Evaluating the Performance of Large Language Models via Debates
2406.11044
0
0

Abstract
Large Language Models (LLMs) are rapidly evolving and impacting various fields, necessitating the development of effective methods to evaluate and compare their performance. Most current approaches for performance evaluation are either based on fixed, domain-specific questions that lack the flexibility required in many real-world applications where tasks are not always from a single domain, or rely on human input, making them unscalable. We propose an automated benchmarking framework based on debates between LLMs, judged by another LLM. This method assesses not only domain knowledge, but also skills such as problem definition and inconsistency recognition. We evaluate the performance of various state-of-the-art LLMs using the debate framework and achieve rankings that align closely with popular rankings based on human input, eliminating the need for costly human crowdsourcing.
Create account to get full access
Overview
- This paper evaluates the performance of large language models (LLMs) through the use of debates.
- The researchers propose a debate-based evaluation method to assess the capabilities of LLMs in areas such as persuasiveness, logical reasoning, and multi-perspective analysis.
- The paper explores how debates can provide a more comprehensive and nuanced assessment of LLM performance compared to traditional evaluation methods.
Plain English Explanation
Large language models (LLMs) are a type of artificial intelligence that can generate human-like text on a wide range of topics. These models have become increasingly sophisticated, but it can be challenging to fully assess their capabilities using traditional evaluation methods.
The researchers in this paper propose using debates as a way to more thoroughly evaluate the performance of LLMs. In a debate, the model is asked to argue for and against a particular position, leveraging its language generation and reasoning abilities. This approach can provide insights into the model's ability to think critically, consider multiple perspectives, and construct persuasive arguments.
By engaging in debates, the researchers believe that LLMs can demonstrate their skills in a more nuanced and comprehensive way than traditional evaluation methods, which may only assess specific capabilities in isolation. This approach can help identify the strengths and limitations of LLMs, as well as inform the development of more advanced models in the future.
Technical Explanation
The researchers designed a debate-based evaluation system to assess the performance of large language models (LLMs). In this system, the LLM is given a prompt to debate a particular topic, with the model required to argue both for and against the position.
The researchers analyzed the debates generated by the LLMs, examining factors such as the coherence and persuasiveness of the arguments, the model's ability to consider multiple perspectives, and its logical reasoning skills. The debate transcripts were also evaluated by human judges to provide a more comprehensive assessment of the LLM's capabilities.
The results of the study suggest that the debate-based evaluation approach can provide a more nuanced and comprehensive assessment of LLM performance compared to traditional evaluation methods. The researchers found that LLMs were able to engage in substantive debates, considering various viewpoints and constructing persuasive arguments.
Critical Analysis
The researchers acknowledge that the debate-based evaluation approach has some limitations. For example, the quality of the debates can be influenced by the specific prompts used, and there may be some inherent bias in the human evaluation process.
Additionally, the paper does not address the potential challenges of scaling this evaluation method to a large number of LLMs or the computational resources required to run the debates. Further research may be needed to streamline the process and make it more scalable.
It is also worth considering the ethical implications of using LLMs in debate-like scenarios, as these models may be capable of generating convincing arguments for positions that are harmful or unethical. Careful consideration of the ethical implications of this evaluation approach is important.
Conclusion
This paper presents a novel approach to evaluating the performance of large language models (LLMs) through the use of debates. The researchers argue that this method can provide a more comprehensive and nuanced assessment of LLM capabilities, including their ability to engage in persuasive argumentation, consider multiple perspectives, and reason logically.
While the approach has some limitations, the findings suggest that debates could be a valuable tool for advancing the development and understanding of LLMs. As these models continue to evolve, innovative evaluation methods like the one proposed in this paper will be crucial for ensuring that they are developed and deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Leveraging Large Language Models for NLG Evaluation: Advances and Challenges
Zhen Li, Xiaohan Xu, Tao Shen, Can Xu, Jia-Chen Gu, Yuxuan Lai, Chongyang Tao, Shuai Ma
0
0
In the rapidly evolving domain of Natural Language Generation (NLG) evaluation, introducing Large Language Models (LLMs) has opened new avenues for assessing generated content quality, e.g., coherence, creativity, and context relevance. This paper aims to provide a thorough overview of leveraging LLMs for NLG evaluation, a burgeoning area that lacks a systematic analysis. We propose a coherent taxonomy for organizing existing LLM-based evaluation metrics, offering a structured framework to understand and compare these methods. Our detailed exploration includes critically assessing various LLM-based methodologies, as well as comparing their strengths and limitations in evaluating NLG outputs. By discussing unresolved challenges, including bias, robustness, domain-specificity, and unified evaluation, this paper seeks to offer insights to researchers and advocate for fairer and more advanced NLG evaluation techniques.
6/13/2024
An Empirical Analysis on Large Language Models in Debate Evaluation
Xinyi Liu, Pinxin Liu, Hangfeng He
0
0
In this study, we investigate the capabilities and inherent biases of advanced large language models (LLMs) such as GPT-3.5 and GPT-4 in the context of debate evaluation. We discover that LLM's performance exceeds humans and surpasses the performance of state-of-the-art methods fine-tuned on extensive datasets in debate evaluation. We additionally explore and analyze biases present in LLMs, including positional bias, lexical bias, order bias, which may affect their evaluative judgments. Our findings reveal a consistent bias in both GPT-3.5 and GPT-4 towards the second candidate response presented, attributed to prompt design. We also uncover lexical biases in both GPT-3.5 and GPT-4, especially when label sets carry connotations such as numerical or sequential, highlighting the critical need for careful label verbalizer selection in prompt design. Additionally, our analysis indicates a tendency of both models to favor the debate's concluding side as the winner, suggesting an end-of-discussion bias.
6/5/2024
💬
PRE: A Peer Review Based Large Language Model Evaluator
Zhumin Chu, Qingyao Ai, Yiteng Tu, Haitao Li, Yiqun Liu
0
0
The impressive performance of large language models (LLMs) has attracted considerable attention from the academic and industrial communities. Besides how to construct and train LLMs, how to effectively evaluate and compare the capacity of LLMs has also been well recognized as an important yet difficult problem. Existing paradigms rely on either human annotators or model-based evaluators to evaluate the performance of LLMs on different tasks. However, these paradigms often suffer from high cost, low generalizability, and inherited biases in practice, which make them incapable of supporting the sustainable development of LLMs in long term. In order to address these issues, inspired by the peer review systems widely used in academic publication process, we propose a novel framework that can automatically evaluate LLMs through a peer-review process. Specifically, for the evaluation of a specific task, we first construct a small qualification exam to select reviewers from a couple of powerful LLMs. Then, to actually evaluate the submissions written by different candidate LLMs, i.e., the evaluatees, we use the reviewer LLMs to rate or compare the submissions. The final ranking of evaluatee LLMs is generated based on the results provided by all reviewers. We conducted extensive experiments on text summarization tasks with eleven LLMs including GPT-4. The results demonstrate the existence of biasness when evaluating using a single LLM. Also, our PRE model outperforms all the baselines, illustrating the effectiveness of the peer review mechanism.
6/4/2024
Debating with More Persuasive LLMs Leads to More Truthful Answers
Akbir Khan, John Hughes, Dan Valentine, Laura Ruis, Kshitij Sachan, Ansh Radhakrishnan, Edward Grefenstette, Samuel R. Bowman, Tim Rocktaschel, Ethan Perez
0
0
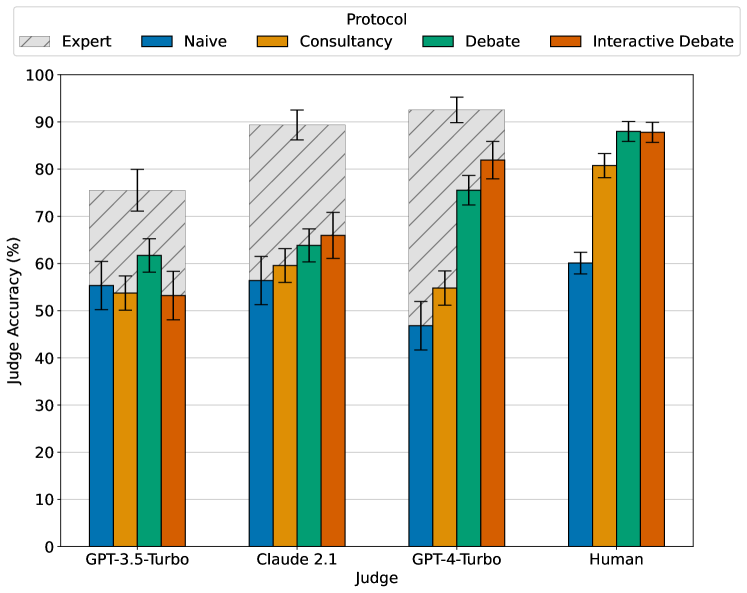
Common methods for aligning large language models (LLMs) with desired behaviour heavily rely on human-labelled data. However, as models grow increasingly sophisticated, they will surpass human expertise, and the role of human evaluation will evolve into non-experts overseeing experts. In anticipation of this, we ask: can weaker models assess the correctness of stronger models? We investigate this question in an analogous setting, where stronger models (experts) possess the necessary information to answer questions and weaker models (non-experts) lack this information. The method we evaluate is debate, where two LLM experts each argue for a different answer, and a non-expert selects the answer. We find that debate consistently helps both non-expert models and humans answer questions, achieving 76% and 88% accuracy respectively (naive baselines obtain 48% and 60%). Furthermore, optimising expert debaters for persuasiveness in an unsupervised manner improves non-expert ability to identify the truth in debates. Our results provide encouraging empirical evidence for the viability of aligning models with debate in the absence of ground truth.
5/31/2024