Aligning LLM Agents by Learning Latent Preference from User Edits

0
📊
Sign in to get full access
Overview
- The paper explores interactive learning of language agents based on user edits to the agent's output.
- The goal is to improve the agent's alignment with the user's latent preference and reduce the cost of user edits over time.
- The proposed framework, PRELUDE, infers a description of the user's latent preference from historical edit data and uses it to define a prompt policy for future response generation.
- The CIPHER algorithm leverages a large language model (LLM) to infer the user's preference for a given context based on user edits, and aggregates preferences from similar contexts.
- The researchers evaluate their approach on interactive summarization and email writing tasks using a GPT-4 simulated user.
Plain English Explanation
In many applications, such as writing assistants, users interact with a language agent to generate a response, and then have the option to edit the agent's output to personalize it or improve its accuracy. This user feedback can be used to align the agent's behavior with the user's preferences, ultimately reducing the need for edits over time.
The researchers propose a framework called PRELUDE that aims to learn a descriptive representation of the user's latent preference based on their historical edit data. This allows the agent to generate responses that are more aligned with the user's preferences, without the need for costly fine-tuning of the underlying language model. Additionally, the learned preference model can be interpreted and modified by the user, improving transparency.
However, user preferences can be complex and vary based on the context. To address this, the researchers developed an algorithm called CIPHER that leverages a large language model (LLM) to infer the user's preference for a given context, based on their past edits. CIPHER then aggregates preferences from similar contexts to generate responses that are tailored to the user's needs.
The researchers evaluate their approach on two interactive tasks: summarization and email writing, using a GPT-4-based simulated user. They compare their methods to approaches that directly retrieve user edits without learning a descriptive preference model, as well as methods that learn a context-agnostic preference. The results show that CIPHER achieves the lowest edit distance cost and learns preferences that are significantly similar to the ground truth.
Technical Explanation
The paper presents a framework for aligning language models with human preferences based on user edits to the agent's output. In a typical setting, such as a writing assistant, the user interacts with a language agent to generate a response given a context, and may then edit the agent's output to personalize it or improve its correctness. This edit feedback provides a natural way to learn about the user's latent preferences and reduce the cost of user edits over time.
The researchers propose a learning framework called PRELUDE that infers a descriptive representation of the user's latent preference based on their historical edit data. This preference model is then used to define a prompt policy that drives the agent's future response generation. This approach avoids the need for costly fine-tuning of the underlying language model, which can be challenging to scale with the number of users and may even degrade the agent's performance on other tasks. Additionally, learning a descriptive preference model improves interpretability, allowing the user to view and modify the learned preference.
To address the challenge of complex and context-dependent user preferences, the researchers introduce CIPHER, a simple yet effective algorithm that leverages a large language model (LLM) to infer the user's preference for a given context based on their past edits. CIPHER then retrieves and aggregates preferences from the k-closest contexts in the history to generate a response that is tailored to the user's needs.
The researchers evaluate their approach on two interactive tasks: summarization and email writing, using a GPT-4-based simulated user. They compare their methods to algorithms that directly retrieve user edits without learning a descriptive preference model, as well as algorithms that learn a context-agnostic preference. The results show that CIPHER achieves the lowest edit distance cost and learns preferences that are significantly similar to the ground truth, demonstrating the effectiveness of their approach.
Critical Analysis
The paper presents a novel approach to learning the dynamics of alignment with human feedback in language agents, which is an important problem in the field of recommender systems in the era of large language models (LLMs).
One potential limitation of the research is that it relies on a simulated user, which may not fully capture the complexities of real-world user interactions and preferences. It would be valuable to validate the approach on real-world datasets and user studies to better understand its practical applicability and limitations.
Additionally, the paper does not discuss the potential privacy and ethical implications of learning and storing user preferences, which could be a concern in sensitive applications such as profile-centric dialog agents. Addressing these considerations would be an important next step in the research.
Finally, the paper could benefit from a more in-depth discussion of the potential limitations and failure modes of the CIPHER algorithm, as well as areas for future research to improve the robustness and versatility of the proposed approach.
Conclusion
The paper presents a novel framework for interactive learning of language agents based on user edits, with the goal of improving the agent's alignment with the user's latent preferences and reducing the cost of user edits over time. The proposed PRELUDE framework learns a descriptive representation of the user's preference, while the CIPHER algorithm leverages large language models to infer and aggregate preferences across similar contexts.
The evaluation results demonstrate the effectiveness of this approach, suggesting that it could be a valuable tool for developing more personalized and efficient language agents. However, further research is needed to validate the approach in real-world settings and address potential privacy and ethical concerns. Overall, this work represents an important step towards understanding and improving the alignment of language models with human feedback, which is a critical challenge in the field of recommender systems and large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Aligning LLM Agents by Learning Latent Preference from User Edits
Ge Gao, Alexey Taymanov, Eduardo Salinas, Paul Mineiro, Dipendra Misra
We study interactive learning of LLM-based language agents based on user edits made to the agent's output. In a typical setting such as writing assistants, the user interacts with a language agent to generate a response given a context, and may optionally edit the agent response to personalize it based on their latent preference, in addition to improving the correctness. The edit feedback is naturally generated, making it a suitable candidate for improving the agent's alignment with the user's preference, and for reducing the cost of user edits over time. We propose a learning framework, PRELUDE that infers a description of the user's latent preference based on historic edit data. The inferred user preference descriptions are used to define prompts for generating responses in the future. This avoids fine-tuning the agent, which is costly, challenging to scale with the number of users, and may even degrade its performance on other tasks. Furthermore, learning descriptive preference improves interpretability, allowing the user to view and modify the learned preference. However, user preference can be complex, subtle, and vary based on context, making it challenging to learn. To address this, we propose a simple yet effective algorithm named CIPHER that leverages the LLM to infer the user preference for a given context based on user edits. In the future, CIPHER retrieves inferred preferences from the k-closest contexts in the history, and forms an aggregate preference for response generation. We introduce two interactive environments -- summarization and email writing, and use a GPT-4 simulated user for evaluation. On both tasks, CIPHER outperforms several baselines by achieving the lowest edit distance cost while only having a small overhead in LLM query cost. Our analysis reports that user preferences learned by CIPHER show significant similarity to the ground truth latent preferences.
Read more6/11/2024
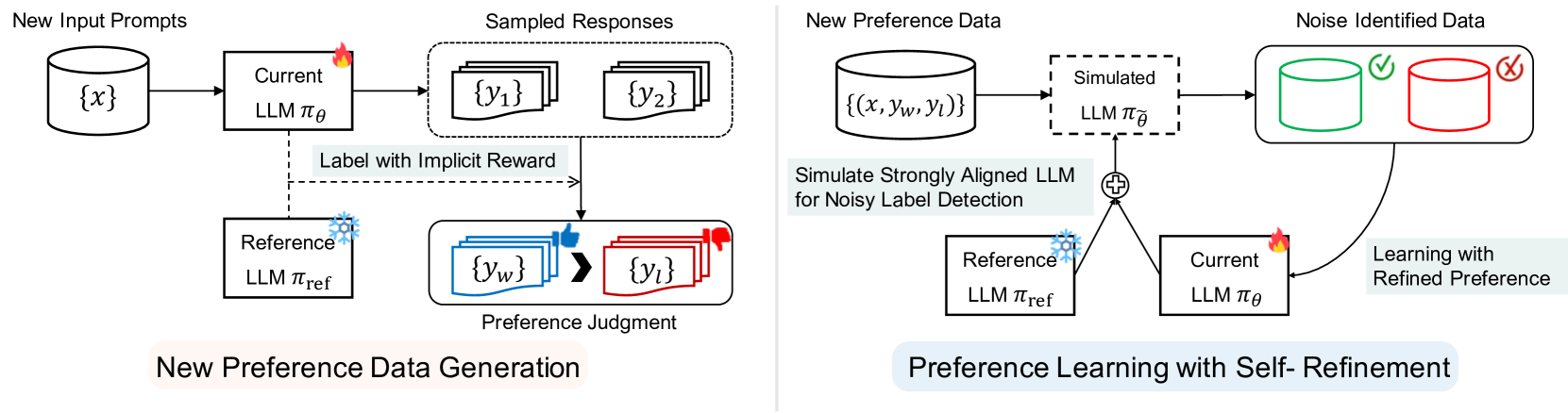
0
Aligning Large Language Models with Self-generated Preference Data
Dongyoung Kim, Kimin Lee, Jinwoo Shin, Jaehyung Kim
Aligning large language models (LLMs) with human preferences becomes a key component to obtaining state-of-the-art performance, but it yields a huge cost to construct a large human-annotated preference dataset. To tackle this problem, we propose a new framework that boosts the alignment of LLMs through Self-generated Preference data (Selfie) using only a very small amount of human-annotated preference data. Our key idea is leveraging the human prior knowledge within the small (seed) data and progressively improving the alignment of LLM, by iteratively generating the responses and learning from them with the self-annotated preference data. To be specific, we propose to derive the preference label from the logits of LLM to explicitly extract the model's inherent preference. Compared to the previous approaches using external reward models or implicit in-context learning, we observe that the proposed approach is significantly more effective. In addition, we introduce a noise-aware preference learning algorithm to mitigate the risk of low quality within generated preference data. Our experimental results demonstrate that the proposed framework significantly boosts the alignment of LLMs. For example, we achieve superior alignment performance on AlpacaEval 2.0 with only 3.3% of the ground-truth preference labels in the Ultrafeedback data compared to the cases using the entire data or state-of-the-art baselines.
Read more6/10/2024
💬
0
Aligning language models with human preferences
Tomasz Korbak
Language models (LMs) trained on vast quantities of text data can acquire sophisticated skills such as generating summaries, answering questions or generating code. However, they also manifest behaviors that violate human preferences, e.g., they can generate offensive content, falsehoods or perpetuate social biases. In this thesis, I explore several approaches to aligning LMs with human preferences. First, I argue that aligning LMs can be seen as Bayesian inference: conditioning a prior (base, pretrained LM) on evidence about human preferences (Chapter 2). Conditioning on human preferences can be implemented in numerous ways. In Chapter 3, I investigate the relation between two approaches to finetuning pretrained LMs using feedback given by a scoring function: reinforcement learning from human feedback (RLHF) and distribution matching. I show that RLHF can be seen as a special case of distribution matching but distributional matching is strictly more general. In chapter 4, I show how to extend the distribution matching to conditional language models. Finally, in chapter 5 I explore a different root: conditioning an LM on human preferences already during pretraining. I show that involving human feedback from the very start tends to be more effective than using it only during supervised finetuning. Overall, these results highlight the room for alignment techniques different from and complementary to RLHF.
Read more4/19/2024

0
Active Preference Inference using Language Models and Probabilistic Reasoning
Wasu Top Piriyakulkij, Volodymyr Kuleshov, Kevin Ellis
Actively inferring user preferences, for example by asking good questions, is important for any human-facing decision-making system. Active inference allows such systems to adapt and personalize themselves to nuanced individual preferences. To enable this ability for instruction-tuned large language models (LLMs), one may prompt them to ask users questions to infer their preferences, transforming the language models into more robust, interactive systems. However, out of the box, these models are not efficient at extracting preferences: the questions they generate are not informative, requiring a high number of user interactions and impeding the usability of the downstream system. In this work, we introduce an inference-time algorithm that helps LLMs quickly infer preferences by using more informative questions. Our algorithm uses a probabilistic model whose conditional distributions are defined by prompting an LLM, and returns questions that optimize expected entropy and expected model change. Results in a simplified interactive web shopping setting with real product items show that an LLM equipped with our entropy reduction algorithm outperforms baselines with the same underlying LLM on task performance while using fewer user interactions.
Read more6/27/2024