ANAH-v2: Scaling Analytical Hallucination Annotation of Large Language Models

0
Sign in to get full access
Overview
- ANAH-v2 is a system for scaling the annotation of analytical hallucinations in large language models.
- Analytical hallucinations are model outputs that appear plausible but contain factual errors or logical inconsistencies.
- ANAH-v2 aims to streamline the process of identifying these issues at scale.
Plain English Explanation
ANAH-v2 is a tool designed to help researchers and developers better understand the behavior of large language models. These models are incredibly powerful, but they can sometimes produce outputs that seem convincing but are actually incorrect or illogical. These issues are known as "analytical hallucinations."
The ANAH-v2 system provides a way to efficiently identify and annotate these hallucinations. This is important because it allows researchers to understand the limitations of language models and work on improving them. By scaling up the annotation process, ANAH-v2 makes it easier to study hallucinations across a wide range of model outputs.
The key idea behind ANAH-v2 is to break down the annotation task into smaller, more manageable steps. This includes automatically detecting potential hallucinations, presenting them to human annotators, and then consolidating the results into a comprehensive dataset. This streamlined approach helps researchers gather more insights about language model behavior without getting bogged down in the tedious aspects of the annotation process.
Technical Explanation
ANAH-v2 builds on the original ANAH system by introducing several improvements to scale the annotation of analytical hallucinations in large language models.
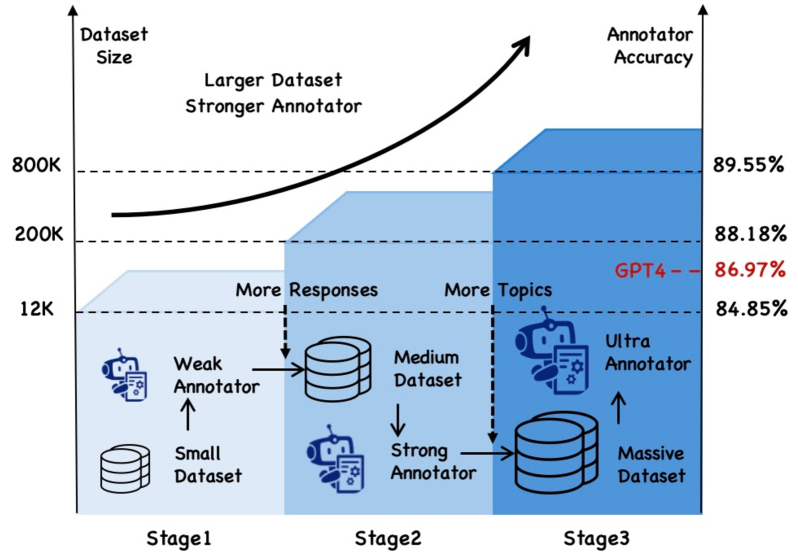
One key innovation is the use of a two-stage annotation pipeline. First, a machine learning model is used to automatically detect potential hallucinations in model outputs. These candidates are then presented to human annotators, who provide final judgments on whether the output is hallucinated or not.
The researchers also developed a set of specialized annotation guidelines and tools to streamline the human annotation process. This includes features like dynamic highlighting of suspicious text and integration with the Anthropic Cooperative AI platform for distributed annotation.
Additionally, ANAH-v2 introduces a novel hallucination taxonomy, which categorizes different types of hallucinations (e.g., factual errors, logical inconsistencies) to provide more nuanced insights. The system also generates detailed metadata about each annotated output, such as the specific model used and the context in which the output was generated.
Overall, the key technical contributions of ANAH-v2 are the two-stage annotation pipeline, the specialized annotation tooling, and the hallucination taxonomy. These innovations enable the system to scale the annotation of analytical hallucinations much more effectively than previous approaches.
Critical Analysis
The ANAH-v2 paper demonstrates a well-designed and comprehensive system for annotating analytical hallucinations in large language models. The two-stage approach, with automated detection followed by human validation, seems like an efficient way to handle the scale of the problem.
However, the paper does acknowledge some limitations of the system. For example, the automated detection model may not capture all types of hallucinations, and the human annotation process can be subjective and time-consuming. Additionally, the hallucination taxonomy, while a useful framework, may not be exhaustive and could benefit from further refinement.
Another potential issue is the reliance on the Anthropic Cooperative AI platform for distributed annotation. While this likely helps streamline the process, it raises questions about the scalability and accessibility of the system for researchers outside of Anthropic's ecosystem.
Overall, ANAH-v2 represents a significant advancement in the field of analytical hallucination detection and annotation. The system's innovations and the insights it can provide about large language model behavior are valuable contributions to the research community. However, as with any complex system, there is always room for further refinement and improvement.
Conclusion
ANAH-v2 is a powerful tool for scaling the annotation of analytical hallucinations in large language models. By breaking down the annotation process into smaller, more manageable steps and introducing specialized tooling and a hallucination taxonomy, the system enables researchers to gather more comprehensive insights about the limitations and behavior of these powerful models.
The innovations introduced by ANAH-v2 have the potential to significantly advance our understanding of large language models and inform the development of more robust and reliable AI systems. As the field of natural language processing continues to evolve, tools like ANAH-v2 will become increasingly important for ensuring the safety and trustworthiness of the technology we rely on.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ANAH-v2: Scaling Analytical Hallucination Annotation of Large Language Models
Yuzhe Gu, Ziwei Ji, Wenwei Zhang, Chengqi Lyu, Dahua Lin, Kai Chen
Large language models (LLMs) exhibit hallucinations in long-form question-answering tasks across various domains and wide applications. Current hallucination detection and mitigation datasets are limited in domains and sizes, which struggle to scale due to prohibitive labor costs and insufficient reliability of existing hallucination annotators. To facilitate the scalable oversight of LLM hallucinations, this paper introduces an iterative self-training framework that simultaneously and progressively scales up the hallucination annotation dataset and improves the accuracy of the hallucination annotator. Based on the Expectation Maximization (EM) algorithm, in each iteration, the framework first applies a hallucination annotation pipeline to annotate a scaled dataset and then trains a more accurate hallucination annotator on the dataset. This new hallucination annotator is adopted in the hallucination annotation pipeline used for the next iteration. Extensive experimental results demonstrate that the finally obtained hallucination annotator with only 7B parameters surpasses the performance of GPT-4 and obtains new state-of-the-art hallucination detection results on HaluEval and HalluQA by zero-shot inference. Such an annotator can not only evaluate the hallucination levels of various LLMs on the large-scale dataset but also help to mitigate the hallucination of LLMs generations, with the Natural Language Inference (NLI) metric increasing from 25% to 37% on HaluEval.
Read more7/8/2024

0
ANAH: Analytical Annotation of Hallucinations in Large Language Models
Ziwei Ji, Yuzhe Gu, Wenwei Zhang, Chengqi Lyu, Dahua Lin, Kai Chen
Reducing the `$textit{hallucination}$' problem of Large Language Models (LLMs) is crucial for their wide applications. A comprehensive and fine-grained measurement of the hallucination is the first key step for the governance of this issue but is under-explored in the community. Thus, we present $textbf{ANAH}$, a bilingual dataset that offers $textbf{AN}$alytical $textbf{A}$nnotation of $textbf{H}$allucinations in LLMs within Generative Question Answering. Each answer sentence in our dataset undergoes rigorous annotation, involving the retrieval of a reference fragment, the judgment of the hallucination type, and the correction of hallucinated content. ANAH consists of ~12k sentence-level annotations for ~4.3k LLM responses covering over 700 topics, constructed by a human-in-the-loop pipeline. Thanks to the fine granularity of the hallucination annotations, we can quantitatively confirm that the hallucinations of LLMs progressively accumulate in the answer and use ANAH to train and evaluate hallucination annotators. We conduct extensive experiments on studying generative and discriminative annotators and show that, although current open-source LLMs have difficulties in fine-grained hallucination annotation, the generative annotator trained with ANAH can surpass all open-source LLMs and GPT-3.5, obtain performance competitive with GPT-4, and exhibits better generalization ability on unseen questions.
Read more5/31/2024
🛸
0
AutoHall: Automated Hallucination Dataset Generation for Large Language Models
Zouying Cao, Yifei Yang, Hai Zhao
While Large language models (LLMs) have garnered widespread applications across various domains due to their powerful language understanding and generation capabilities, the detection of non-factual or hallucinatory content generated by LLMs remains scarce. Currently, one significant challenge in hallucination detection is the laborious task of time-consuming and expensive manual annotation of the hallucinatory generation. To address this issue, this paper first introduces a method for automatically constructing model-specific hallucination datasets based on existing fact-checking datasets called AutoHall. Furthermore, we propose a zero-resource and black-box hallucination detection method based on self-contradiction. We conduct experiments towards prevalent open-/closed-source LLMs, achieving superior hallucination detection performance compared to extant baselines. Moreover, our experiments reveal variations in hallucination proportions and types among different models.
Read more7/22/2024

0
Training Language Models on the Knowledge Graph: Insights on Hallucinations and Their Detectability
Jiri Hron, Laura Culp, Gamaleldin Elsayed, Rosanne Liu, Ben Adlam, Maxwell Bileschi, Bernd Bohnet, JD Co-Reyes, Noah Fiedel, C. Daniel Freeman, Izzeddin Gur, Kathleen Kenealy, Jaehoon Lee, Peter J. Liu, Gaurav Mishra, Igor Mordatch, Azade Nova, Roman Novak, Aaron Parisi, Jeffrey Pennington, Alex Rizkowsky, Isabelle Simpson, Hanie Sedghi, Jascha Sohl-dickstein, Kevin Swersky, Sharad Vikram, Tris Warkentin, Lechao Xiao, Kelvin Xu, Jasper Snoek, Simon Kornblith
While many capabilities of language models (LMs) improve with increased training budget, the influence of scale on hallucinations is not yet fully understood. Hallucinations come in many forms, and there is no universally accepted definition. We thus focus on studying only those hallucinations where a correct answer appears verbatim in the training set. To fully control the training data content, we construct a knowledge graph (KG)-based dataset, and use it to train a set of increasingly large LMs. We find that for a fixed dataset, larger and longer-trained LMs hallucinate less. However, hallucinating on $leq5$% of the training data requires an order of magnitude larger model, and thus an order of magnitude more compute, than Hoffmann et al. (2022) reported was optimal. Given this costliness, we study how hallucination detectors depend on scale. While we see detector size improves performance on fixed LM's outputs, we find an inverse relationship between the scale of the LM and the detectability of its hallucinations.
Read more8/16/2024