AMOSL: Adaptive Modality-wise Structure Learning in Multi-view Graph Neural Networks For Enhanced Unified Representation

0
🧠
Sign in to get full access
Overview
- Multi-view Graph Neural Networks (MVGNNs) are powerful tools for learning object representations from diverse data modalities.
- However, existing MVGNN methods assume identical local topology structures across modalities, which doesn't reflect real-world discrepancies.
- This leads to challenges in modality fusion and representation denoising.
Plain English Explanation
MVGNNs are machine learning models that can take in different types of data, like images and text, to learn better representations of objects. This is useful for tasks like predicting molecular properties or adapting to different vision tasks.
However, the current MVGNN methods assume that the underlying structure, or connections between the data points, is the same across all the different data types. In reality, this is often not the case - the connections between data points can be quite different depending on the type of data.
This mismatch in data structures makes it challenging for MVGNNs to effectively combine the information from the different data types and remove noise or irrelevant details from the final representations.
Technical Explanation
To address these limitations, the researchers propose a new method called Adaptive Modality-wise Structure Learning (AMoSL). AMoSL captures the correspondences between the node connections (the local topology) across the different data modalities using an optimization technique called optimal transport.
AMoSL then jointly learns the graph embeddings, which are the learned representations of the objects, along with the modality-specific structures. This allows the model to adapt to the unique structure of each data type.
To enable efficient end-to-end training of this complex optimization problem, the researchers develop an efficient solution. Additionally, AMoSL can further adapt to the specific downstream task through unsupervised learning on the inter-modality distances.
Critical Analysis
The paper provides a novel solution to an important problem in MVGNN methods. By allowing the model to learn modality-specific structures, it can better capture the nuances in the data and improve the final object representations.
However, the proposed optimization approach may be computationally intensive, which could limit its scalability to very large datasets. Additionally, the unsupervised adaptation to downstream tasks may not always be sufficient, and some supervised fine-tuning may still be necessary.
It would also be interesting to see how AMoSL performs on a wider range of tasks and datasets, beyond just graph classification, to better understand its broader applicability and limitations.
Conclusion
The AMoSL method proposed in this paper represents an important step forward in improving multimodal learning by enabling MVGNNs to better handle real-world discrepancies in data structures across modalities. This can lead to more accurate and robust object representations, with potential applications in scaling unified multimodal language models and other multimodal learning tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
AMOSL: Adaptive Modality-wise Structure Learning in Multi-view Graph Neural Networks For Enhanced Unified Representation
Peiyu Liang, Hongchang Gao, Xubin He
While Multi-view Graph Neural Networks (MVGNNs) excel at leveraging diverse modalities for learning object representation, existing methods assume identical local topology structures across modalities that overlook real-world discrepancies. This leads MVGNNs straggles in modality fusion and representations denoising. To address these issues, we propose adaptive modality-wise structure learning (AMoSL). AMoSL captures node correspondences between modalities via optimal transport, and jointly learning with graph embedding. To enable efficient end-to-end training, we employ an efficient solution for the resulting complex bilevel optimization problem. Furthermore, AMoSL adapts to downstream tasks through unsupervised learning on inter-modality distances. The effectiveness of AMoSL is demonstrated by its ability to train more accurate graph classifiers on six benchmark datasets.
Read more6/5/2024

0
Multi-view Graph Structural Representation Learning via Graph Coarsening
Xiaorui Qi, Qijie Bai, Yanlong Wen, Haiwei Zhang, Xiaojie Yuan
Graph Transformers (GTs) have made remarkable achievements in graph-level tasks. However, most existing works regard graph structures as a form of guidance or bias for enhancing node representations, which focuses on node-central perspectives and lacks explicit representations of edges and structures. One natural question is, can we treat graph structures node-like as a whole to learn high-level features? Through experimental analysis, we explore the feasibility of this assumption. Based on our findings, we propose a novel multi-view graph representation learning model via structure-aware searching and coarsening (GRLsc) on GT architecture for graph classification. Specifically, we build three unique views, original, coarsening, and conversion, to learn a thorough structural representation. We compress loops and cliques via hierarchical heuristic graph coarsening and restrict them with well-designed constraints, which builds the coarsening view to learn high-level interactions between structures. We also introduce line graphs for edge embeddings and switch to edge-central perspective to construct the conversion view. Experiments on eight real-world datasets demonstrate the improvements of GRLsc over 28 baselines from various architectures.
Read more7/26/2024
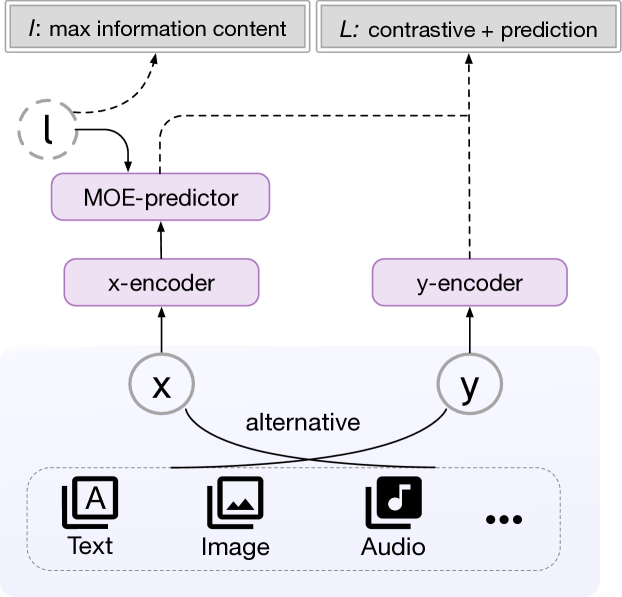
0
Alt-MoE: Multimodal Alignment via Alternating Optimization of Multi-directional MoE with Unimodal Models
Hongyang Lei, Xiaolong Cheng, Dan Wang, Qi Qin, Huazhen Huang, Yetao Wu, Qingqing Gu, Zhonglin Jiang, Yong Chen, Luo Ji
Recent Large Multi-Modal Models (LMMs) have made significant advancements in multi-modal alignment by employing lightweight connection modules to facilitate the representation and fusion of knowledge from existing pre-trained uni-modal models. However, these methods still rely on modality-specific and direction-specific connectors, leading to compartmentalized knowledge representations and reduced computational efficiency, which limits the model's ability to form unified multi-modal representations. To address these issues, we introduce a novel training framework, Alt-MoE, which employs the Mixture of Experts (MoE) as a unified multi-directional connector across modalities, and employs a multi-step sequential alternating unidirectional alignment strategy, which converges to bidirectional alignment over iterations. The extensive empirical studies revealed the following key points: 1) Alt-MoE achieves competitive results by integrating diverse knowledge representations from uni-modal models. This approach seamlessly fuses the specialized expertise of existing high-performance uni-modal models, effectively synthesizing their domain-specific knowledge into a cohesive multi-modal representation. 2) Alt-MoE efficiently scales to new tasks and modalities without altering its model architecture or training strategy. Furthermore, Alt-MoE operates in latent space, supporting vector pre-storage and real-time retrieval via lightweight multi-directional MoE, thereby facilitating massive data processing. Our methodology has been validated on several well-performing uni-modal models (LLAMA3, Qwen2, and DINOv2), achieving competitive results on a wide range of downstream tasks and datasets.
Read more9/11/2024

0
Exploring Graph Structure Comprehension Ability of Multimodal Large Language Models: Case Studies
Zhiqiang Zhong, Davide Mottin
Large Language Models (LLMs) have shown remarkable capabilities in processing various data structures, including graphs. While previous research has focused on developing textual encoding methods for graph representation, the emergence of multimodal LLMs presents a new frontier for graph comprehension. These advanced models, capable of processing both text and images, offer potential improvements in graph understanding by incorporating visual representations alongside traditional textual data. This study investigates the impact of graph visualisations on LLM performance across a range of benchmark tasks at node, edge, and graph levels. Our experiments compare the effectiveness of multimodal approaches against purely textual graph representations. The results provide valuable insights into both the potential and limitations of leveraging visual graph modalities to enhance LLMs' graph structure comprehension abilities.
Read more9/16/2024