Cooperation Dynamics in Multi-Agent Systems: Exploring Game-Theoretic Scenarios with Mean-Field Equilibria
2309.16263
0
0
🤔
Abstract
Cooperation is fundamental in Multi-Agent Systems (MAS) and Multi-Agent Reinforcement Learning (MARL), often requiring agents to balance individual gains with collective rewards. In this regard, this paper aims to investigate strategies to invoke cooperation in game-theoretic scenarios, namely the Iterated Prisoner's Dilemma, where agents must optimize both individual and group outcomes. Existing cooperative strategies are analyzed for their effectiveness in promoting group-oriented behavior in repeated games. Modifications are proposed where encouraging group rewards will also result in a higher individual gain, addressing real-world dilemmas seen in distributed systems. The study extends to scenarios with exponentially growing agent populations ($N longrightarrow +infty$), where traditional computation and equilibrium determination are challenging. Leveraging mean-field game theory, equilibrium solutions and reward structures are established for infinitely large agent sets in repeated games. Finally, practical insights are offered through simulations using the Multi Agent-Posthumous Credit Assignment trainer, and the paper explores adapting simulation algorithms to create scenarios favoring cooperation for group rewards. These practical implementations bridge theoretical concepts with real-world applications.
Create account to get full access
Overview
- This paper explores strategies to promote cooperation among agents in multi-agent systems and multi-agent reinforcement learning scenarios, using the Iterated Prisoner's Dilemma as a game-theoretic model.
- It analyzes existing cooperative strategies and proposes modifications to encourage group-oriented behavior that also benefits individual agents.
- The study extends to large-scale systems with exponentially growing agent populations, leveraging mean-field game theory to establish equilibrium solutions and reward structures.
- The paper also provides practical insights through simulations using the Multi Agent-Posthumous Credit Assignment trainer and explores adapting algorithms to create scenarios favoring cooperation for group rewards.
Plain English Explanation
In multi-agent systems and reinforcement learning, cooperation between agents is crucial. Agents often need to balance their individual gains with the collective rewards of the group. This paper explores strategies to encourage cooperation in the Iterated Prisoner's Dilemma, a game-theoretic scenario where agents must optimize both their individual and group outcomes.
The researchers analyze existing cooperative strategies to see how well they promote group-oriented behavior in repeated games. They then propose modifications to these strategies, where encouraging group rewards will also result in higher individual gains. This addresses real-world dilemmas often seen in distributed systems, where agents may be tempted to prioritize their own interests over the group's.
The study also looks at scenarios with exponentially growing agent populations, where traditional computational methods and equilibrium determination become challenging. By leveraging mean-field game theory, the researchers establish equilibrium solutions and reward structures for infinitely large agent sets in repeated games.
Finally, the paper provides practical insights through simulations using the Multi Agent-Posthumous Credit Assignment trainer. The researchers explore adapting simulation algorithms to create scenarios that favor cooperation for group rewards, bridging the gap between theoretical concepts and real-world applications.
Technical Explanation
The paper investigates strategies to invoke cooperation in game-theoretic scenarios, specifically the Iterated Prisoner's Dilemma, where agents must optimize both individual and group outcomes. Existing cooperative strategies are analyzed for their effectiveness in promoting group-oriented behavior in repeated games, and modifications are proposed to encourage group rewards that also result in higher individual gains.
The study extends to scenarios with exponentially growing agent populations ($N \rightarrow +\infty$), where traditional computation and equilibrium determination are challenging. Leveraging mean-field game theory, the researchers establish equilibrium solutions and reward structures for infinitely large agent sets in repeated games.
The paper also provides practical insights through simulations using the Multi Agent-Posthumous Credit Assignment trainer, and explores adapting simulation algorithms to create scenarios favoring cooperation for group rewards. These practical implementations aim to bridge the gap between theoretical concepts and real-world applications.
Critical Analysis
The paper presents a comprehensive analysis of cooperative strategies in multi-agent systems and reinforcement learning, focusing on the Iterated Prisoner's Dilemma as a game-theoretic model. The proposed modifications to existing strategies, which align individual and group rewards, address an important challenge in real-world distributed systems.
The extension of the study to large-scale scenarios with exponentially growing agent populations is a notable contribution, as it tackles the computational and equilibrium determination challenges in such settings. The use of mean-field game theory provides a scalable approach to establishing equilibrium solutions and reward structures.
However, the paper does not extensively discuss the limitations or potential drawbacks of the proposed strategies. It would be valuable to explore scenarios where the strategies may not be as effective, or to consider potential unintended consequences that may arise from incentivizing group-oriented behavior.
Additionally, the paper could have delved deeper into the practical implications of the simulations and the adaptations made to the algorithms. More details on the specific scenarios, the performance metrics, and the lessons learned from the simulations would strengthen the connection between the theoretical concepts and real-world applications.
Conclusion
This paper presents a comprehensive investigation into strategies to promote cooperation in multi-agent systems and reinforcement learning, using the Iterated Prisoner's Dilemma as a game-theoretic model. The researchers analyze existing cooperative strategies, propose modifications to align individual and group rewards, and extend the study to large-scale scenarios with exponentially growing agent populations.
The practical insights provided through simulations and algorithm adaptations demonstrate the potential for bridging theoretical concepts with real-world applications. This research contributes to the ongoing efforts to foster cooperation and collective decision-making in distributed systems, with implications for a wide range of domains, from robotics and autonomous vehicles to distributed computing and sustainable resource management.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Robust Cooperative Multi-Agent Reinforcement Learning:A Mean-Field Type Game Perspective
Muhammad Aneeq uz Zaman, Mathieu Lauri`ere, Alec Koppel, Tamer Bac{s}ar
0
0
In this paper, we study the problem of robust cooperative multi-agent reinforcement learning (RL) where a large number of cooperative agents with distributed information aim to learn policies in the presence of emph{stochastic} and emph{non-stochastic} uncertainties whose distributions are respectively known and unknown. Focusing on policy optimization that accounts for both types of uncertainties, we formulate the problem in a worst-case (minimax) framework, which is is intractable in general. Thus, we focus on the Linear Quadratic setting to derive benchmark solutions. First, since no standard theory exists for this problem due to the distributed information structure, we utilize the Mean-Field Type Game (MFTG) paradigm to establish guarantees on the solution quality in the sense of achieved Nash equilibrium of the MFTG. This in turn allows us to compare the performance against the corresponding original robust multi-agent control problem. Then, we propose a Receding-horizon Gradient Descent Ascent RL algorithm to find the MFTG Nash equilibrium and we prove a non-asymptotic rate of convergence. Finally, we provide numerical experiments to demonstrate the efficacy of our approach relative to a baseline algorithm.
6/21/2024

Aligning Individual and Collective Objectives in Multi-Agent Cooperation
Yang Li, Wenhao Zhang, Jianhong Wang, Shao Zhang, Yali Du, Ying Wen, Wei Pan
0
0
Among the research topics in multi-agent learning, mixed-motive cooperation is one of the most prominent challenges, primarily due to the mismatch between individual and collective goals. The cutting-edge research is focused on incorporating domain knowledge into rewards and introducing additional mechanisms to incentivize cooperation. However, these approaches often face shortcomings such as the effort on manual design and the absence of theoretical groundings. To close this gap, we model the mixed-motive game as a differentiable game for the ease of illuminating the learning dynamics towards cooperation. More detailed, we introduce a novel optimization method named textbf{textit{A}}ltruistic textbf{textit{G}}radient textbf{textit{A}}djustment (textbf{textit{AgA}}) that employs gradient adjustments to progressively align individual and collective objectives. Furthermore, we theoretically prove that AgA effectively attracts gradients to stable fixed points of the collective objective while considering individual interests, and we validate these claims with empirical evidence. We evaluate the effectiveness of our algorithm AgA through benchmark environments for testing mixed-motive collaboration with small-scale agents such as the two-player public good game and the sequential social dilemma games, Cleanup and Harvest, as well as our self-developed large-scale environment in the game StarCraft II.
5/24/2024
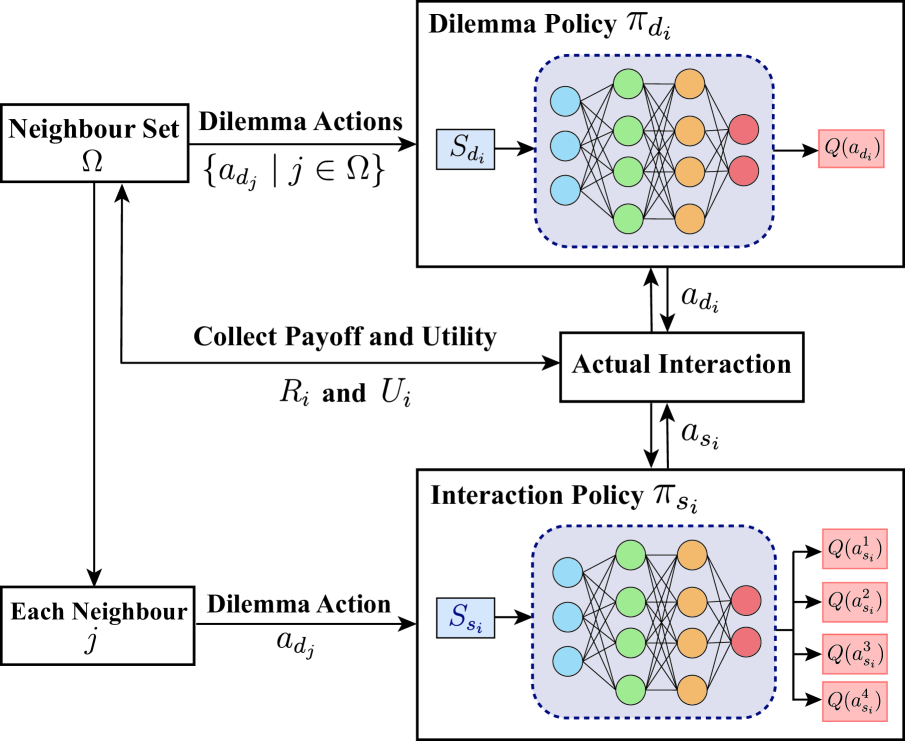
Enhancing Cooperation through Selective Interaction and Long-term Experiences in Multi-Agent Reinforcement Learning
Tianyu Ren, Xiao-Jun Zeng
0
0
The significance of network structures in promoting group cooperation within social dilemmas has been widely recognized. Prior studies attribute this facilitation to the assortment of strategies driven by spatial interactions. Although reinforcement learning has been employed to investigate the impact of dynamic interaction on the evolution of cooperation, there remains a lack of understanding about how agents develop neighbour selection behaviours and the formation of strategic assortment within an explicit interaction structure. To address this, our study introduces a computational framework based on multi-agent reinforcement learning in the spatial Prisoner's Dilemma game. This framework allows agents to select dilemma strategies and interacting neighbours based on their long-term experiences, differing from existing research that relies on preset social norms or external incentives. By modelling each agent using two distinct Q-networks, we disentangle the coevolutionary dynamics between cooperation and interaction. The results indicate that long-term experience enables agents to develop the ability to identify non-cooperative neighbours and exhibit a preference for interaction with cooperative ones. This emergent self-organizing behaviour leads to the clustering of agents with similar strategies, thereby increasing network reciprocity and enhancing group cooperation.
5/7/2024

Agent-based Modelling of Quantum Prisoner's Dilemma
Rajdeep Tah, Colin Benjamin
0
0
What happens when an infinite number of players play a quantum game? In this paper, we will answer this question by looking at the emergence of cooperation in the presence of noise in a one-shot quantum Prisoner's dilemma (QuPD). We will use the numerical Agent-based model (ABM) and compare it with the analytical Nash equilibrium mapping (NEM) technique. To measure cooperation, we consider five indicators, i.e., game magnetization, entanglement susceptibility, correlation, player's payoff average, and payoff capacity, respectively. In quantum social dilemmas, entanglement plays a non-trivial role in determining the players' behavior in the thermodynamic limit, and we consider the existence of bipartite entanglement between neighboring players. For the five indicators in question, we observe textit{first}-order phase transitions at two entanglement values, and these phase transition points depend on the payoffs associated with the QuPD game. We numerically analyze and study the properties of both the textit{Quantum} and the textit{Defect} phases of the QuPD via the five indicators. The results of this paper demonstrate that both ABM and NEM, in conjunction with the chosen five indicators, provide insightful information on cooperative behavior in the thermodynamic limit of the one-shot quantum Prisoner's dilemma.
4/4/2024