Analyzing Large Language Models for Classroom Discussion Assessment
2406.08680
0
0

Abstract
Automatically assessing classroom discussion quality is becoming increasingly feasible with the help of new NLP advancements such as large language models (LLMs). In this work, we examine how the assessment performance of 2 LLMs interacts with 3 factors that may affect performance: task formulation, context length, and few-shot examples. We also explore the computational efficiency and predictive consistency of the 2 LLMs. Our results suggest that the 3 aforementioned factors do affect the performance of the tested LLMs and there is a relation between consistency and performance. We recommend a LLM-based assessment approach that has a good balance in terms of predictive performance, computational efficiency, and consistency.
Create account to get full access
Overview
- This paper explores the use of large language models (LLMs) for assessing classroom discussion, a key component of student learning and participation.
- The researchers investigate how well LLMs can analyze and provide feedback on the content, coherence, and engagement of student responses during classroom discussions.
- The study aims to understand the capabilities and limitations of LLMs in this context, with potential implications for leveraging large language models for NLG evaluation advances and advancing research through large language models as research assistants.
Plain English Explanation
The paper looks at how well powerful AI language models, known as large language models (LLMs), can be used to assess and provide feedback on student discussions in a classroom setting. The researchers want to understand if these advanced language models can effectively analyze the content, organization, and engagement of student responses during classroom conversations.
This is an important area to explore because classroom discussions are a crucial part of the learning process, allowing students to engage with the material, share their thoughts, and build understanding. Being able to use AI systems to provide feedback and support these discussions could be very helpful for both students and teachers.
The researchers run experiments to see how well the LLMs can perform this assessment task, looking at factors like how accurately the models can identify the key ideas in student responses, how well they can evaluate the logical flow and coherence of the responses, and how well they can gauge the level of engagement and participation.
The findings from this research could have implications for using large language models to enable automated formative feedback and systematically evaluating the capabilities of large language models for natural language processing tasks. If the LLMs prove effective at assessing classroom discussions, it could lead to new tools and techniques for supporting student learning and engagement.
Technical Explanation
The paper investigates the use of large language models (LLMs) for analyzing and providing feedback on student responses during classroom discussions. The researchers designed experiments to evaluate the performance of LLMs on several key aspects of this task:
- Content Analysis: Can the LLMs accurately identify the key ideas and conceptual content in student responses?
- Coherence Assessment: How well can the LLMs evaluate the logical flow and organizational structure of the student responses?
- Engagement Measurement: Can the LLMs gauge the level of engagement and participation demonstrated in the student responses?
To conduct the study, the researchers collected a dataset of transcripts from real classroom discussions across various subject areas. They then used several state-of-the-art LLMs, including GPT-3 and BERT, to analyze the student responses in this dataset.
The results showed that the LLMs were generally able to perform well on the content analysis and coherence assessment tasks, demonstrating the models' abilities to understand the substance and structure of the student responses. However, the models struggled more with the engagement measurement, suggesting limitations in their capacity to capture the nuances of interpersonal dynamics and interactive discourse.
Overall, the findings indicate that LLMs have promising capabilities for assessing certain aspects of classroom discussions, but also highlight areas for further development and refinement, such as improving the models' understanding of conversational engagement and interactive behavior.
Critical Analysis
The paper provides a thorough and well-designed investigation into the use of LLMs for classroom discussion assessment, but it also acknowledges several important limitations and areas for future research.
One key limitation is the challenge of accurately measuring student engagement, which the models struggled with compared to the content and coherence tasks. This suggests that the current generation of LLMs may still have difficulty fully capturing the subtleties of human interaction and interpersonal dynamics. Further research is needed to explore how to better incorporate these elements into the models' analysis.
Additionally, the study is limited to a specific dataset of classroom discussion transcripts, which may not fully represent the diversity of discussion styles and contexts that occur in real-world educational settings. Expanding the research to a wider range of discussion scenarios, subject areas, and student populations could help validate the findings and uncover additional insights.
Another area for further exploration is the potential for large language models as partners for student essay assessment. While the current paper focuses on discussions, the capabilities of LLMs may also be relevant for evaluating other forms of student work, such as written essays, which could have important implications for automated feedback and assessment.
Overall, the paper makes a valuable contribution to the understanding of LLM capabilities in the context of educational assessment, but it also highlights the need for continued research and development to fully realize the potential of these models in supporting student learning and engagement.
Conclusion
This paper presents an important study on the use of large language models (LLMs) for assessing student discussions in a classroom setting. The researchers found that LLMs can effectively analyze the content and coherence of student responses, but struggle more with measuring engagement and interactive dynamics.
The findings suggest that LLMs have promising capabilities for providing automated feedback and support for classroom discussions, which could aid both students and teachers. However, the research also identifies areas for further development, such as improving the models' understanding of conversational nuance and interpersonal interaction.
As large language models continue to advance, this study provides valuable insights into how these powerful AI systems can be leveraged to enhance educational practices and support student learning. The implications of this work could extend beyond the classroom, informing the use of LLMs in a variety of contexts where understanding and engaging with human discourse is crucial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Large Language Models as Partners in Student Essay Evaluation
Toru Ishida, Tongxi Liu, Hailong Wang, William K. Cheung
0
0
As the importance of comprehensive evaluation in workshop courses increases, there is a growing demand for efficient and fair assessment methods that reduce the workload for faculty members. This paper presents an evaluation conducted with Large Language Models (LLMs) using actual student essays in three scenarios: 1) without providing guidance such as rubrics, 2) with pre-specified rubrics, and 3) through pairwise comparison of essays. Quantitative analysis of the results revealed a strong correlation between LLM and faculty member assessments in the pairwise comparison scenario with pre-specified rubrics, although concerns about the quality and stability of evaluations remained. Therefore, we conducted a qualitative analysis of LLM assessment comments, showing that: 1) LLMs can match the assessment capabilities of faculty members, 2) variations in LLM assessments should be interpreted as diversity rather than confusion, and 3) assessments by humans and LLMs can differ and complement each other. In conclusion, this paper suggests that LLMs should not be seen merely as assistants to faculty members but as partners in evaluation committees and outlines directions for further research.
5/30/2024
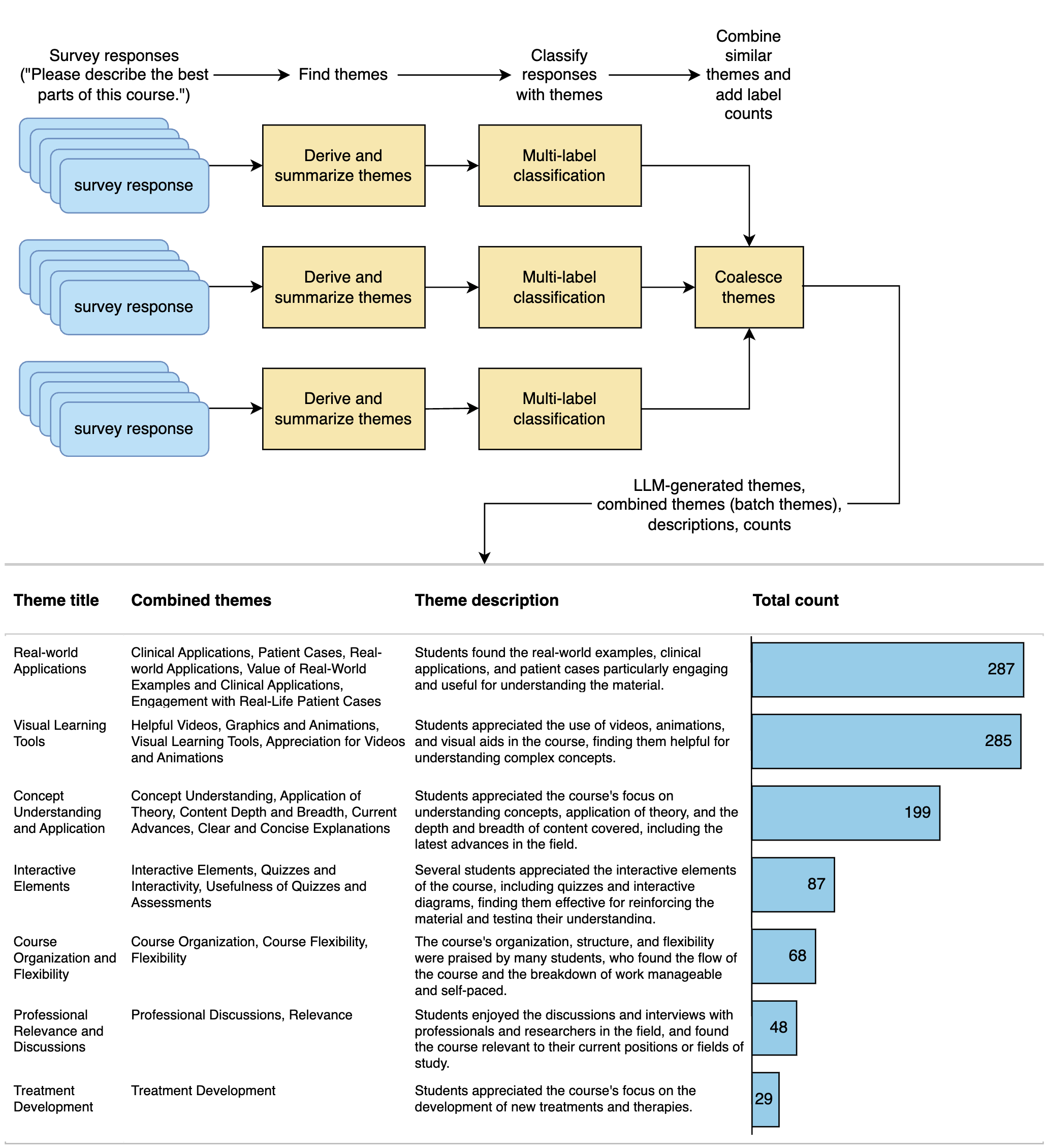
New!A Large Language Model Approach to Educational Survey Feedback Analysis
Michael J. Parker, Caitlin Anderson, Claire Stone, YeaRim Oh
0
0
This paper assesses the potential for the large language models (LLMs) GPT-4 and GPT-3.5 to aid in deriving insight from education feedback surveys. Exploration of LLM use cases in education has focused on teaching and learning, with less exploration of capabilities in education feedback analysis. Survey analysis in education involves goals such as finding gaps in curricula or evaluating teachers, often requiring time-consuming manual processing of textual responses. LLMs have the potential to provide a flexible means of achieving these goals without specialized machine learning models or fine-tuning. We demonstrate a versatile approach to such goals by treating them as sequences of natural language processing (NLP) tasks including classification (multi-label, multi-class, and binary), extraction, thematic analysis, and sentiment analysis, each performed by LLM. We apply these workflows to a real-world dataset of 2500 end-of-course survey comments from biomedical science courses, and evaluate a zero-shot approach (i.e., requiring no examples or labeled training data) across all tasks, reflecting education settings, where labeled data is often scarce. By applying effective prompting practices, we achieve human-level performance on multiple tasks with GPT-4, enabling workflows necessary to achieve typical goals. We also show the potential of inspecting LLMs' chain-of-thought (CoT) reasoning for providing insight that may foster confidence in practice. Moreover, this study features development of a versatile set of classification categories, suitable for various course types (online, hybrid, or in-person) and amenable to customization. Our results suggest that LLMs can be used to derive a range of insights from survey text.
6/28/2024

Leveraging Large Language Models for NLG Evaluation: Advances and Challenges
Zhen Li, Xiaohan Xu, Tao Shen, Can Xu, Jia-Chen Gu, Yuxuan Lai, Chongyang Tao, Shuai Ma
0
0
In the rapidly evolving domain of Natural Language Generation (NLG) evaluation, introducing Large Language Models (LLMs) has opened new avenues for assessing generated content quality, e.g., coherence, creativity, and context relevance. This paper aims to provide a thorough overview of leveraging LLMs for NLG evaluation, a burgeoning area that lacks a systematic analysis. We propose a coherent taxonomy for organizing existing LLM-based evaluation metrics, offering a structured framework to understand and compare these methods. Our detailed exploration includes critically assessing various LLM-based methodologies, as well as comparing their strengths and limitations in evaluating NLG outputs. By discussing unresolved challenges, including bias, robustness, domain-specificity, and unified evaluation, this paper seeks to offer insights to researchers and advocate for fairer and more advanced NLG evaluation techniques.
6/13/2024

Evaluating the Performance of Large Language Models via Debates
Behrad Moniri, Hamed Hassani, Edgar Dobriban
0
0
Large Language Models (LLMs) are rapidly evolving and impacting various fields, necessitating the development of effective methods to evaluate and compare their performance. Most current approaches for performance evaluation are either based on fixed, domain-specific questions that lack the flexibility required in many real-world applications where tasks are not always from a single domain, or rely on human input, making them unscalable. We propose an automated benchmarking framework based on debates between LLMs, judged by another LLM. This method assesses not only domain knowledge, but also skills such as problem definition and inconsistency recognition. We evaluate the performance of various state-of-the-art LLMs using the debate framework and achieve rankings that align closely with popular rankings based on human input, eliminating the need for costly human crowdsourcing.
6/18/2024