Alt-MoE: Multimodal Alignment via Alternating Optimization of Multi-directional MoE with Unimodal Models

0
Sign in to get full access
Overview
- The paper proposes a new method called "Alt-MoE" for multimodal alignment using a multi-directional Mixture of Experts (MoE) approach with unimodal models.
- It introduces an alternating optimization technique to jointly train the multimodal and unimodal models.
- The key idea is to leverage the strengths of both multimodal and unimodal models to achieve better alignment between different modalities.
Plain English Explanation
The paper presents a new technique called "Alt-MoE" that aims to improve the alignment between different types of data, such as text, images, and videos. This is an important problem in the field of multimodal learning, where the goal is to build models that can understand and work with multiple forms of data.
The key insight behind Alt-MoE is to use a mixture of experts (MoE) approach, where different "experts" (or sub-models) are responsible for different parts of the input data. This allows the model to specialize and capture the unique characteristics of each modality.
Additionally, Alt-MoE incorporates unimodal models (models trained on a single type of data) and optimizes them in an alternating fashion with the multimodal MoE model. This helps to ensure that the multimodal model can effectively align the different modalities by leveraging the strengths of the unimodal models.
The authors demonstrate the effectiveness of Alt-MoE on several multimodal tasks, such as image-text retrieval and visual question answering. The results show that Alt-MoE outperforms existing multimodal alignment methods, highlighting the potential of this novel approach.
Technical Explanation
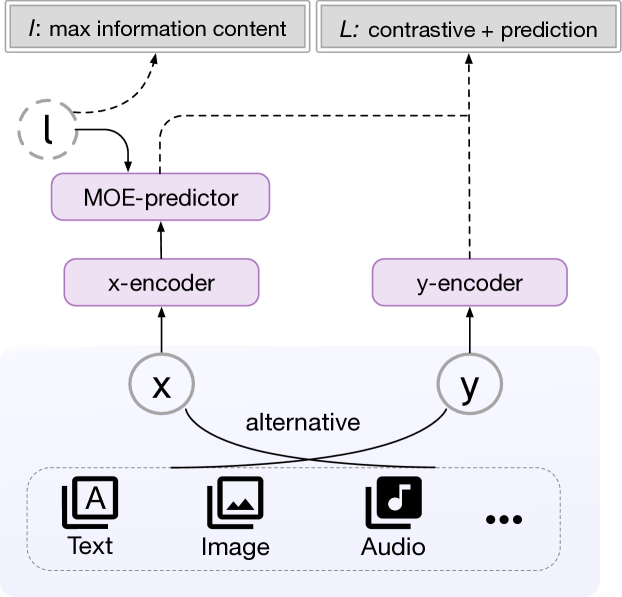
The core of the Alt-MoE method is a multi-directional MoE architecture, which consists of multiple modality-specific expert networks and a shared gating network. The expert networks are trained to specialize in different modalities, while the gating network learns to dynamically route the input data to the appropriate experts.
The training process of Alt-MoE involves an alternating optimization scheme. In each iteration, the method first updates the multimodal MoE model by optimizing the alignment between different modalities. It then updates the unimodal models by training them on their respective modalities. This alternating approach allows the multimodal model to benefit from the strengths of the unimodal models, improving the overall alignment performance.
The authors conduct experiments on several multimodal benchmarks, including image-text retrieval and visual question answering tasks. The results demonstrate that Alt-MoE outperforms state-of-the-art multimodal alignment methods, highlighting the effectiveness of the proposed approach.
Critical Analysis
The paper presents a novel and promising approach to multimodal alignment using a multi-directional MoE architecture and alternating optimization. However, there are a few potential limitations and areas for further research:
-
Scalability: While the authors demonstrate the effectiveness of Alt-MoE on several benchmarks, it remains to be seen how the method scales to larger and more diverse multimodal datasets, especially with the increasing complexity of modern multimodal tasks.
-
Computational Overhead: The alternating optimization scheme may introduce additional computational overhead compared to single-stage multimodal alignment methods. The authors could explore ways to optimize the training process or reduce the complexity of the overall architecture.
-
Interpretability: The multi-directional MoE architecture and alternating optimization process can be quite complex. It would be valuable for the authors to investigate ways to improve the interpretability of the model and the insights it provides into the multimodal alignment process.
-
Generalization: The paper focuses on specific multimodal tasks, such as image-text retrieval and visual question answering. Further research is needed to understand how well the Alt-MoE approach generalizes to a broader range of multimodal applications and domains.
Overall, the Alt-MoE method presents an innovative approach to multimodal alignment that leverages the strengths of both multimodal and unimodal models. The results are promising, and the authors have identified several interesting directions for future research to address the potential limitations and further advance the field of multimodal learning.
Conclusion
The Alt-MoE paper introduces a novel technique for multimodal alignment that combines a multi-directional MoE architecture with an alternating optimization scheme. By jointly training the multimodal and unimodal models, the method is able to leverage the strengths of both approaches to achieve better alignment between different data modalities.
The key contributions of this work include the multi-directional MoE design, the alternating optimization process, and the demonstrated improvements over state-of-the-art multimodal alignment methods. While the paper highlights several promising results, there are also opportunities for further research to address potential limitations, such as scalability, computational overhead, interpretability, and generalization.
Overall, the Alt-MoE approach represents an important step forward in the field of multimodal learning, and the insights and techniques presented in this paper could inspire future advancements in the alignment and integration of diverse data sources.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Alt-MoE: Multimodal Alignment via Alternating Optimization of Multi-directional MoE with Unimodal Models
Hongyang Lei, Xiaolong Cheng, Dan Wang, Qi Qin, Huazhen Huang, Yetao Wu, Qingqing Gu, Zhonglin Jiang, Yong Chen, Luo Ji
Recent Large Multi-Modal Models (LMMs) have made significant advancements in multi-modal alignment by employing lightweight connection modules to facilitate the representation and fusion of knowledge from existing pre-trained uni-modal models. However, these methods still rely on modality-specific and direction-specific connectors, leading to compartmentalized knowledge representations and reduced computational efficiency, which limits the model's ability to form unified multi-modal representations. To address these issues, we introduce a novel training framework, Alt-MoE, which employs the Mixture of Experts (MoE) as a unified multi-directional connector across modalities, and employs a multi-step sequential alternating unidirectional alignment strategy, which converges to bidirectional alignment over iterations. The extensive empirical studies revealed the following key points: 1) Alt-MoE achieves competitive results by integrating diverse knowledge representations from uni-modal models. This approach seamlessly fuses the specialized expertise of existing high-performance uni-modal models, effectively synthesizing their domain-specific knowledge into a cohesive multi-modal representation. 2) Alt-MoE efficiently scales to new tasks and modalities without altering its model architecture or training strategy. Furthermore, Alt-MoE operates in latent space, supporting vector pre-storage and real-time retrieval via lightweight multi-directional MoE, thereby facilitating massive data processing. Our methodology has been validated on several well-performing uni-modal models (LLAMA3, Qwen2, and DINOv2), achieving competitive results on a wide range of downstream tasks and datasets.
Read more9/11/2024
0
Uni-MoE: Scaling Unified Multimodal LLMs with Mixture of Experts
Yunxin Li, Shenyuan Jiang, Baotian Hu, Longyue Wang, Wanqi Zhong, Wenhan Luo, Lin Ma, Min Zhang
Recent advancements in Multimodal Large Language Models (MLLMs) underscore the significance of scalable models and data to boost performance, yet this often incurs substantial computational costs. Although the Mixture of Experts (MoE) architecture has been employed to efficiently scale large language and image-text models, these efforts typically involve fewer experts and limited modalities. To address this, our work presents the pioneering attempt to develop a unified MLLM with the MoE architecture, named Uni-MoE that can handle a wide array of modalities. Specifically, it features modality-specific encoders with connectors for a unified multimodal representation. We also implement a sparse MoE architecture within the LLMs to enable efficient training and inference through modality-level data parallelism and expert-level model parallelism. To enhance the multi-expert collaboration and generalization, we present a progressive training strategy: 1) Cross-modality alignment using various connectors with different cross-modality data, 2) Training modality-specific experts with cross-modality instruction data to activate experts' preferences, and 3) Tuning the Uni-MoE framework utilizing Low-Rank Adaptation (LoRA) on mixed multimodal instruction data. We evaluate the instruction-tuned Uni-MoE on a comprehensive set of multimodal datasets. The extensive experimental results demonstrate Uni-MoE's principal advantage of significantly reducing performance bias in handling mixed multimodal datasets, alongside improved multi-expert collaboration and generalization. Our findings highlight the substantial potential of MoE frameworks in advancing MLLMs and the code is available at https://github.com/HITsz-TMG/UMOE-Scaling-Unified-Multimodal-LLMs.
Read more5/21/2024
⚙️
0
New!MMoE: Enhancing Multimodal Models with Mixtures of Multimodal Interaction Experts
Haofei Yu, Zhengyang Qi, Lawrence Jang, Ruslan Salakhutdinov, Louis-Philippe Morency, Paul Pu Liang
Advances in multimodal models have greatly improved how interactions relevant to various tasks are modeled. Today's multimodal models mainly focus on the correspondence between images and text, using this for tasks like image-text matching. However, this covers only a subset of real-world interactions. Novel interactions, such as sarcasm expressed through opposing spoken words and gestures or humor expressed through utterances and tone of voice, remain challenging. In this paper, we introduce an approach to enhance multimodal models, which we call Multimodal Mixtures of Experts (MMoE). The key idea in MMoE is to train separate expert models for each type of multimodal interaction, such as redundancy present in both modalities, uniqueness in one modality, or synergy that emerges when both modalities are fused. On a sarcasm detection task (MUStARD) and a humor detection task (URFUNNY), we obtain new state-of-the-art results. MMoE is also able to be applied to various types of models to gain improvement.
Read more9/24/2024
💬
0
Diversifying the Mixture-of-Experts Representation for Language Models with Orthogonal Optimizer
Boan Liu, Liang Ding, Li Shen, Keqin Peng, Yu Cao, Dazhao Cheng, Dacheng Tao
The Mixture of Experts (MoE) has emerged as a highly successful technique in deep learning, based on the principle of divide-and-conquer to maximize model capacity without significant additional computational cost. Even in the era of large-scale language models (LLMs), MoE continues to play a crucial role, as some researchers have indicated that GPT-4 adopts the MoE structure to ensure diverse inference results. However, MoE is susceptible to performance degeneracy, particularly evident in the issues of imbalance and homogeneous representation among experts. While previous studies have extensively addressed the problem of imbalance, the challenge of homogeneous representation remains unresolved. In this study, we shed light on the homogeneous representation problem, wherein experts in the MoE fail to specialize and lack diversity, leading to frustratingly high similarities in their representations (up to 99% in a well-performed MoE model). This problem restricts the expressive power of the MoE and, we argue, contradicts its original intention. To tackle this issue, we propose a straightforward yet highly effective solution: OMoE, an orthogonal expert optimizer. Additionally, we introduce an alternating training strategy that encourages each expert to update in a direction orthogonal to the subspace spanned by other experts. Our algorithm facilitates MoE training in two key ways: firstly, it explicitly enhances representation diversity, and secondly, it implicitly fosters interaction between experts during orthogonal weights computation. Through extensive experiments, we demonstrate that our proposed optimization algorithm significantly improves the performance of fine-tuning the MoE model on the GLUE benchmark, SuperGLUE benchmark, question-answering task, and name entity recognition tasks.
Read more9/2/2024