Analyzing LLM Behavior in Dialogue Summarization: Unveiling Circumstantial Hallucination Trends
2406.03487
0
0

Abstract
Recent advancements in large language models (LLMs) have considerably advanced the capabilities of summarization systems. However, they continue to face concerns about hallucinations. While prior work has evaluated LLMs extensively in news domains, most evaluation of dialogue summarization has focused on BART-based models, leaving a gap in our understanding of their faithfulness. Our work benchmarks the faithfulness of LLMs for dialogue summarization, using human annotations and focusing on identifying and categorizing span-level inconsistencies. Specifically, we focus on two prominent LLMs: GPT-4 and Alpaca-13B. Our evaluation reveals subtleties as to what constitutes a hallucination: LLMs often generate plausible inferences, supported by circumstantial evidence in the conversation, that lack direct evidence, a pattern that is less prevalent in older models. We propose a refined taxonomy of errors, coining the category of Circumstantial Inference to bucket these LLM behaviors and release the dataset. Using our taxonomy, we compare the behavioral differences between LLMs and older fine-tuned models. Additionally, we systematically assess the efficacy of automatic error detection methods on LLM summaries and find that they struggle to detect these nuanced errors. To address this, we introduce two prompt-based approaches for fine-grained error detection that outperform existing metrics, particularly for identifying Circumstantial Inference.
Create account to get full access
Overview
- This paper explores the behavior of large language models (LLMs) in the context of dialogue summarization, with a focus on understanding the trends of circumstantial hallucination.
- The researchers conducted a human evaluation study to assess the zero-shot performance of LLMs in generating dialogue summaries, examining the prevalence and nature of hallucinations.
- The findings provide insights into the limitations of LLMs in this domain and inform strategies for improving the reliability of dialogue summarization systems.
Plain English Explanation
In this research paper, the authors investigate how large language models (LLMs) - powerful AI systems that can generate human-like text - perform when tasked with summarizing dialogues or conversations. Specifically, they are interested in understanding the tendency of these models to "hallucinate" - that is, to generate information that is not actually present in the original dialogue.
The researchers set up an experiment where they asked LLMs to generate summaries of dialogues without any additional training or fine-tuning. They then had human evaluators assess the quality and accuracy of these summaries, looking for instances of hallucination - where the model generated content that was not supported by the dialogue itself.
The findings reveal that LLMs do indeed struggle with hallucination in this context, often including information in the summaries that was not actually discussed in the original conversation. This suggests that while LLMs can be impressive at generating human-like text, they still have limitations when it comes to accurately capturing the essence of a dialogue and conveying it in a concise summary.
The insights from this research can help inform the development of more reliable and trustworthy dialogue summarization systems, which could be useful in a variety of real-world applications, such as customer service, meeting notes, or medical consultations. By understanding the patterns and causes of hallucination in LLMs, researchers and developers can work to address these issues and create AI systems that can more faithfully and reliably summarize dialogues.
Technical Explanation
The researchers conducted a human evaluation study to assess the zero-shot performance of large language models (LLMs) in generating dialogue summaries. They were particularly interested in examining the prevalence and nature of "circumstantial hallucination" - instances where the LLMs generated information that was not actually present in the original dialogue.
The study involved collecting a diverse dataset of dialogues and using various LLM models to generate summaries for each dialogue without any additional training or fine-tuning. These summaries were then evaluated by human annotators, who assessed the accuracy and coherence of the generated text.
The results revealed that LLMs are prone to circumstantial hallucination in the context of dialogue summarization. The models frequently included information in the summaries that was not supported by the original dialogue, suggesting a lack of grounding in the actual conversation.
This finding aligns with previous research on hallucination in LLMs and the challenges of generating reliable summaries. The authors propose that the tendency for LLMs to hallucinate in this domain may be due to the complex and contextual nature of dialogues, which can be difficult for models to fully capture without additional training or specialized architectures.
The insights from this study contribute to a broader understanding of hallucination in large vision-language models and inform strategies for improving the reliability of LLM-powered code generation. By identifying the limitations of current LLMs in dialogue summarization, this research can inform the development of more robust and trustworthy systems in this domain.
Critical Analysis
The paper provides a valuable contribution to the understanding of LLM behavior in the context of dialogue summarization. The researchers' focus on circumstantial hallucination, where the models generate information not present in the original dialogue, is particularly insightful.
One potential limitation of the study is the use of zero-shot evaluation, where the LLMs are not fine-tuned or trained on the specific task of dialogue summarization. While this provides a useful baseline, it may not fully capture the models' potential performance with additional training or specialized architectures.
Additionally, the paper does not delve into the specific mechanisms or underlying causes of the observed hallucination patterns. Further exploration of the cognitive and architectural factors that contribute to this behavior could lead to more targeted strategies for mitigating hallucination in LLMs.
It would also be interesting to see the researchers extend their analysis to other types of hallucination, such as semantic or factual hallucination, to gain a more comprehensive understanding of the LLMs' limitations in this domain.
Overall, the paper's findings highlight the need for continued research and development in the field of reliable and trustworthy dialogue summarization systems. By critically examining the shortcomings of current LLMs, this work can inform the design of more robust and accurate models that can better serve real-world applications.
Conclusion
This research paper sheds light on the behavior of large language models (LLMs) in the context of dialogue summarization, with a specific focus on understanding the trends of circumstantial hallucination. The study's findings reveal that LLMs struggle with accurately capturing the essence of dialogues, often generating information in the summaries that is not supported by the original conversation.
These insights contribute to a growing body of research on the limitations of LLMs and the challenges of developing reliable and trustworthy text summarization systems. By identifying the prevalence and nature of hallucination in LLM-generated dialogue summaries, the paper informs strategies for improving the performance and robustness of these models in this domain.
As AI technology continues to advance, it is crucial to deeply understand the capabilities and limitations of LLMs, especially in high-stakes applications where accuracy and reliability are paramount. The research presented in this paper represents an important step in this direction, paving the way for the development of more sophisticated and trustworthy dialogue summarization systems that can better serve the needs of various industries and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Don't Believe Everything You Read: Enhancing Summarization Interpretability through Automatic Identification of Hallucinations in Large Language Models
Priyesh Vakharia, Devavrat Joshi, Meenal Chavan, Dhananjay Sonawane, Bhrigu Garg, Parsa Mazaheri
0
0
Large Language Models (LLMs) are adept at text manipulation -- tasks such as machine translation and text summarization. However, these models can also be prone to hallucination, which can be detrimental to the faithfulness of any answers that the model provides. Recent works in combating hallucinations in LLMs deal with identifying hallucinated sentences and categorizing the different ways in which models hallucinate. This paper takes a deep dive into LLM behavior with respect to hallucinations, defines a token-level approach to identifying different kinds of hallucinations, and further utilizes this token-level tagging to improve the interpretability and faithfulness of LLMs in dialogue summarization tasks. Through this, the paper presents a new, enhanced dataset and a new training paradigm.
4/4/2024
Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models
Matthew Dahl, Varun Magesh, Mirac Suzgun, Daniel E. Ho
0
0
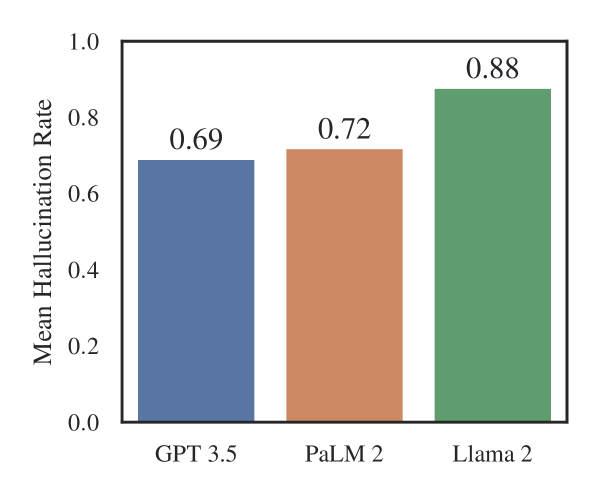
Do large language models (LLMs) know the law? These models are increasingly being used to augment legal practice, education, and research, yet their revolutionary potential is threatened by the presence of hallucinations -- textual output that is not consistent with legal facts. We present the first systematic evidence of these hallucinations, documenting LLMs' varying performance across jurisdictions, courts, time periods, and cases. Our work makes four key contributions. First, we develop a typology of legal hallucinations, providing a conceptual framework for future research in this area. Second, we find that legal hallucinations are alarmingly prevalent, occurring between 58% of the time with ChatGPT 4 and 88% with Llama 2, when these models are asked specific, verifiable questions about random federal court cases. Third, we illustrate that LLMs often fail to correct a user's incorrect legal assumptions in a contra-factual question setup. Fourth, we provide evidence that LLMs cannot always predict, or do not always know, when they are producing legal hallucinations. Taken together, our findings caution against the rapid and unsupervised integration of popular LLMs into legal tasks. Even experienced lawyers must remain wary of legal hallucinations, and the risks are highest for those who stand to benefit from LLMs the most -- pro se litigants or those without access to traditional legal resources.
6/24/2024
Towards Detecting LLMs Hallucination via Markov Chain-based Multi-agent Debate Framework
Xiaoxi Sun, Jinpeng Li, Yan Zhong, Dongyan Zhao, Rui Yan
0
0
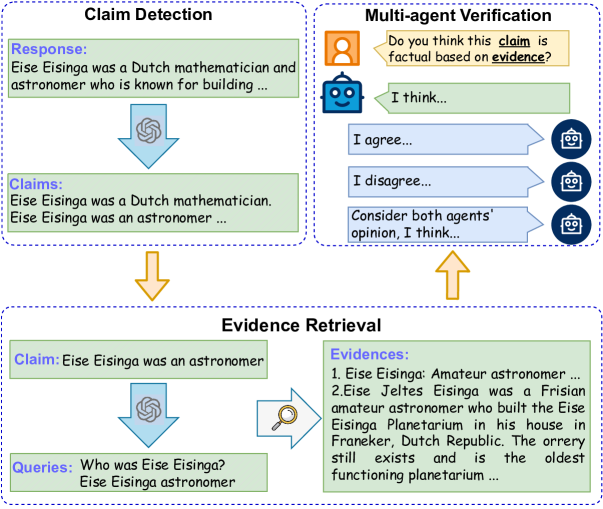
The advent of large language models (LLMs) has facilitated the development of natural language text generation. It also poses unprecedented challenges, with content hallucination emerging as a significant concern. Existing solutions often involve expensive and complex interventions during the training process. Moreover, some approaches emphasize problem disassembly while neglecting the crucial validation process, leading to performance degradation or limited applications. To overcome these limitations, we propose a Markov Chain-based multi-agent debate verification framework to enhance hallucination detection accuracy in concise claims. Our method integrates the fact-checking process, including claim detection, evidence retrieval, and multi-agent verification. In the verification stage, we deploy multiple agents through flexible Markov Chain-based debates to validate individual claims, ensuring meticulous verification outcomes. Experimental results across three generative tasks demonstrate that our approach achieves significant improvements over baselines.
6/6/2024
Hallucination Diversity-Aware Active Learning for Text Summarization
Yu Xia, Xu Liu, Tong Yu, Sungchul Kim, Ryan A. Rossi, Anup Rao, Tung Mai, Shuai Li
0
0
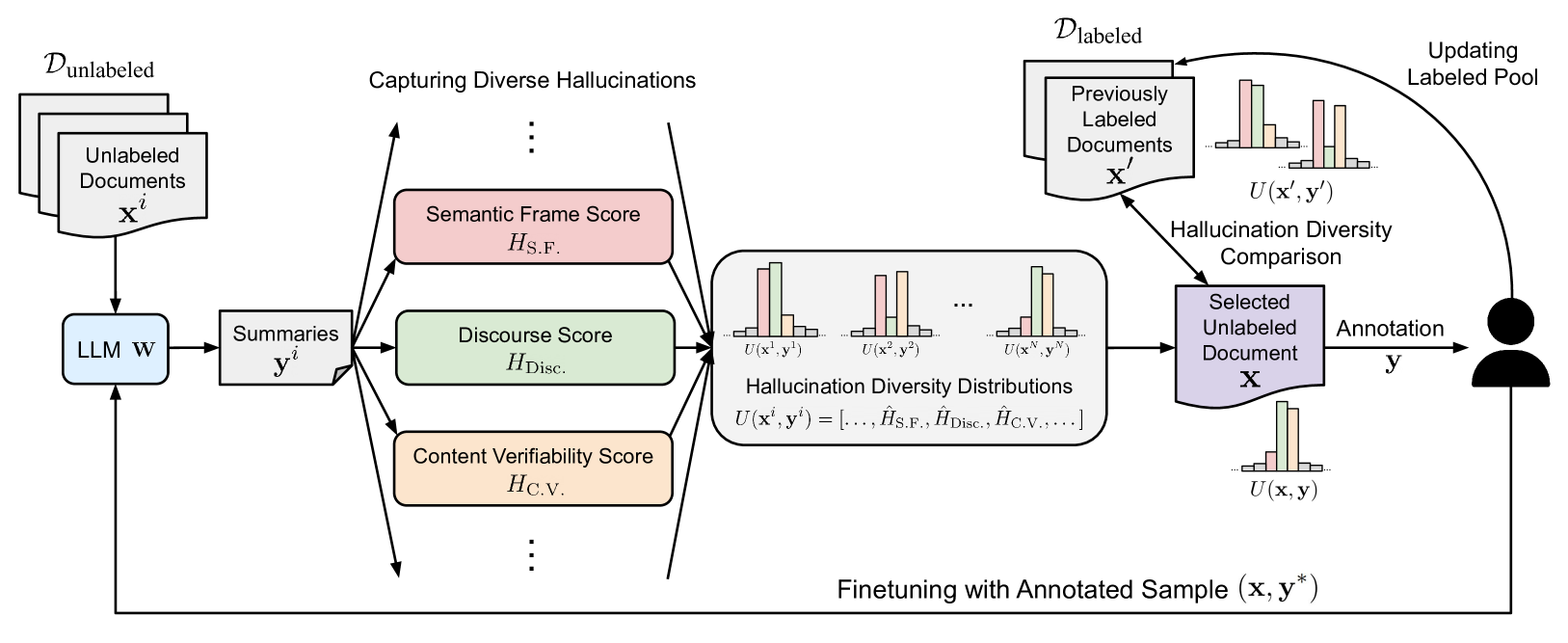
Large Language Models (LLMs) have shown propensity to generate hallucinated outputs, i.e., texts that are factually incorrect or unsupported. Existing methods for alleviating hallucinations typically require costly human annotations to identify and correct hallucinations in LLM outputs. Moreover, most of these methods focus on a specific type of hallucination, e.g., entity or token errors, which limits their effectiveness in addressing various types of hallucinations exhibited in LLM outputs. To our best knowledge, in this paper we propose the first active learning framework to alleviate LLM hallucinations, reducing costly human annotations of hallucination needed. By measuring fine-grained hallucinations from errors in semantic frame, discourse and content verifiability in text summarization, we propose HAllucination Diversity-Aware Sampling (HADAS) to select diverse hallucinations for annotations in active learning for LLM finetuning. Extensive experiments on three datasets and different backbone models demonstrate advantages of our method in effectively and efficiently mitigating LLM hallucinations.
4/3/2024