AlignZeg: Mitigating Objective Misalignment for Zero-shot Semantic Segmentation
2404.05667
0
0
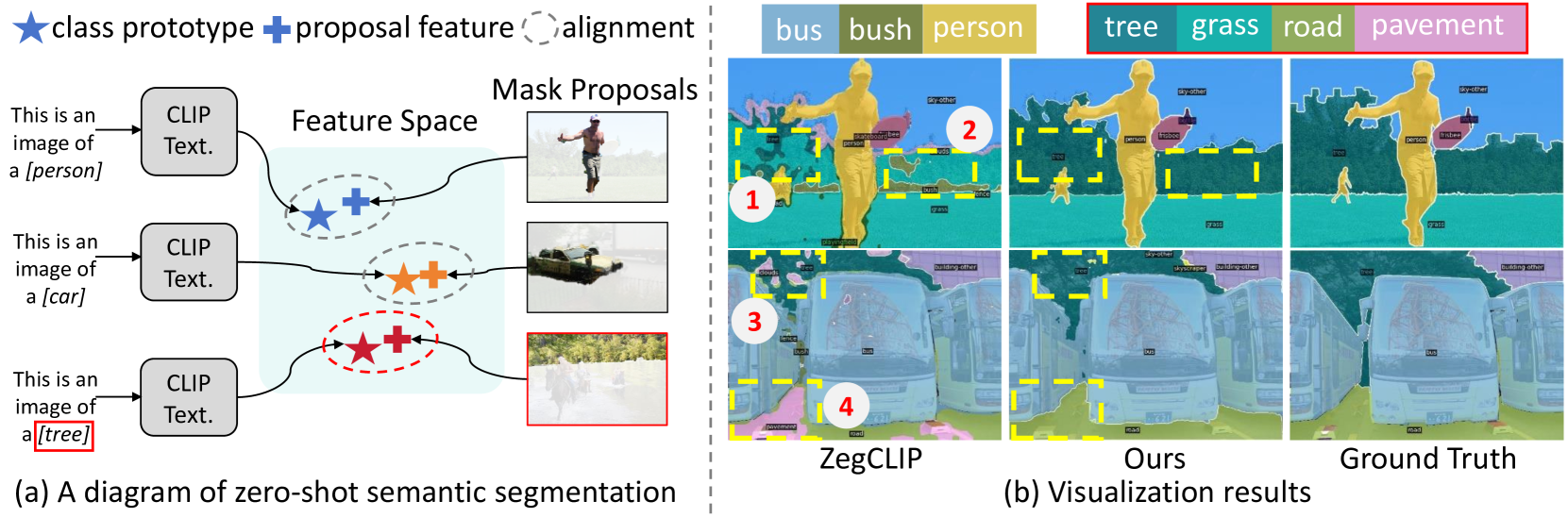
Abstract
A serious issue that harms the performance of zero-shot visual recognition is named objective misalignment, i.e., the learning objective prioritizes improving the recognition accuracy of seen classes rather than unseen classes, while the latter is the true target to pursue. This issue becomes more significant in zero-shot image segmentation because the stronger (i.e., pixel-level) supervision brings a larger gap between seen and unseen classes. To mitigate it, we propose a novel architecture named AlignZeg, which embodies a comprehensive improvement of the segmentation pipeline, including proposal extraction, classification, and correction, to better fit the goal of zero-shot segmentation. (1) Mutually-Refined Proposal Extraction. AlignZeg harnesses a mutual interaction between mask queries and visual features, facilitating detailed class-agnostic mask proposal extraction. (2) Generalization-Enhanced Proposal Classification. AlignZeg introduces synthetic data and incorporates multiple background prototypes to allocate a more generalizable feature space. (3) Predictive Bias Correction. During the inference stage, AlignZeg uses a class indicator to find potential unseen class proposals followed by a prediction postprocess to correct the prediction bias. Experiments demonstrate that AlignZeg markedly enhances zero-shot semantic segmentation, as shown by an average 3.8% increase in hIoU, primarily attributed to a 7.1% improvement in identifying unseen classes, and we further validate that the improvement comes from alleviating the objective misalignment issue.
Create account to get full access
Overview
• This paper introduces AlignZeg, a method to mitigate objective misalignment in zero-shot semantic segmentation tasks.
• Zero-shot semantic segmentation aims to segment images into semantic regions without any training data. This is a challenging problem due to the potential misalignment between the model's objectives and the desired segmentation output.
• AlignZeg addresses this by aligning the model's objective with the task of zero-shot segmentation through adversarial training and uncertainty-aware loss functions.
Plain English Explanation
• Zero-shot semantic segmentation is the task of dividing an image into different meaningful regions, such as sky, trees, roads, etc., without having any training examples for those specific categories.
• This is a difficult problem because the machine learning model may not be properly aligned to produce the desired segmentation outputs. In other words, the model's internal objectives may not match up with the goal of accurately segmenting the image.
• The AlignZeg method proposed in this paper aims to fix this misalignment. It does this by using adversarial training and specialized loss functions that encourage the model to focus on the right things when segmenting the image, even without any training data.
• This helps the model produce better zero-shot segmentation results, where it can accurately divide the image into the right semantic regions, even for categories it has never seen before.
Technical Explanation
• The key innovation in AlignZeg is the use of adversarial training and uncertainty-aware loss functions to align the model's objective with the zero-shot segmentation task.
• Specifically, they train an adversarial network to distinguish between the model's segmentation outputs and ground truth segmentation maps. This encourages the main segmentation model to produce outputs that are more aligned with the desired segmentation.
• Additionally, they introduce an uncertainty-aware loss function that penalizes the model for being overly confident about its predictions in regions where it is highly uncertain. This helps the model focus on making accurate predictions rather than just optimizing for a proxy objective.
• The paper evaluates AlignZeg on several zero-shot segmentation benchmarks and shows significant improvements over existing methods, particularly in challenging cases with complex scenes and novel categories.
Critical Analysis
• The paper provides a thorough evaluation of AlignZeg on multiple datasets, demonstrating its effectiveness in improving zero-shot semantic segmentation performance.
• However, the paper does not explore the model's robustness to different types of distribution shifts or its generalization to entirely new domains beyond the evaluated benchmarks. Further research is needed to understand the limitations and potential failure modes of this approach.
• Additionally, the computational overhead and training complexity of the adversarial and uncertainty-aware components could be a practical concern for real-world deployment, especially for resource-constrained applications. Exploring more efficient alternatives or approximations would be a valuable direction for future work.
Conclusion
• AlignZeg represents an important step forward in addressing the objective misalignment problem in zero-shot semantic segmentation, a challenging task with significant practical applications in areas like autonomous driving and robotic perception.
• By aligning the model's objective with the desired segmentation outputs through adversarial training and uncertainty-aware loss functions, the paper demonstrates substantial performance improvements over existing zero-shot segmentation methods.
• While further research is needed to fully understand the strengths and limitations of this approach, AlignZeg shows great promise as a powerful technique for enabling robust and accurate zero-shot segmentation in complex real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Cascade-CLIP: Cascaded Vision-Language Embeddings Alignment for Zero-Shot Semantic Segmentation
Yunheng Li, ZhongYu Li, Quansheng Zeng, Qibin Hou, Ming-Ming Cheng
0
0
Pre-trained vision-language models, e.g., CLIP, have been successfully applied to zero-shot semantic segmentation. Existing CLIP-based approaches primarily utilize visual features from the last layer to align with text embeddings, while they neglect the crucial information in intermediate layers that contain rich object details. However, we find that directly aggregating the multi-level visual features weakens the zero-shot ability for novel classes. The large differences between the visual features from different layers make these features hard to align well with the text embeddings. We resolve this problem by introducing a series of independent decoders to align the multi-level visual features with the text embeddings in a cascaded way, forming a novel but simple framework named Cascade-CLIP. Our Cascade-CLIP is flexible and can be easily applied to existing zero-shot semantic segmentation methods. Experimental results show that our simple Cascade-CLIP achieves superior zero-shot performance on segmentation benchmarks, like COCO-Stuff, Pascal-VOC, and Pascal-Context. Our code is available at: https://github.com/HVision-NKU/Cascade-CLIP
6/7/2024

A Simple Framework for Open-Vocabulary Zero-Shot Segmentation
Thomas Stegmuller, Tim Lebailly, Nikola Dukic, Behzad Bozorgtabar, Jean-Philippe Thiran, Tinne Tuytelaars
0
0
Zero-shot classification capabilities naturally arise in models trained within a vision-language contrastive framework. Despite their classification prowess, these models struggle in dense tasks like zero-shot open-vocabulary segmentation. This deficiency is often attributed to the absence of localization cues in captions and the intertwined nature of the learning process, which encompasses both image representation learning and cross-modality alignment. To tackle these issues, we propose SimZSS, a Simple framework for open-vocabulary Zero-Shot Segmentation. The method is founded on two key principles: i) leveraging frozen vision-only models that exhibit spatial awareness while exclusively aligning the text encoder and ii) exploiting the discrete nature of text and linguistic knowledge to pinpoint local concepts within captions. By capitalizing on the quality of the visual representations, our method requires only image-caption pairs datasets and adapts to both small curated and large-scale noisy datasets. When trained on COCO Captions across 8 GPUs, SimZSS achieves state-of-the-art results on 7 out of 8 benchmark datasets in less than 15 minutes.
6/26/2024
⛏️
Tuning-free Universally-Supervised Semantic Segmentation
Xiaobo Yang, Xiaojin Gong
0
0
This work presents a tuning-free semantic segmentation framework based on classifying SAM masks by CLIP, which is universally applicable to various types of supervision. Initially, we utilize CLIP's zero-shot classification ability to generate pseudo-labels or perform open-vocabulary segmentation. However, the misalignment between mask and CLIP text embeddings leads to suboptimal results. To address this issue, we propose discrimination-bias aligned CLIP to closely align mask and text embedding, offering an overhead-free performance gain. We then construct a global-local consistent classifier to classify SAM masks, which reveals the intrinsic structure of high-quality embeddings produced by DBA-CLIP and demonstrates robustness against noisy pseudo-labels. Extensive experiments validate the efficiency and effectiveness of our method, and we achieve state-of-the-art (SOTA) or competitive performance across various datasets and supervision types.
5/24/2024

Progressive Semantic-Guided Vision Transformer for Zero-Shot Learning
Shiming Chen, Wenjin Hou, Salman Khan, Fahad Shahbaz Khan
0
0
Zero-shot learning (ZSL) recognizes the unseen classes by conducting visual-semantic interactions to transfer semantic knowledge from seen classes to unseen ones, supported by semantic information (e.g., attributes). However, existing ZSL methods simply extract visual features using a pre-trained network backbone (i.e., CNN or ViT), which fail to learn matched visual-semantic correspondences for representing semantic-related visual features as lacking of the guidance of semantic information, resulting in undesirable visual-semantic interactions. To tackle this issue, we propose a progressive semantic-guided vision transformer for zero-shot learning (dubbed ZSLViT). ZSLViT mainly considers two properties in the whole network: i) discover the semantic-related visual representations explicitly, and ii) discard the semantic-unrelated visual information. Specifically, we first introduce semantic-embedded token learning to improve the visual-semantic correspondences via semantic enhancement and discover the semantic-related visual tokens explicitly with semantic-guided token attention. Then, we fuse low semantic-visual correspondence visual tokens to discard the semantic-unrelated visual information for visual enhancement. These two operations are integrated into various encoders to progressively learn semantic-related visual representations for accurate visual-semantic interactions in ZSL. The extensive experiments show that our ZSLViT achieves significant performance gains on three popular benchmark datasets, i.e., CUB, SUN, and AWA2.
4/12/2024