Active Preference Inference using Language Models and Probabilistic Reasoning

0

Sign in to get full access
Overview
- This paper presents a method for actively inferring user preferences using language models and probabilistic reasoning.
- The approach involves iteratively refining a model of the user's preferences by selectively querying the user and incorporating their feedback.
- The authors demonstrate the effectiveness of their method on both synthetic and real-world preference learning tasks.
Plain English Explanation
The paper describes a way to better understand what a person prefers or likes, by having them give feedback on different options. It uses language models and probabilistic reasoning to gradually build a model of the person's preferences.
The key idea is to
This is useful in applications where you want to tailor recommendations or decisions to an individual's unique preferences, like aligning AI agents with human values. By actively learning the person's preferences, the system can make better choices on their behalf.
The authors test this approach on both simulated data and real-world preference learning tasks, showing that it outperforms alternative methods. The active learning allows the system to zero in on a person's preferences more efficiently than passive observation alone.
Technical Explanation
The paper formulates active preference inference as a Bayesian optimization problem. The goal is to iteratively refine a probabilistic model of the user's latent preferences by selectively querying the user and incorporating their feedback.
At each iteration, the system generates a set of candidate options to present to the user. It then uses the current preference model to estimate the
The user's feedback is used to update the preference model using Bayesian inference. This allows the model to better capture the user's underlying preferences, which can then guide the selection of more informative queries in subsequent iterations.
The authors experiment with different language model architectures and acquisition functions for the Bayesian optimization process. They find that using a large pre-trained language model like GPT-3, combined with an information-theoretic acquisition function, leads to strong empirical performance on both synthetic and real-world preference learning tasks.
Critical Analysis
The paper presents a compelling approach to active preference inference that leverages language models and probabilistic reasoning. The authors demonstrate promising results, but there are a few potential limitations and areas for future work:
- The experiments are relatively small-scale, focusing on preference learning tasks with a limited number of options. It's unclear how well the method would scale to real-world scenarios with much larger option spaces.
- The user feedback is assumed to be binary (i.e., prefer or not prefer), which may oversimplify real-world preference expressions. Extending the method to handle more nuanced feedback could be an interesting direction.
- The paper does not address the potential for user manipulation or other ethical concerns that could arise from an AI system actively shaping a user's preferences. Further research is needed to ensure these methods are developed responsibly.
Overall, the paper makes a valuable contribution to the field of preference learning and user-centric AI. The active learning approach holds promise, but more work is needed to address the scalability, expressiveness, and ethical implications of this technology.
Conclusion
This paper presents a novel method for actively inferring user preferences using language models and probabilistic reasoning. By selectively querying users and incorporating their feedback, the system can build a more accurate model of their underlying preferences over time.
The authors demonstrate the effectiveness of their approach on both synthetic and real-world preference learning tasks, showing that it outperforms alternative methods. This work has important implications for applications where tailoring recommendations or decisions to individual preferences is crucial, such as aligning AI agents with human values.
While the paper makes a valuable contribution, there are also important avenues for future research to address scalability, expressiveness, and ethical considerations. Nonetheless, the active preference inference framework presented here represents an important step forward in building AI systems that can better understand and accommodate human preferences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Active Preference Inference using Language Models and Probabilistic Reasoning
Wasu Top Piriyakulkij, Volodymyr Kuleshov, Kevin Ellis
Actively inferring user preferences, for example by asking good questions, is important for any human-facing decision-making system. Active inference allows such systems to adapt and personalize themselves to nuanced individual preferences. To enable this ability for instruction-tuned large language models (LLMs), one may prompt them to ask users questions to infer their preferences, transforming the language models into more robust, interactive systems. However, out of the box, these models are not efficient at extracting preferences: the questions they generate are not informative, requiring a high number of user interactions and impeding the usability of the downstream system. In this work, we introduce an inference-time algorithm that helps LLMs quickly infer preferences by using more informative questions. Our algorithm uses a probabilistic model whose conditional distributions are defined by prompting an LLM, and returns questions that optimize expected entropy and expected model change. Results in a simplified interactive web shopping setting with real product items show that an LLM equipped with our entropy reduction algorithm outperforms baselines with the same underlying LLM on task performance while using fewer user interactions.
Read more6/27/2024

0
Deep Bayesian Active Learning for Preference Modeling in Large Language Models
Luckeciano C. Melo, Panagiotis Tigas, Alessandro Abate, Yarin Gal
Leveraging human preferences for steering the behavior of Large Language Models (LLMs) has demonstrated notable success in recent years. Nonetheless, data selection and labeling are still a bottleneck for these systems, particularly at large scale. Hence, selecting the most informative points for acquiring human feedback may considerably reduce the cost of preference labeling and unleash the further development of LLMs. Bayesian Active Learning provides a principled framework for addressing this challenge and has demonstrated remarkable success in diverse settings. However, previous attempts to employ it for Preference Modeling did not meet such expectations. In this work, we identify that naive epistemic uncertainty estimation leads to the acquisition of redundant samples. We address this by proposing the Bayesian Active Learner for Preference Modeling (BAL-PM), a novel stochastic acquisition policy that not only targets points of high epistemic uncertainty according to the preference model but also seeks to maximize the entropy of the acquired prompt distribution in the feature space spanned by the employed LLM. Notably, our experiments demonstrate that BAL-PM requires 33% to 68% fewer preference labels in two popular human preference datasets and exceeds previous stochastic Bayesian acquisition policies.
Read more6/17/2024

0
Active Preference Learning for Large Language Models
William Muldrew, Peter Hayes, Mingtian Zhang, David Barber
As large language models (LLMs) become more capable, fine-tuning techniques for aligning with human intent are increasingly important. A key consideration for aligning these models is how to most effectively use human resources, or model resources in the case where LLMs themselves are used as oracles. Reinforcement learning from Human or AI preferences (RLHF/RLAIF) is the most prominent example of such a technique, but is complex and often unstable. Direct Preference Optimization (DPO) has recently been proposed as a simpler and more stable alternative. In this work, we develop an active learning strategy for DPO to make better use of preference labels. We propose a practical acquisition function for prompt/completion pairs based on the predictive entropy of the language model and a measure of certainty of the implicit preference model optimized by DPO. We demonstrate how our approach improves both the rate of learning and final performance of fine-tuning on pairwise preference data.
Read more7/1/2024
0
Active Statistical Inference
Tijana Zrnic, Emmanuel J. Cand`es
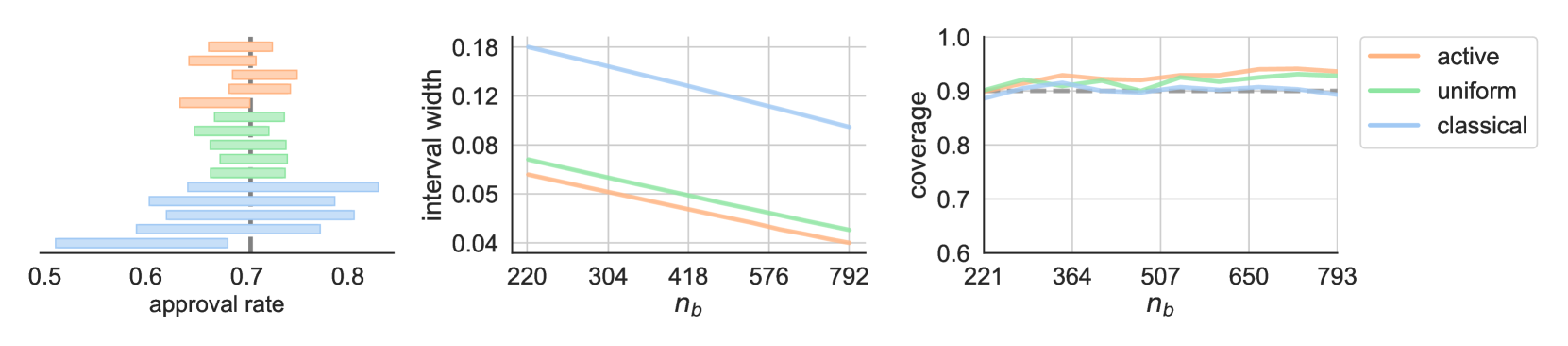
Inspired by the concept of active learning, we propose active inference$unicode{x2013}$a methodology for statistical inference with machine-learning-assisted data collection. Assuming a budget on the number of labels that can be collected, the methodology uses a machine learning model to identify which data points would be most beneficial to label, thus effectively utilizing the budget. It operates on a simple yet powerful intuition: prioritize the collection of labels for data points where the model exhibits uncertainty, and rely on the model's predictions where it is confident. Active inference constructs provably valid confidence intervals and hypothesis tests while leveraging any black-box machine learning model and handling any data distribution. The key point is that it achieves the same level of accuracy with far fewer samples than existing baselines relying on non-adaptively-collected data. This means that for the same number of collected samples, active inference enables smaller confidence intervals and more powerful p-values. We evaluate active inference on datasets from public opinion research, census analysis, and proteomics.
Read more5/30/2024