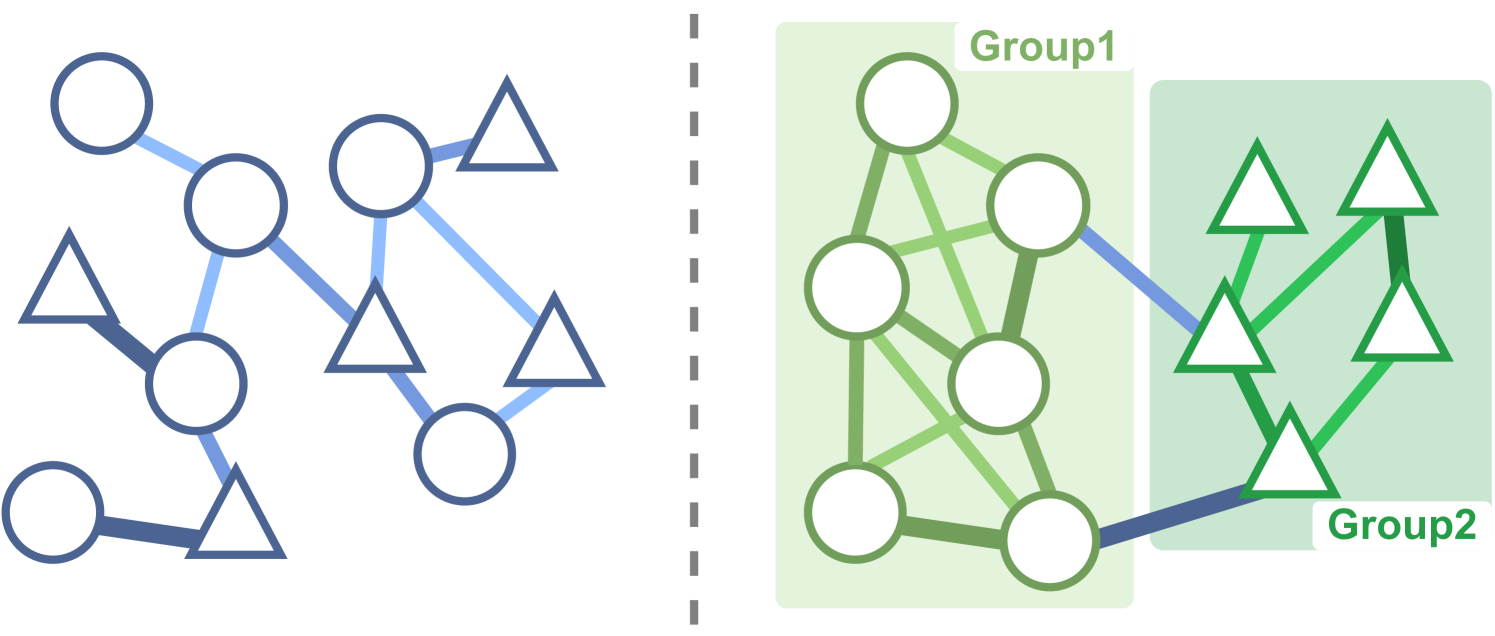
Group-Aware Coordination Graph for Multi-Agent Reinforcement Learning
Wei Duan, Jie Lu, Junyu Xuan
0
0
Cooperative Multi-Agent Reinforcement Learning (MARL) necessitates seamless collaboration among agents, often represented by an underlying relation graph. Existing methods for learning this graph primarily focus on agent-pair relations, neglecting higher-order relationships. While several approaches attempt to extend cooperation modelling to encompass behaviour similarities within groups, they commonly fall short in concurrently learning the latent graph, thereby constraining the information exchange among partially observed agents. To overcome these limitations, we present a novel approach to infer the Group-Aware Coordination Graph (GACG), which is designed to capture both the cooperation between agent pairs based on current observations and group-level dependencies from behaviour patterns observed across trajectories. This graph is further used in graph convolution for information exchange between agents during decision-making. To further ensure behavioural consistency among agents within the same group, we introduce a group distance loss, which promotes group cohesion and encourages specialization between groups. Our evaluations, conducted on StarCraft II micromanagement tasks, demonstrate GACG's superior performance. An ablation study further provides experimental evidence of the effectiveness of each component of our method.
5/14/2024