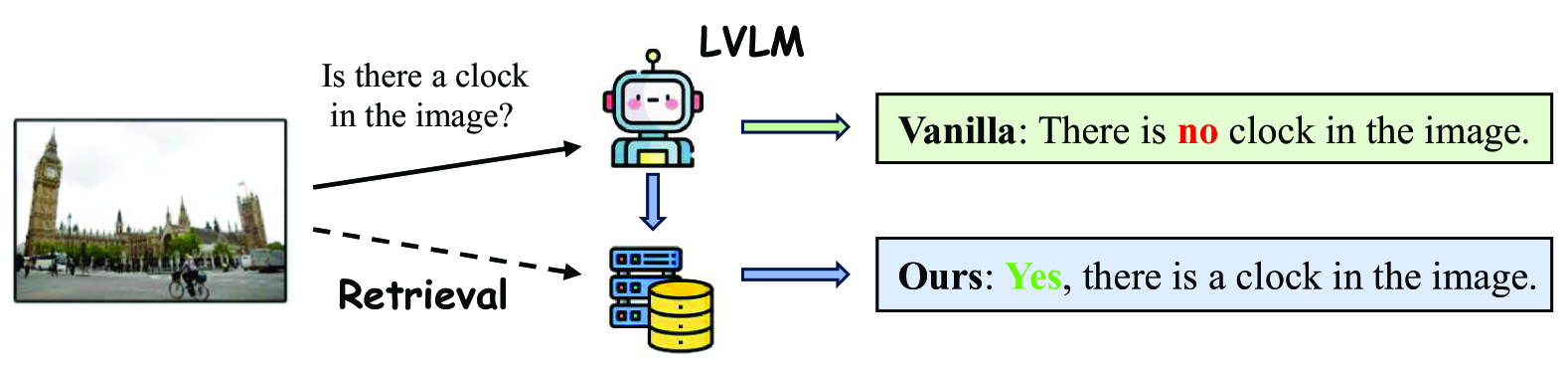
Alleviating Hallucination in Large Vision-Language Models with Active Retrieval Augmentation

0
Sign in to get full access
Overview
- This paper proposes a method called "Active Retrieval Augmentation" to alleviate hallucination in large vision-language models.
- Hallucination refers to the generation of content that is not grounded in the input data.
- The authors show that their approach can reduce hallucination on a variety of benchmarks.
Plain English Explanation
The paper focuses on a problem called "hallucination" that can occur in large vision-language models. These models are trained to understand and generate text based on visual inputs, but sometimes they can produce content that isn't actually supported by the original images.
To address this, the researchers developed a technique called "Active Retrieval Augmentation." The key idea is to augment the model's training process by actively retrieving relevant information from a large knowledge base and incorporating that into the model's inputs. This helps the model stay grounded in actual data, rather than hallucinating new information.
The paper demonstrates that this approach can effectively reduce hallucination on several standard benchmarks. By retrieving relevant information, the model is less likely to generate unsupported or inaccurate content.
Technical Explanation
The authors propose an "Active Retrieval Augmentation" (ARA) method to mitigate hallucination in large vision-language models. ARA works by dynamically retrieving relevant information from a large knowledge base and incorporating that into the model's inputs during training.
Specifically, the model first encodes the input image and the corresponding caption. It then uses this encoding to retrieve a set of relevant passages from a knowledge base. These passages are then concatenated with the original caption and fed into the model for training.
The authors evaluate their approach on several hallucination-focused benchmarks, including mitigating entity-level hallucination, mitigating multilingual hallucination, and detecting and mitigating hallucination. They show that ARA can significantly reduce hallucination on these tasks compared to baseline models.
Critical Analysis
The paper provides a compelling approach to addressing the important problem of hallucination in large vision-language models. The authors demonstrate the effectiveness of their ARA method on several relevant benchmarks, which is a strength of the work.
However, the paper does not fully explore the limitations of the ARA approach. For example, it is unclear how the method would scale to extremely large knowledge bases or how it would perform on more open-ended generation tasks beyond the specific benchmarks considered.
Additionally, the paper does not discuss potential biases or artifacts that could be introduced by the retrieval process. It would be worth investigating whether the retrieved passages inadvertently encode societal biases or other undesirable properties.
Further research could also examine the interpretability and transparency of the ARA approach. Understanding why the model makes certain decisions based on the retrieved information could be valuable for building trust and ensuring the model's outputs are reliable.
Conclusion
This paper presents an effective technique called "Active Retrieval Augmentation" to mitigate hallucination in large vision-language models. By dynamically incorporating relevant information from a knowledge base, the model is better able to stay grounded in the input data and avoid generating unsupported content.
The authors demonstrate the benefits of their approach on several hallucination-focused benchmarks, showing significant reductions in hallucination compared to baseline models. While the paper has some limitations, it represents an important step forward in addressing a crucial challenge in the development of reliable and trustworthy large-scale vision-language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Alleviating Hallucination in Large Vision-Language Models with Active Retrieval Augmentation
Xiaoye Qu, Qiyuan Chen, Wei Wei, Jishuo Sun, Jianfeng Dong
Despite the remarkable ability of large vision-language models (LVLMs) in image comprehension, these models frequently generate plausible yet factually incorrect responses, a phenomenon known as hallucination.Recently, in large language models (LLMs), augmenting LLMs by retrieving information from external knowledge resources has been proven as a promising solution to mitigate hallucinations.However, the retrieval augmentation in LVLM significantly lags behind the widespread applications of LVLM. Moreover, when transferred to augmenting LVLMs, sometimes the hallucination degree of the model is even exacerbated.Motivated by the research gap and counter-intuitive phenomenon, we introduce a novel framework, the Active Retrieval-Augmented large vision-language model (ARA), specifically designed to address hallucinations by incorporating three critical dimensions: (i) dissecting the retrieval targets based on the inherent hierarchical structures of images. (ii) pinpointing the most effective retrieval methods and filtering out the reliable retrieval results. (iii) timing the retrieval process to coincide with episodes of low certainty, while circumventing unnecessary retrieval during periods of high certainty. To assess the capability of our proposed ARA model in reducing hallucination, we employ three widely used LVLM models (LLaVA-1.5, Qwen-VL, and mPLUG-Owl2) across four benchmarks. Our empirical observations suggest that by utilizing fitting retrieval mechanisms and timing the retrieval judiciously, we can effectively mitigate the hallucination problem. We hope that this study can provide deeper insights into how to adapt the retrieval augmentation to LVLMs for reducing hallucinations with more effective retrieval and minimal retrieval occurrences.
Read more8/2/2024

0
A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, Wei Peng
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
Read more5/7/2024
0
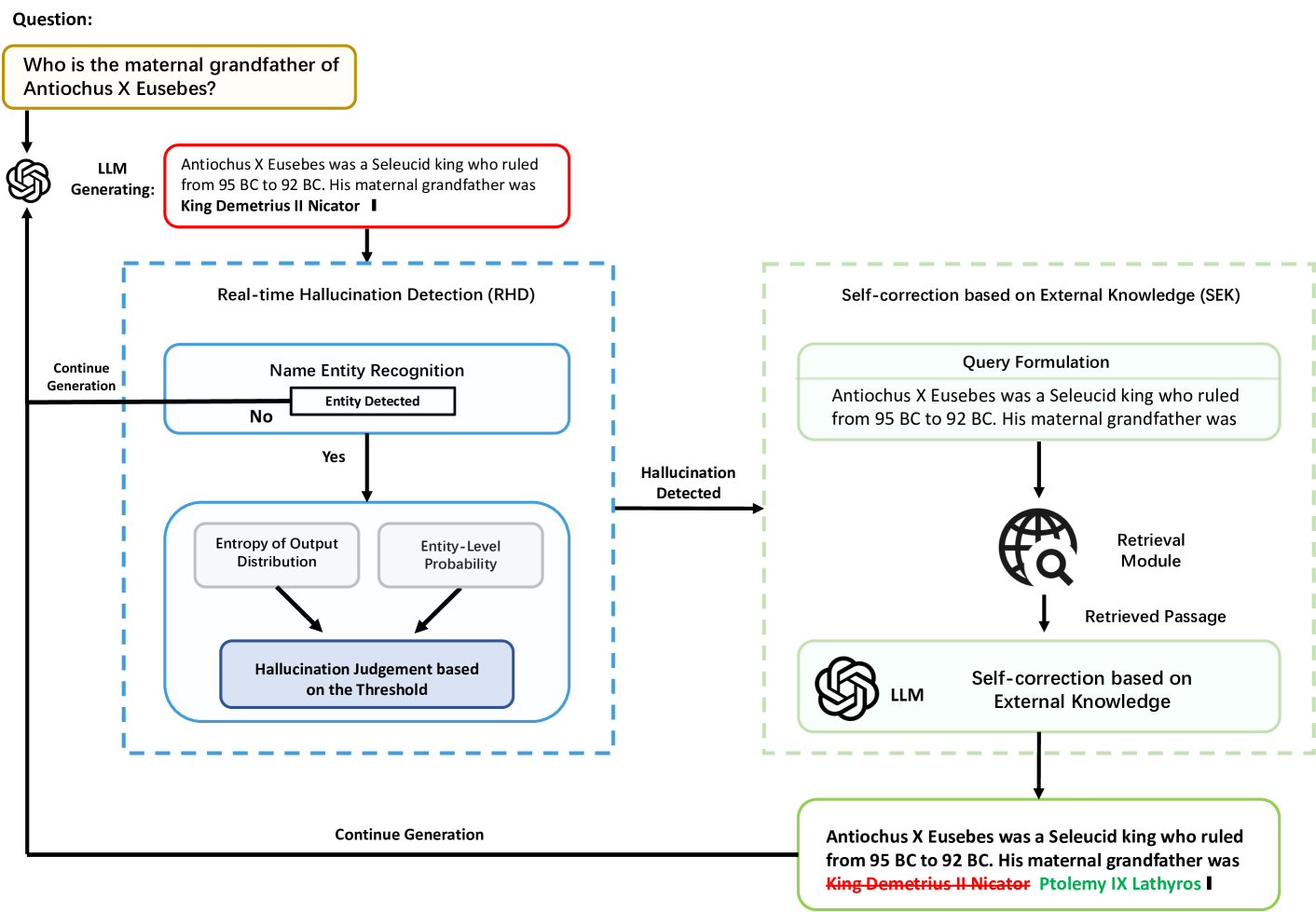
Mitigating Entity-Level Hallucination in Large Language Models
Weihang Su, Yichen Tang, Qingyao Ai, Changyue Wang, Zhijing Wu, Yiqun Liu
The emergence of Large Language Models (LLMs) has revolutionized how users access information, shifting from traditional search engines to direct question-and-answer interactions with LLMs. However, the widespread adoption of LLMs has revealed a significant challenge known as hallucination, wherein LLMs generate coherent yet factually inaccurate responses. This hallucination phenomenon has led to users' distrust in information retrieval systems based on LLMs. To tackle this challenge, this paper proposes Dynamic Retrieval Augmentation based on hallucination Detection (DRAD) as a novel method to detect and mitigate hallucinations in LLMs. DRAD improves upon traditional retrieval augmentation by dynamically adapting the retrieval process based on real-time hallucination detection. It features two main components: Real-time Hallucination Detection (RHD) for identifying potential hallucinations without external models, and Self-correction based on External Knowledge (SEK) for correcting these errors using external knowledge. Experiment results show that DRAD demonstrates superior performance in both detecting and mitigating hallucinations in LLMs. All of our code and data are open-sourced at https://github.com/oneal2000/EntityHallucination.
Read more7/23/2024

0
Mitigating Multilingual Hallucination in Large Vision-Language Models
Xiaoye Qu, Mingyang Song, Wei Wei, Jianfeng Dong, Yu Cheng
While Large Vision-Language Models (LVLMs) have exhibited remarkable capabilities across a wide range of tasks, they suffer from hallucination problems, where models generate plausible yet incorrect answers given the input image-query pair. This hallucination phenomenon is even more severe when querying the image in non-English languages, while existing methods for mitigating hallucinations in LVLMs only consider the English scenarios. In this paper, we make the first attempt to mitigate this important multilingual hallucination in LVLMs. With thorough experiment analysis, we found that multilingual hallucination in LVLMs is a systemic problem that could arise from deficiencies in multilingual capabilities or inadequate multimodal abilities. To this end, we propose a two-stage Multilingual Hallucination Removal (MHR) framework for LVLMs, aiming to improve resistance to hallucination for both high-resource and low-resource languages. Instead of relying on the intricate manual annotations of multilingual resources, we fully leverage the inherent capabilities of the LVLM and propose a novel cross-lingual alignment method, which generates multiple responses for each image-query input and then identifies the hallucination-aware pairs for each language. These data pairs are finally used for direct preference optimization to prompt the LVLMs to favor non-hallucinating responses. Experimental results show that our MHR achieves a substantial reduction in hallucination generation for LVLMs. Notably, on our extended multilingual POPE benchmark, our framework delivers an average increase of 19.0% in accuracy across 13 different languages. Our code and model weights are available at https://github.com/ssmisya/MHR
Read more8/2/2024