ANAH: Analytical Annotation of Hallucinations in Large Language Models

0

Sign in to get full access
Overview
- This paper introduces ANAH, a method for analytically annotating hallucinations in large language models.
- Hallucinations are when a language model generates output that is factually incorrect or nonsensical, even if the output is fluent and coherent.
- The ANAH method aims to identify and categorize different types of hallucinations to better understand their causes and mitigate their occurrence.
Plain English Explanation
Large language models like GPT-3 are very impressive at generating human-like text. However, they can sometimes produce information that is completely made up or incorrect, a phenomenon known as "hallucinations." This paper introduces a new method called ANAH that can identify and analyze different kinds of hallucinations in these models.
The key idea is to create a dataset of examples where a language model has hallucinated, and then have human raters carefully examine and categorize the hallucinations. This allows researchers to better understand the underlying causes and patterns of hallucinations, which can then inform strategies to make the models more reliable and truthful. Similar efforts have been made for other AI systems that can hallucinate, like summarization models.
By studying hallucinations in-depth using the ANAH method, the authors hope to make progress towards building AI systems that are more robust, trustworthy and aligned with human values. This is an important step in the ongoing quest to create AI that is safe and beneficial.
Technical Explanation
The ANAH method involves several key steps. First, the researchers collect a dataset of examples where a large language model has generated hallucinated output. This is done by having the model answer a variety of questions and prompts, and flagging any responses that contain factual errors or nonsensical information.
Next, the researchers recruit human raters to closely analyze each hallucination example. The raters are asked to categorize the hallucinations into different types, such as factual errors, logical inconsistencies, or irrelevant tangents. They also assess the severity of the hallucination and provide other insights.
By building this annotated dataset of hallucinations, the researchers can then conduct analysis to identify patterns and underlying causes. For example, they may find that certain types of prompts are more likely to trigger hallucinations, or that the model's performance degrades in particular domains.
The insights gained from the ANAH method can then inform strategies to detect and mitigate hallucinations in large language models, making them more reliable and trustworthy. This is an important step towards building safer and more robust AI systems that can be responsibly deployed in real-world applications.
Critical Analysis
The ANAH method provides a valuable framework for systematically studying hallucinations in large language models. By creating a detailed, annotated dataset of hallucination examples, the researchers enable deeper analysis that can uncover important insights.
However, one potential limitation is the reliance on human raters to categorize the hallucinations. While this approach has benefits, there may be some subjectivity or inconsistency in how different raters interpret and label the examples. Further research could explore ways to supplement or augment the human ratings with more objective, automated detection methods.
Additionally, the dataset constructed in this study is limited to a specific set of prompts and models. While this allows for a focused analysis, it remains to be seen how well the insights generalize to a broader range of language models and use cases. Expanding the scope of the dataset could yield additional valuable findings.
Overall, the ANAH method represents an important step forward in understanding and mitigating the hallucination issue in large language models. By continuing to build on this work, the research community can make progress towards AI systems that are more reliable, trustworthy, and beneficial to society.
Conclusion
The ANAH method introduced in this paper provides a structured approach for analyzing hallucinations in large language models. By creating an annotated dataset of hallucination examples and having human raters categorize them, the researchers can uncover patterns and insights that can inform strategies to detect and mitigate these issues.
This is a crucial step towards building AI systems that are more robust, truthful and aligned with human values. As large language models become more widely deployed, it is essential that we understand and address their limitations, including the tendency to hallucinate. The ANAH framework represents an important contribution to this ongoing effort.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ANAH: Analytical Annotation of Hallucinations in Large Language Models
Ziwei Ji, Yuzhe Gu, Wenwei Zhang, Chengqi Lyu, Dahua Lin, Kai Chen
Reducing the `$textit{hallucination}$' problem of Large Language Models (LLMs) is crucial for their wide applications. A comprehensive and fine-grained measurement of the hallucination is the first key step for the governance of this issue but is under-explored in the community. Thus, we present $textbf{ANAH}$, a bilingual dataset that offers $textbf{AN}$alytical $textbf{A}$nnotation of $textbf{H}$allucinations in LLMs within Generative Question Answering. Each answer sentence in our dataset undergoes rigorous annotation, involving the retrieval of a reference fragment, the judgment of the hallucination type, and the correction of hallucinated content. ANAH consists of ~12k sentence-level annotations for ~4.3k LLM responses covering over 700 topics, constructed by a human-in-the-loop pipeline. Thanks to the fine granularity of the hallucination annotations, we can quantitatively confirm that the hallucinations of LLMs progressively accumulate in the answer and use ANAH to train and evaluate hallucination annotators. We conduct extensive experiments on studying generative and discriminative annotators and show that, although current open-source LLMs have difficulties in fine-grained hallucination annotation, the generative annotator trained with ANAH can surpass all open-source LLMs and GPT-3.5, obtain performance competitive with GPT-4, and exhibits better generalization ability on unseen questions.
Read more5/31/2024
0
ANAH-v2: Scaling Analytical Hallucination Annotation of Large Language Models
Yuzhe Gu, Ziwei Ji, Wenwei Zhang, Chengqi Lyu, Dahua Lin, Kai Chen
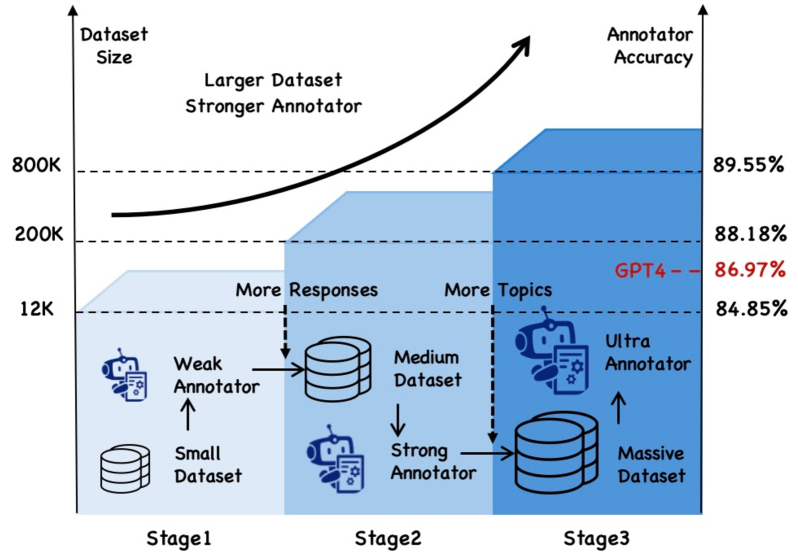
Large language models (LLMs) exhibit hallucinations in long-form question-answering tasks across various domains and wide applications. Current hallucination detection and mitigation datasets are limited in domains and sizes, which struggle to scale due to prohibitive labor costs and insufficient reliability of existing hallucination annotators. To facilitate the scalable oversight of LLM hallucinations, this paper introduces an iterative self-training framework that simultaneously and progressively scales up the hallucination annotation dataset and improves the accuracy of the hallucination annotator. Based on the Expectation Maximization (EM) algorithm, in each iteration, the framework first applies a hallucination annotation pipeline to annotate a scaled dataset and then trains a more accurate hallucination annotator on the dataset. This new hallucination annotator is adopted in the hallucination annotation pipeline used for the next iteration. Extensive experimental results demonstrate that the finally obtained hallucination annotator with only 7B parameters surpasses the performance of GPT-4 and obtains new state-of-the-art hallucination detection results on HaluEval and HalluQA by zero-shot inference. Such an annotator can not only evaluate the hallucination levels of various LLMs on the large-scale dataset but also help to mitigate the hallucination of LLMs generations, with the Natural Language Inference (NLI) metric increasing from 25% to 37% on HaluEval.
Read more7/8/2024

0
Don't Believe Everything You Read: Enhancing Summarization Interpretability through Automatic Identification of Hallucinations in Large Language Models
Priyesh Vakharia, Devavrat Joshi, Meenal Chavan, Dhananjay Sonawane, Bhrigu Garg, Parsa Mazaheri
Large Language Models (LLMs) are adept at text manipulation -- tasks such as machine translation and text summarization. However, these models can also be prone to hallucination, which can be detrimental to the faithfulness of any answers that the model provides. Recent works in combating hallucinations in LLMs deal with identifying hallucinated sentences and categorizing the different ways in which models hallucinate. This paper takes a deep dive into LLM behavior with respect to hallucinations, defines a token-level approach to identifying different kinds of hallucinations, and further utilizes this token-level tagging to improve the interpretability and faithfulness of LLMs in dialogue summarization tasks. Through this, the paper presents a new, enhanced dataset and a new training paradigm.
Read more4/4/2024
🛸
0
AutoHall: Automated Hallucination Dataset Generation for Large Language Models
Zouying Cao, Yifei Yang, Hai Zhao
While Large language models (LLMs) have garnered widespread applications across various domains due to their powerful language understanding and generation capabilities, the detection of non-factual or hallucinatory content generated by LLMs remains scarce. Currently, one significant challenge in hallucination detection is the laborious task of time-consuming and expensive manual annotation of the hallucinatory generation. To address this issue, this paper first introduces a method for automatically constructing model-specific hallucination datasets based on existing fact-checking datasets called AutoHall. Furthermore, we propose a zero-resource and black-box hallucination detection method based on self-contradiction. We conduct experiments towards prevalent open-/closed-source LLMs, achieving superior hallucination detection performance compared to extant baselines. Moreover, our experiments reveal variations in hallucination proportions and types among different models.
Read more7/22/2024